ReactでJavaScriptを用いてWord文書からテキストを抽出することで、Webアプリケーションのインタラクティブ性と効率を大幅に向上させることができます。特に、大量の文書を処理する必要がある場合や、コンテンツ分析を自動化するアプリケーションにおいて効果的です。この技術を使用すれば、ユーザーはWordファイルを直接アップロードでき、他の形式に変換する手間が省けるため、操作が簡略化され、ユーザー体験が向上します。また、開発者は文書データに即座にアクセスして操作できるため、動的な要約生成、キーワード抽出、コンテンツフィルタリングなどの機能を実現できます。
この記事では、ReactでJavaScriptを使用してWord文書のテキストを抽出する方法を紹介します。
本文で使用する方法は、Spire.Doc for JavaScriptを利用します。インストールコマンドは以下のとおりです:
npm i spire.doc
Word文書全体のテキストを抽出する
Document.GetText()メソッドを使用することで、ロードしたWord文書全体のテキストを直接取得できます。以下に手順を示します:
-
Spire.Doc.Base.jsファイルをロードし、WebAssemblyモジュールを初期化します。 -
wasmModule.FetchFileToVFS()メソッドを使用して、Wordファイルを仮想ファイルシステムにロードします。 -
wasmModule.Document.Create()メソッドを使ってDocumentインスタンスを作成します。 -
Document.LoadFromFile()メソッドで、Word文書をDocumentインスタンスにロードします。 -
Document.GetText()メソッドを使って文書全体のテキストを文字列として取得します。
コード例
import React, { useState, useEffect } from 'react';
function App() {
const [wasmModule, setWasmModule] = useState(null);
const [loadingError, setLoadingError] = useState(null);
useEffect(() => {
let script;
// 非同期操作を処理する即時実行関数 (IIFE)
(async () => {
try {
// WASMモジュールの初期化が完了した際に解決されるPromiseを作成
const wasmInitialized = new Promise((resolve, reject) => {
window.Module = {
onRuntimeInitialized: () => resolve(window.spiredoc),
onError: (error) => reject(error)
};
});
// WASM JavaScriptファイルを読み込むためのスクリプト要素を作成
script = document.createElement('script');
script.src = `${process.env.PUBLIC_URL}/Spire.Doc.Base.js`;
script.async = true; // スクリプトを非同期で読み込むように指定
// スクリプトをドキュメントのbodyに追加し、読み込みを待機
document.body.appendChild(script);
await wasmInitialized;
// ランタイムが初期化されたときにwasmModuleの状態を設定
setWasmModule(window.spiredoc);
} catch (err) {
console.error('WASMモジュールの読み込みに失敗しました:', err);
setLoadingError(err);
}
})();
// コンポーネントがアンマウントされた際にスクリプトを削除するクリーンアップ関数
return () => {
if (script && script.parentNode) {
script.parentNode.removeChild(script);
}
delete window.Module;
};
}, []);
// Wordドキュメントから全てのテキストを抽出する関数
const ExtractAllTextFromWord = async () => {
if (!wasmModule) return;
try {
// 入力ファイル名と出力ファイル名を定義
const inputFileName = 'Sample.docx';
const outputFileName = 'ExtractWordText.txt';
// 仮想ファイルシステムに入力ファイルをフェッチ
await wasmModule.FetchFileToVFS(inputFileName, '', `${process.env.PUBLIC_URL}/`);
// 新しいDocumentインスタンスを作成し、入力ファイルをロード
const doc = wasmModule.Document.Create();
doc.LoadFromFile({ fileName: inputFileName });
// ドキュメントから全てのテキストを抽出
const documentText = doc.GetText();
doc.Dispose();
// 抽出したテキストからBlobを作成し、ダウンロードリンクを生成
const blob = new Blob([documentText], { type: 'text/plain' });
const url = URL.createObjectURL(blob);
const a = document.createElement("a");
a.href = url;
a.download = outputFileName;
a.style.display = "none"; // リンクを非表示に設定
document.body.appendChild(a);
a.click();
window.URL.revokeObjectURL(url);
document.body.removeChild(a);
} catch (error) {
console.error('ドキュメントの処理中にエラーが発生しました:', error);
}
};
if (loadingError) {
return <div>WASMモジュールの読み込みエラー</div>;
}
return (
<div style={{ textAlign: 'center', height: '300px' }}>
<h1>Reactを使用したJavaScriptでのWordドキュメントからの全テキスト抽出</h1>
<button onClick={ExtractAllTextFromWord} disabled={!wasmModule}>
抽出してダウンロード
</button>
</div>
);
}
export default App;
結果

特定の段落またはセクションのテキストを抽出する
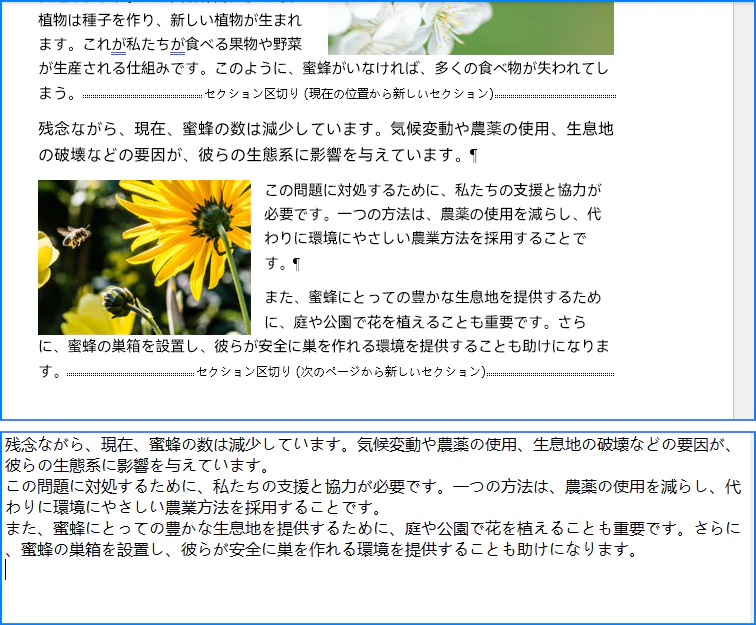
特定の段落またはセクションのテキストを抽出する場合、Document.Sections.get_Item()メソッドを使用して特定のセクションを取得します。その後、セクション内の段落を順に処理するか、Section.Paragraphs.get_Item().Textプロパティを使用して、セクション全体または特定の段落のテキストを取得できます。以下に手順を示します:
-
Spire.Doc.Base.jsファイルをロードし、WebAssemblyモジュールを初期化します。 -
wasmModule.FetchFileToVFS()メソッドでWordファイルを仮想ファイルシステムにロードします。 -
wasmModule.Document.Create()メソッドでDocumentインスタンスを作成します。 -
Document.LoadFromFile()メソッドを使ってWord文書をロードします。 -
Document.Sections.get_Item()メソッドで特定のセクションを取得します。 -
Section.Paragraphs.get_Item().Textプロパティを利用して段落のテキストを抽出します。 - セクション内のすべての段落を処理する場合は、ループで各段落を取得します。
コード例
import React, { useState, useEffect } from 'react';
function App() {
// 2つの状態を定義: `wasmModule` は WebAssembly モジュールを格納するためのもの、`loadingError` は読み込みエラーをキャッチするためのもの
const [wasmModule, setWasmModule] = useState(null);
const [loadingError, setLoadingError] = useState(null);
useEffect(() => {
let script;
// 即時実行関数 (IIFE) を使用して非同期操作を処理
(async () => {
try {
// WebAssembly モジュールの初期化が完了したときに解決される Promise を作成
const wasmInitialized = new Promise((resolve, reject) => {
window.Module = {
onRuntimeInitialized: () => resolve(window.spiredoc), // 成功時に `window.spiredoc` を解決
onError: (error) => reject(error) // エラー発生時に拒否
};
});
// WebAssembly の JavaScript ファイルを読み込むための script 要素を作成
script = document.createElement('script');
script.src = `${process.env.PUBLIC_URL}/Spire.Doc.Base.js`;
script.async = true; // スクリプトを非同期で読み込むように指定
// script をドキュメントの body に追加し、読み込み完了を待機
document.body.appendChild(script);
await wasmInitialized;
// WebAssembly が初期化されたら `wasmModule` 状態にモジュールを設定
setWasmModule(window.spiredoc);
} catch (err) {
console.error('WebAssembly モジュールの読み込みに失敗しました:', err);
setLoadingError(err); // エラーをキャッチして状態に保存
}
})();
// クリーンアップ関数: コンポーネントがアンマウントされた際に script を削除
return () => {
if (script && script.parentNode) {
script.parentNode.removeChild(script);
}
delete window.Module; // グローバル Module オブジェクトを削除
};
}, []);
// Word ドキュメントからすべてのテキストを抽出する
const ExtractTextWordSectionParagraph = async () => {
if (!wasmModule) return; // モジュールがロードされていなければ終了
try {
// 入力ファイル名と出力ファイル名を定義
const inputFileName = 'Sample.docx';
const outputFileName = 'ExtractWordText.txt';
// 入力ファイルを仮想ファイルシステム (VFS) にロード
await wasmModule.FetchFileToVFS(inputFileName, '', `${process.env.PUBLIC_URL}/`);
// 新しい Document インスタンスを作成し、入力ファイルをロード
const doc = wasmModule.Document.Create();
doc.LoadFromFile({ fileName: inputFileName });
// ドキュメントからセクションを取得
const section = doc.Sections.get_Item(1);
// セクション内の段落からすべてのテキストを取得
let sectionText = '';
for (let i = 0; i < section.Paragraphs.Count; i++) {
sectionText += (section.Paragraphs.get_Item(i).Text + '\n');
}
doc.Dispose(); // リソースを解放
// 抽出したテキストを格納する Blob を作成し、ダウンロードリンクを生成
const blob = new Blob([sectionText], { type: 'text/plain' });
const url = URL.createObjectURL(blob);
const a = document.createElement("a");
a.href = url;
a.download = outputFileName;
a.style.display = "none"; // リンクを非表示に設定
document.body.appendChild(a);
a.click(); // ダウンロードをトリガー
window.URL.revokeObjectURL(url); // URL オブジェクトを解放
document.body.removeChild(a);
} catch (error) {
console.error('ドキュメント処理中にエラーが発生しました:', error);
}
};
// WebAssembly モジュールの読み込み時にエラーが発生した場合、エラーメッセージを表示
if (loadingError) {
return <div>WebAssembly モジュールの読み込み中にエラーが発生しました</div>;
}
// UI をレンダリング
return (
<div style={{ textAlign: 'center', height: '300px' }}>
<h1>React と JavaScript を使用した Word ドキュメントのテキスト抽出</h1>
<button onClick={ExtractTextWordSectionParagraph} disabled={!wasmModule}>
抽出してダウンロード
</button>
</div>
);
}
export default App;
結果
特定のスタイルが適用された段落のテキストを抽出する
Paragraph.StyleNameプロパティを使用して、Word文書内の段落に適用されているスタイル名を取得できます。特定のスタイル名を定義し、文書内のすべての段落を順にチェックすることで、スタイル名が一致する段落のテキストを抽出できます。以下に手順を示します:
-
Spire.Doc.Base.jsファイルをロードし、WebAssemblyモジュールを初期化します。 -
wasmModule.FetchFileToVFS()メソッドを使用して、Wordファイルを仮想ファイルシステムにロードします。 -
wasmModule.Document.Create()メソッドでWebAssemblyモジュール内にDocumentインスタンスを作成します。 -
Document.LoadFromFile()メソッドを使ってWord文書をロードします。 - ターゲットスタイル名を定義するか、文書内のスタイル名を取得します。
- 文書内のセクションおよび段落を順に処理し:
- 各段落の
Paragraph.StyleNameプロパティでスタイル名を確認します。 - ターゲットスタイル名と一致する場合、
Paragraph.Textプロパティで段落のテキストを取得します。
- 各段落の
コード例
import React, { useState, useEffect } from 'react';
function App() {
// 2つの状態を定義: `wasmModule` は WebAssembly モジュールを格納するためのもの、`loadingError` は読み込みエラーをキャッチするためのもの
const [wasmModule, setWasmModule] = useState(null);
const [loadingError, setLoadingError] = useState(null);
useEffect(() => {
let script;
// 即時実行関数 (IIFE) を使用して非同期操作を処理
(async () => {
try {
// WebAssembly モジュールの初期化が完了したときに解決される Promise を作成
const wasmInitialized = new Promise((resolve, reject) => {
window.Module = {
onRuntimeInitialized: () => resolve(window.spiredoc), // 成功時に `window.spiredoc` を解決
onError: (error) => reject(error) // エラー発生時に拒否
};
});
// WebAssembly の JavaScript ファイルを読み込むための script 要素を作成
script = document.createElement('script');
script.src = `${process.env.PUBLIC_URL}/Spire.Doc.Base.js`;
script.async = true; // スクリプトを非同期で読み込むように指定
// script をドキュメントの body に追加し、読み込み完了を待機
document.body.appendChild(script);
await wasmInitialized;
// WebAssembly が初期化されたら `wasmModule` 状態にモジュールを設定
setWasmModule(window.spiredoc);
} catch (err) {
console.error('WebAssembly モジュールの読み込みに失敗しました:', err);
setLoadingError(err); // エラーをキャッチして状態に保存
}
})();
// クリーンアップ関数: コンポーネントがアンマウントされた際に script を削除
return () => {
if (script && script.parentNode) {
script.parentNode.removeChild(script);
}
delete window.Module; // グローバル Module オブジェクトを削除
};
}, []);
// Word ドキュメントから特定のスタイルの段落を抽出する
const ExtractTextWordParagraphStyle = async () => {
if (!wasmModule) return; // モジュールがロードされていなければ終了
try {
// 入力ファイル名と出力ファイル名を定義
const inputFileName = 'Sample9.docx';
const outputFileName = 'ExtractWordText.txt';
// 入力ファイルを仮想ファイルシステム (VFS) にロード
await wasmModule.FetchFileToVFS(inputFileName, '', `${process.env.PUBLIC_URL}/`);
// 新しい Document インスタンスを作成し、入力ファイルをロード
const doc = wasmModule.Document.Create();
doc.LoadFromFile({ fileName: inputFileName });
// 段落スタイル名を定義または文書から取得
const paragraphStyleName = 'Heading2';
// const paragraphStyleName = doc.Sections.get_Item(1).Paragraphs.get_Item(0).StyleName;
// 文書内のセクションと段落を反復処理
let documentText = '';
for (let i = 0; i < doc.Sections.Count; i++) {
const section = doc.Sections.get_Item(i);
for (let j = 0; j < section.Paragraphs.Count; j++) {
const paragraph = section.Paragraphs.get_Item(j);
if (paragraph.StyleName === paragraphStyleName) {
// スタイルが一致する段落のテキストを取得
documentText += paragraph.Text + '\n';
}
}
}
doc.Dispose(); // リソースを解放
// 抽出したテキストを格納する Blob を作成し、ダウンロードリンクを生成
const blob = new Blob([documentText], { type: 'text/plain' });
const url = URL.createObjectURL(blob);
const a = document.createElement("a");
a.href = url;
a.download = outputFileName;
a.style.display = "none"; // リンクを非表示に設定
document.body.appendChild(a);
a.click(); // ダウンロードをトリガー
window.URL.revokeObjectURL(url); // URL オブジェクトを解放
document.body.removeChild(a);
} catch (error) {
console.error('ドキュメント処理中にエラーが発生しました:', error);
}
};
// WebAssembly モジュールの読み込み時にエラーが発生した場合、エラーメッセージを表示
if (loadingError) {
return <div>WebAssembly モジュールの読み込み中にエラーが発生しました</div>;
}
// UI をレンダリング
return (
<div style={{ textAlign: 'center', height: '300px' }}>
<h1>React と JavaScript を使用した Word ドキュメントのテキスト抽出</h1>
<button onClick={ExtractTextWordParagraphStyle} disabled={!wasmModule}>
抽出してダウンロード
</button>
</div>
);
}
export default App;
結果
この記事では、JavaScriptを使用してReactアプリケーション内でWord文書のテキストを抽出する方法を解説しました。全体のテキスト、特定の部分、そして特定スタイルのテキストの抽出方法について具体的な手順とコード例を示しています。