preg_replace
preg_replace(検索パターン,変更後の文字列,検索・置換対象)
$test = 'helloworld';
echo preg_replace('/hello/', 'world', $test);
echo $test;
worldworldhelloworld
$a = 'applebananastrawbelly';
echo 'fruits→',preg_replace('/apple/', '', $a);
fruits→bananastrawbelly
検索パターンが2つの場合
preg_replace(検索パターン1|検索パターン2,変更後の文字列,検索・置換対象)
$a = 'applebananastrawbellygrape';
echo 'fruits→',preg_replace('/apple|strawbelly/', '', $a);
fruits→bananagrape
$member=<<<_DATA_
<pre>
Name Addr Sex
-------------------------
Ito Tokyo man
Sato Saitama woman
Tanaka Kanagawa man
Uchida Chiba woman
</pre>
_DATA_;
print preg_replace('/man|woman/', '[Secret]', $member);
Name Addr Sex
-------------------------
Ito Tokyo [Secret]
Sato Saitama [Secret]
Tanaka Kanagawa [Secret]
Uchida Chiba [Secret]
<<<→ヒアドキュメント
**<<<** → ヒアドキュメント
PHPにおける「<<<」は
ヒアドキュメントといいます。
PHPのプログラムの中にHTMLを埋め込んだりするときには重宝するでしょう。
<<<に続くID(終端子)が出現するまでを一括りの文字列として管理します。
似たような構文としてNowDocがありますのでIDの設定にはきをつけてください。
<<<TEST
文字
TEST;
TESTの部分の名前は自由
preg_match
| ^ | 行頭 |
| [0-9] | 0から9までの数字1文字 |
| {7} | 直前の文字が7文字続く |
| $ | 行末 |
■/正規表現パターン/
**/~/**で囲む。
文字列がカタカナとスペースのみであるかどうかを判定する関数
if (! preg_match ("/^[ァ-ヶー\s]+$/u", $_POST ['kanaIndicating'] ) && ! strlen ( $_POST ['kanaIndicating'] ) == 0) {
$err ['kanaIndicating'] = 'カタカナで入力してください。';
}
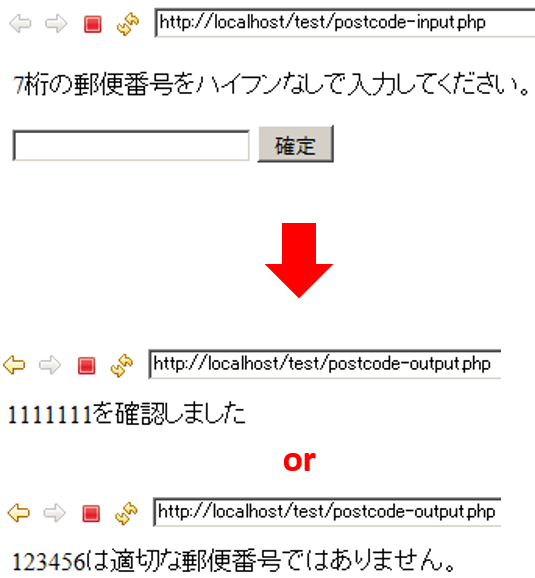
郵便番号正規表現
<p>7桁の郵便番号をハイフンなしで入力してください。</p>
<form action="postcode-output.php" method="post">
<input type="text" name="postcode">
<input type="submit" value="確定">
</form>
<?php
$postcode = $_POST['postcode'];
if(preg_match('/^[0-9]{7}$/', $postcode) & !($postcode == null)){
echo $postcode,'を確認しました';
}else{
echo $postcode,'は適切な郵便番号ではありません。';
}
?>
いずれかの文字にマッチ
<form action="word-output.php" method="post">
<input type="text" name="word">
<input type="submit" value="確定">
</form>
ABCのいずれかの文字にマッチ
<?php
$word = $_POST['word'];
if(preg_match('/[ABC]/', $word)){
echo 'ok';
}else{
echo 'NG';
}
?>
いずれかの文字にマッチしない
preg_match('/[^ABC]/', $word)
/a[cde]/
ac adv ae kadf→ok
aの次の文字がcかdかeが含まれている文字列はok
preg_match('/a[cde]/', $word)
全て数字
行頭から行末まで全て数字ならマッチ
preg_match('/^[0-9]$/', $word)
行頭だけ数字
preg_match('/^[0-9]/', $word)
行末だけ数字
preg_match('/[0-9]$/', $word)
半角全角数字にマッチ(正)
preg_match('/^[0-90-9]+$/u', $word)
preg_match('/^[0-90-9]$/u', $word)
半角全角数字にマッチ(誤)
preg_match('/^.*[0-90-9]$/', $word)
preg_match('/^.*[0-90-9]$/u', $word)
/p.n/
preg_match('/p.n/', $word)
pen pan pin → ok
piiiin → NG
数字が含まれていればマッチ
preg_match('/[0-9]/', $word)
500yen → ok
a → NG
アルファベットが含まれていればマッチ
preg_match('/[a-e]/', $word)
X{n}→n文字のX
n文字のX
preg_match('/e{2}/', $word)
X{m,n}→m~n文字のX
preg_match('/^we{1,2}k$/', $word)
week wek weeek → ok
sweek → NG
X{n,}→n文字以上のX
preg_match('/we{1,}k/', $word)
wek week aweek → ok
wk → NG
X+→1文字以上のX
preg_match('/^a+$/', $word)
aaa aa a → ok
preg_match('/wo+d/', $word)
wod wood → ok
wd oo → NG
a|b → a又はb
Girl又はBとyの間に任意の1文字を含む文字列。
preg_match('/Girl|B.y/', $word)
Girl qqBoytr → ok
By → NG
[^amr] → amrの文字にマッチしない
preg_match('/^we[^amr]k$/', $word)
weqk week → ok
wek weka weak → NG
\d → 数値にマッチ
preg_match('/\d/', $word)
1a 1 → ok
a → NG
\D → 数値以外にマッチ
preg_match('/\D/', $word)
a → ok
1 → NG
X?→ 0又は1文字のX
preg_match('/we?k/', $word)
wek wk→ ok
week a weeek→ NG
X → 0文字以上のX*
preg_match('/we*k/', $word)
wk wek week → ok
k → NG
\W → 文字以外にマッチ
preg_match('/w\Wk/', $word)
w?k w$k → ok
wk wek w1k → NG
\w → 大文字/小文字のアルファベット、数値、アンダースコアにマッチ
[a-zA-Z_0-9]と同じ
preg_match('/\w/', $word)
1(小文字) a _ → ok
あ 1(大文字) # → NG
[a-zA-Z_0-9]
preg_match('/[a-zA-Z_0-9]/', $word)
1(小文字) a _ → ok
あ 1(大文字) # → NG
- → ハイフンを指定する時はバックスラッシュ
preg_match('/w[\-]k/', $word)
w-k → ok
wk wak → NG
[a-z] → 小文字英字にマッチ
preg_match('/w[a-z]k/', $word)
wak → ok
wAk wk w1k → NG
[^a-z] →小文字英字以外にマッチ
preg_match('/[^a-z]/', $word)
1 → ok
a → NG
[A-Z] → 大文字英字にマッチ
preg_match('/[A-Z]/', $word)
A → ok
a → NG
/[a-z]-\d{3}/
preg_match('/[a-z]-\d{3}/', $word)
/[a-z]-\d{3}/でもよい。
a-111 → ok
a111 a-11 W-1→ NG