はじめに
とある用件で、Pysparkなるライブラリを知り、早速ながらその感覚を掴むために実践してみましたー!
ウェブマーケ、広告運用をやっていた時はHiveやHadoopなどのHDFSに格納された広告配信データをSQLで取得し、ExcelまたはTableauでガリガリ加工して分析していた経験があったので、
今回は、取得する側ではなく、データを用意して入れる側の気持ちになって、挑戦してみました◎
アーキテクチャ(ざっくり)


Dockerで、3つのコンテナを立ち上げる。
- sparkのマスター
- 純粋にSparkアプリケーションのリソース・マネージャーとして機能
- sparkのワーカー1
- sparkのワーカー2
- Sparkマスターに送信されたジョブの一部の実行を担当するエグゼキューターを起動
バージョン
- Python 3.7
- Apache Spark 3.0.1
- Apache Hadoop 3.2
- Docker 20.10.6
- docker-compose 1.29.1
ディレクトリ構成
.
├── build
│ ├── master
│ │ ├── Dockerfile
│ │ └── files
│ │ └── etc
│ │ └── spark-defaults.conf
│ └── worker
│ └── Dockerfile
├── data
│ └── bread_basket.csv
├── docker-compose.yaml
├── main.py
└── scripts
└── start.sh
Dockerアプリ起動方法
spark-challengeディレクトリで、dockerコンテナ起動
$ cd spark-challenge
$ docker-compose up -d
ソースコード
docker-compose.yaml
version: '3.3'
services:
spark-master:
build:
context: ./build/master/
dockerfile: Dockerfile
container_name: spark-master
ports:
- "8080:8080"
- "7077:7077"
- "4040:4040"
- "18080:18080"
volumes:
- ./:/app
environment:
- INIT_DAEMON_STEP=setup_spark
networks:
- ichi_spark_network
spark-worker-1:
build:
context: ./build/worker/
dockerfile: Dockerfile
container_name: spark-worker-1
tty: true
ports:
- "8081:8081"
volumes:
- ./:/app
environment:
- SPARK_MASTER=spark://spark-master:7077
networks:
- ichi_spark_network
spark-worker-2:
build:
context: ./build/worker/
dockerfile: Dockerfile
container_name: spark-worker-2
tty: true
ports:
- "8082:8081"
volumes:
- ./:/app
environment:
- SPARK_MASTER=spark://spark-master:7077
networks:
- ichi_spark_network
networks:
ichi_spark_network:
Dockerfile
master用
FROM bde2020/spark-master:3.0.1-hadoop3.2
WORKDIR /app
ENV LANG="ja_JP.utf8" \
LANGUAGE="ja_JP.utf8" \
LC_ALL="ja_JP.utf8"
RUN apk --update add coreutils
RUN apk add procps
RUN rm -f /usr/bin/python \
&& ln -s /usr/bin/python3.7 /usr/bin/python \
&& pip3 install --upgrade pip
RUN mkdir /tmp/spark-events
COPY files/etc /etc
RUN mv /etc/spark-defaults.conf /spark/conf
worker用
FROM bde2020/spark-master:3.0.1-hadoop3.2
WORKDIR /app
ENV LANG="ja_JP.utf8" \
LANGUAGE="ja_JP.utf8" \
LC_ALL="ja_JP.utf8"
RUN apk --update add coreutils
RUN apk add procps
※イメージは、こちらを使用しました =>bde2020/spark-master
main.py
from pyspark import SparkConf, SparkContext
from pyspark.sql import SparkSession
from pyspark.sql.types import *
from pyspark.sql.functions import *
# SparkContextインスタンスを生成。SparkConfに書いた設定値を渡す。
conf = SparkConf().setAppName("simpleApp").setMaster("spark://spark-master:7077")
sc = SparkContext(conf=conf)
# SparkSessionのビルダーを使い、SparkSessionインスタンスを生成
spark = SparkSession.builder.config(conf=sc.getConf()).getOrCreate()
# スキーマを指定
schema = StructType(
[
# At the 3rd variable, set nullable or not
StructField("Transaction", IntegerType(), True),
StructField("Item", StringType(), True),
StructField("date_time", StringType(), True),
StructField("period_day", StringType(), True),
StructField("weekday_weekend", StringType(), True)
]
)
# Set spark.sql.legacy.timeParserPolicy to LEGACY to restore the behavior before Spark 3.0.
# *Allow 'EEE MMM dd HH:mm:ss zzz yyyy' format pattern
spark.sql("set spark.sql.legacy.timeParserPolicy=LEGACY")
# データの読み込み
csv_path = "./data/bread_basket.csv"
csv_df = (
spark.read.option("header", True)
.option("mode", "PERMISSIVE")
.option("sep", r",")
.option("enforceSchema", False)
.schema(schema)
.csv(csv_path)
)
# データフレーム作成
# Convert date_time into timestamp type. add a column of format_date_time
df = csv_df.withColumn("format_date_time", to_timestamp(col("date_time"), "dd-MM-yy HH:mm"))
# テンプViewの作成
df.createOrReplaceTempView("BreadBasket")
df.printSchema()
# クエリの作成
query = f'''
SELECT
*
FROM
BreadBasket
WHERE
Item = 'Coffee'
AND
format_date_time BETWEEN '2016-11-01 00:00' AND '2016-12-01 00:00'
LIMIT 10
'''
# データフレームにクエリ実行結果をセット
df = spark.sql(query)
# データフレームの表示
df.show()
# spark.stop()
spark.stop()の説明
- SparkSessionインスタンスを生成すると、HTTPサーバーとしての機能が起動する。
- 終了するときはstopメソッドを呼び出す。
- stopすることで、各executorも終了する。
- このstopメソッドは、内部でSparkContextのstopを呼び出している。
補足情報
pyspark インストール
$ pip install pyspark # ver 3.1.2
Kaggleからデータセットのダウンロード
Group Byなんかもできる。
query = f'''
SELECT
Item,
COUNT(*) AS item_count
FROM
BreadBasket
GROUP BY
Item
ORDER BY
item_count DESC
'''
df.groupBy("Item").count().sort("count", ascending=False).show()
マスターノードとワーカーノードを立ち上げる
$ cd spark-challenge
$ sh ./scripts/start.sh
start.sh中身
# !/bin/bash
docker exec -d spark-master /spark/sbin/start-history-server.sh
docker exec -d spark-worker-1 /spark/sbin/start-slave.sh spark://spark-master:7077
docker exec -d spark-worker-2 /spark/sbin/start-slave.sh spark://spark-master:7077
Masterのコンテナに入りmain.pyの実行
$ docker exec -it spark-master bash
$ /spark/bin/spark-submit /app/main.py
http://localhost:8080/にアクセス!!
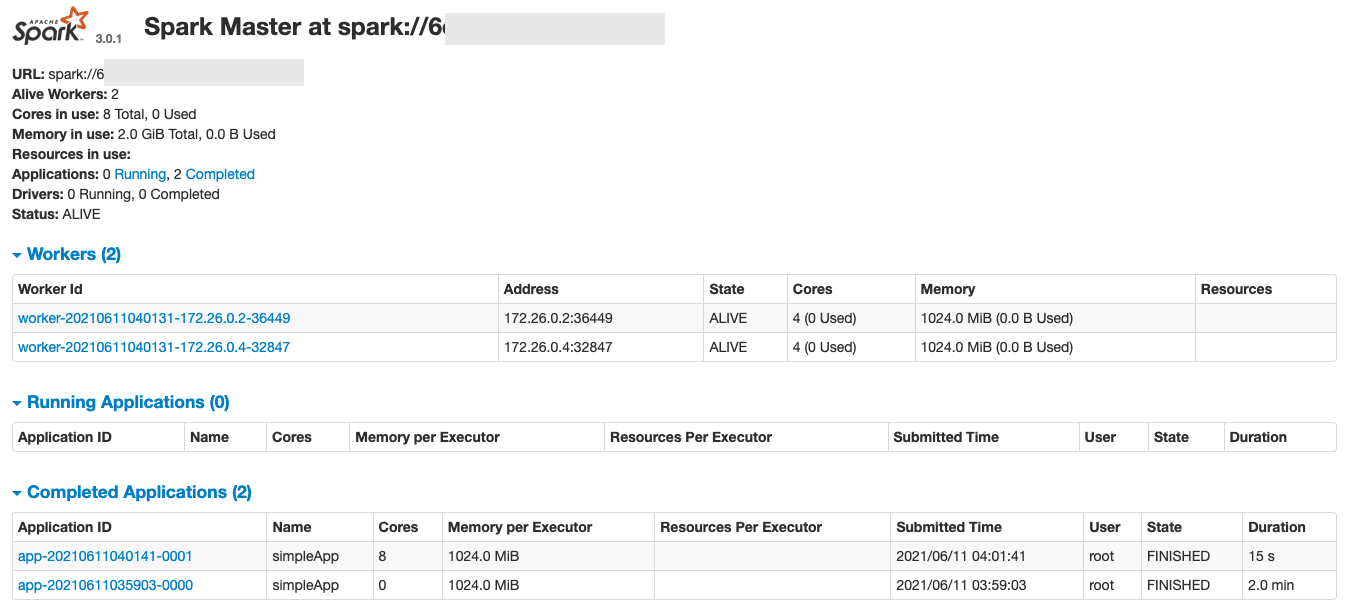
おおお〜GUI見れましたね!!
ワーカーさんが二人、
完了タスクが2つ みたいになってますな。
http://localhost:18080/にアクセス!!
ポートが18080です!w 紛らわしいですね!w
ヒストリーサーバーも立ち上がっているので、実行履歴の確認が可能です。

※実行履歴画面があることに後で気づいたので、後付けのキャプチャになります。上記では2件のアプリ実行なのに、こっちでは1件となっていて齟齬があります汗 あまり気にしないでください〜🙇♀️
SparkがMesosあるいはYARN上で実行されている場合でも、アプリケーションのイベントログが存在するならSparkの履歴サーバを使って終了したアプリケーションのUIを構築することが可能です。以下を実行することで履歴サーバを開始することができます:
./sbin/start-history-server.sh
これはデフォルトで http://:18080 にwebインタフェースを生成し、未完了あるいは完了済みのアプリケーションと試行をリスト化します。
参照元:監視および計測器
df.printSchema()の実行結果
root
|-- Transaction: integer (nullable = true)
|-- Item: string (nullable = true)
|-- date_time: string (nullable = true)
|-- period_day: string (nullable = true)
|-- weekday_weekend: string (nullable = true)
|-- format_date_time: timestamp (nullable = true)
df.show()の実行結果
+-----------+------+----------------+----------+---------------+-------------------+
|Transaction| Item| date_time|period_day|weekday_weekend| format_date_time|
+-----------+------+----------------+----------+---------------+-------------------+
| 178|Coffee|01-11-2016 07:51| morning| weekday|2016-11-01 07:51:00|
| 179|Coffee|01-11-2016 08:20| morning| weekday|2016-11-01 08:20:00|
| 188|Coffee|01-11-2016 10:04| morning| weekday|2016-11-01 10:04:00|
| 189|Coffee|01-11-2016 10:29| morning| weekday|2016-11-01 10:29:00|
| 190|Coffee|01-11-2016 10:34| morning| weekday|2016-11-01 10:34:00|
| 193|Coffee|01-11-2016 11:00| morning| weekday|2016-11-01 11:00:00|
| 197|Coffee|01-11-2016 11:10| morning| weekday|2016-11-01 11:10:00|
| 197|Coffee|01-11-2016 11:10| morning| weekday|2016-11-01 11:10:00|
| 198|Coffee|01-11-2016 11:11| morning| weekday|2016-11-01 11:11:00|
| 199|Coffee|01-11-2016 11:13| morning| weekday|2016-11-01 11:13:00|
+-----------+------+----------------+----------+---------------+-------------------+
やりましたね!ちゃんとcsvのデータセットが反映されて、無事クエリ結果が返ってきました!
ハマったポイント
- kaggleから落としてきたcsvファイルの名前が、
bread basket.csvとなっていて、アンダースコアがなくて、ファイル読み込みで死んだ。うそやんw - Dockerfileの
ln -s /usr/bin/python3.7 /usr/bin/pythonのコマンドところ- コンテナ入ってみたら、pythonのversionが
3.7になっていて、3.9とかに勝手に変えてしまったら、そんなファイルないよって怒られた- ちゃんとそのイメージの中(今回で言うと
bde2020/spark-master:3.0.1-hadoop3.2こやつ。)に何が含まれているか確認しないとダメですね
- ちゃんとそのイメージの中(今回で言うと
- コンテナ入ってみたら、pythonのversionが
-
yamlの拡張子は、ymlでもいいらしい。違いは3文字か4文字のどちらで表記するかだけ
まとめと感想
apache sparkを初めて触って、Pysparkライブラリを使って色々いじる感じとその感覚が養えました!
もっともっとデータの処理であったり詳細の部分をこれから詰められればと思っています。
実務で経験積んでみたいな〜〜(´-`).。oO
Python面白すぎてワクワクが止まりません〜🤩✨
以上、ありがとうございました!