昨年末にリリースされたsagemakerは、(1)機械学習のモデルの構築 (2)トレーニング そして嬉しいことに (3)デプロイまでを手っ取り早くスケーラブルに実現できるフルマネージドなサービスです。
特に、機械学習のモデルを本番環境にデプロイすることは、非エンジニアのデータ解析者にとっては大変な作業です。なので、もしそこが解決されるならぜひ使いたいところではあります。
・・・とはいえ。
2018年2月現在、sagemakerはまだ東京リージョンに対応していなかったり、httpsプロトコル以外は積極的に対応していなかったりという状況です。なので**「デプロイは簡単に見えるけど、速度面や性能面で本番投入に耐えうるのかな...?」**ということが気になりました。
そこで、(デフォルトの設定1でデプロイした)**「sagemakerのエンドポイントは、どの程度の負荷まで耐えられるか?」**ということをlocustという負荷試験ツールを使って検証してみました。リコメンドのようなリアルタイム性の求められるML系サービスをさくっと展開したい人は参考になるかも。
sagemakerの準備
- モデルの構築とトレーニング
- sagemakerでJupyter Notebookを立ち上げたときにデフォルトで入っている、決定木を用いたアヤメの分類問題 をただ動かしただけ。
- デプロイ
- これも上のjupyter notebookで
tree.deployと書くだけ。インスタンスはml.m4.xlargeを1台指定。これでエンドポイントが作られる。 - 一応裏方のサーバの仕組みとしてはこんな感じになっている模様(下図)。flaskからのresponseに応じて分類の結果(推定されたアヤメの種類)が返却される。
- これも上のjupyter notebookで
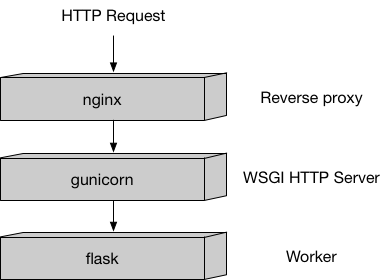
- エンドポイントの呼び方
- ローカルからこんな感じで呼びます。
prediction-from-local.py
import boto3
import sagemaker
import numpy as np
from boto3 import Session
from sagemaker.predictor import csv_serializer
# session設定
# *awsのcredentialにprofile情報は事前に書いておく
profile = 'sm'
boto_session = Session(profile_name=profile)
tree_sm_session = sagemaker.Session(boto_session = boto_session)
# endpointの設定
tree_endpoint = '<自分のsagemakerのendpoint name>'
# 予測に用いるクラスの初期化
predictor = sagemaker.predictor.RealTimePredictor(
sagemaker_session = tree_sm_session,
endpoint = tree_endpoint,
serializer = csv_serializer)
# 予測
data = np.random.rand(4)*10 # アヤメの属性を適当に生成
predictor.predict(data).strip()
# 結果
>> 10回平均で0.24秒くらいのresponse
このケースだと0.24秒で返ってくるので早いのですが、負荷が集中した時にこれがどれくらい変わるかをlocustで調べてみます。
locustの準備
- locustとは?
- 負荷試験用のpythonツールです。locustは「イナゴ」という意味で、群れでアクセスする様子を表しているそう。分散処理してアクセスしてくれます。
- 使い方
- 下記の記事とかをご参照ください。
- はじめてのAPIサーバー負荷試験で得た最低限の負荷試験知識
- Locust入門記事の次に読む記事
- 利用したコード
- 単純なhttpリクエストはlocustで簡単に書けるのですが、sagemakerのendpiontをlocustで叩けるようにするためには少し工夫が必要でした。下記に実際に使用したコードを挙げておきます。2
- 実際に使ったlocust file (github)
結果
10ユーザが大体1秒おきにアクセスした時の場合
レスポンス速度は200~250[ms]、RPS(request/seqc)は7.9くらいをさばいています。3
(中段の単位は[ms])

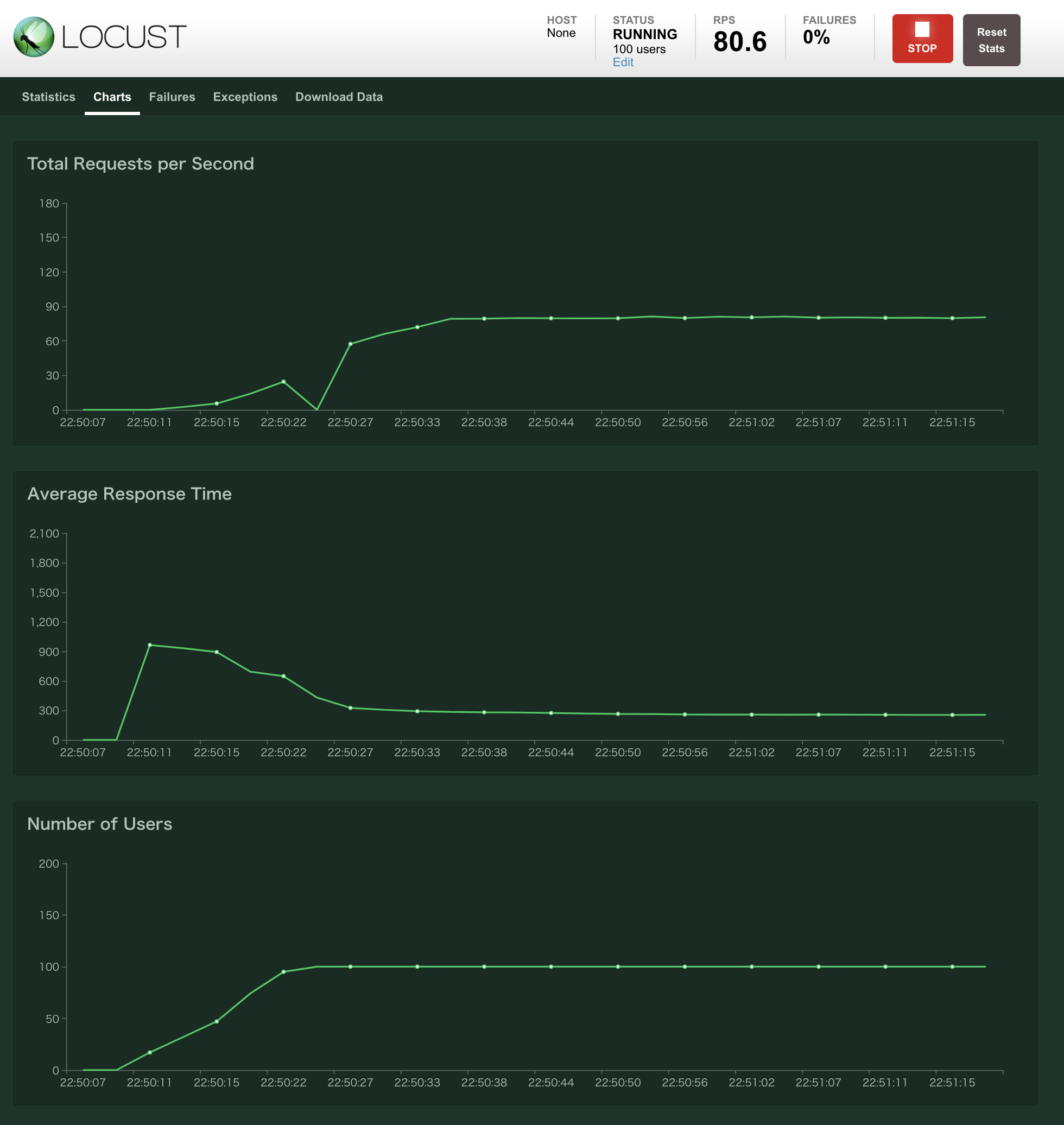
100ユーザにした場合
これでもまだ安定しています。250[ms]くらい。
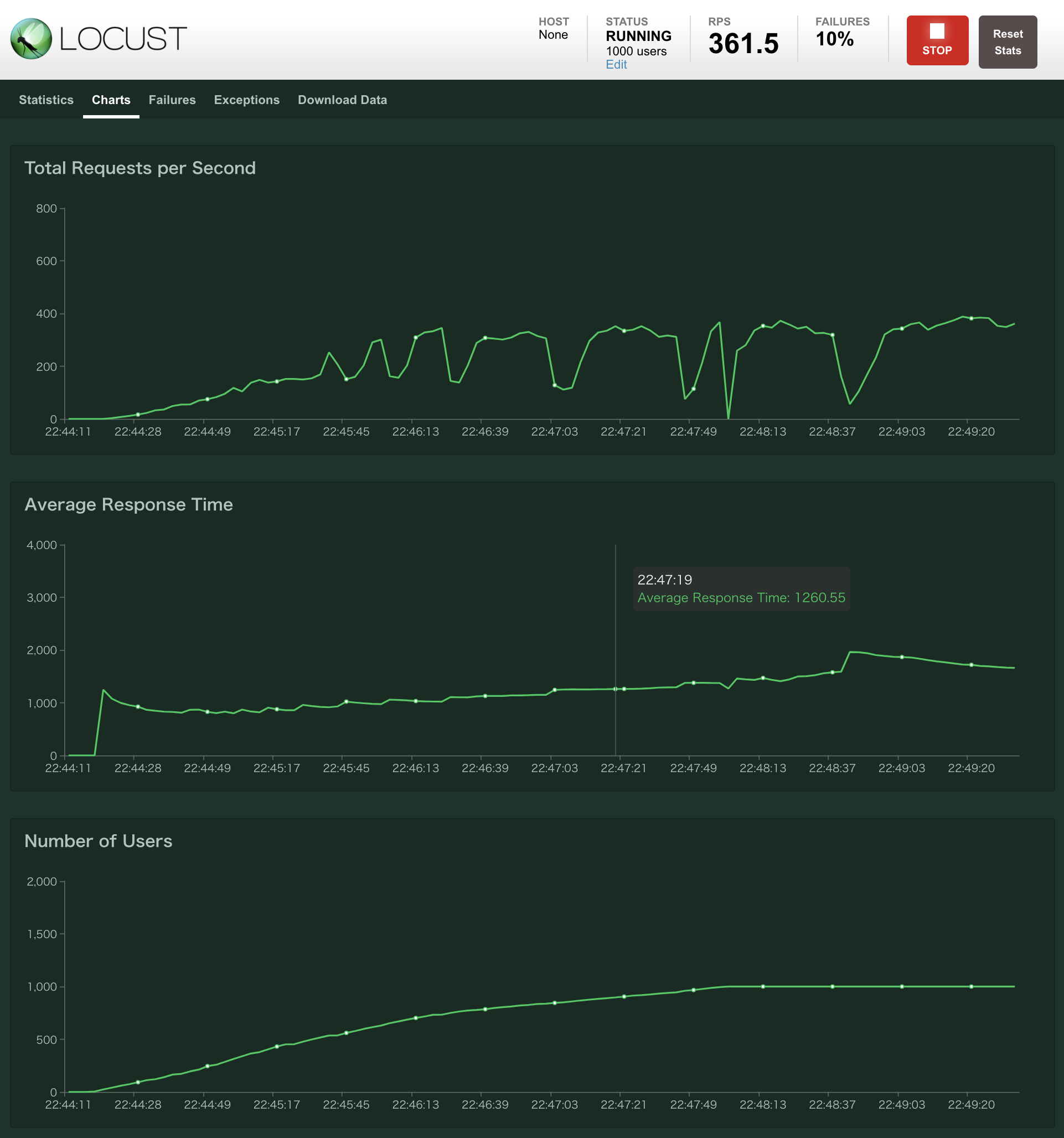
1,000ユーザにした場合
性能が大幅にぶれて、返却速度も2秒にいくことも。
まとめ
- sagemakerのサンプルにある決定木の問題をデフォルト設定(ml.m4.xlargeを1台)のまま動かした。
- 100ユーザくらいまでは耐えられた(返却時間0.3秒くらい)が、500ユーザを超えたあたりで大幅な性能劣化が見られた(2秒超えも)。
- CPU/メモリ使用量などを見て、余裕を持った台数構成を指定しましょう。
感想
- スコアリングだけなら、デフォルト設定でも速度&性能的に使えそうかも。
追記
- gunicornの基本的な挙動についてまとめました。
- https://qiita.com/iceman-k/items/86d54b07defa47fd35a9