ハイパーリンクは、Word文書、Webサイト、PDF文書などで広く使われている。ハイパーリンクを1回クリックするだけで、ユーザーは読んでいるページの他の場所や、文書やサイトの外部に移動することができます。特に、多くのページを含むPDF文書では、読者が必要なコンテンツを見つけやすくするためにハイパーリンクを作成することをお勧めします。しかし、インターネットからダウンロードした文書にハイパーリンクがあるなど、ハイパーリンクが迷惑な場合もあり、文書が読みづらくなることがあります。この記事では、無料のFree Spire.PDF for Javaを使用して、PDF文書内のハイパーリンクを挿入、更新、または削除する方法を紹介します。
【依存関係の追加】
この方法は、無料のFree Spire.PDF for Javaが必要ですので、先にjarファイルをインポートしてください。
1. Maven
Maven を使用している場合、プロジェクトの pom.xml ファイルに以下のコードを追加することで、簡単にアプリケーションに JAR ファイルをインポートすることができます。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf.free</artifactId>
<version>5.1.0</version>
</dependency>
</dependencies>
2. 公式サイトよりJarファイルをダウンロード
まず、Free Spire.PDF for Javaの公式サイトよりzipファイルをダウンロードします。zipファイルを解凍し、libフォルダの下にあるSpire.Pdf.jarファイルを依存関係としてプロジェクトにインポートしてください。
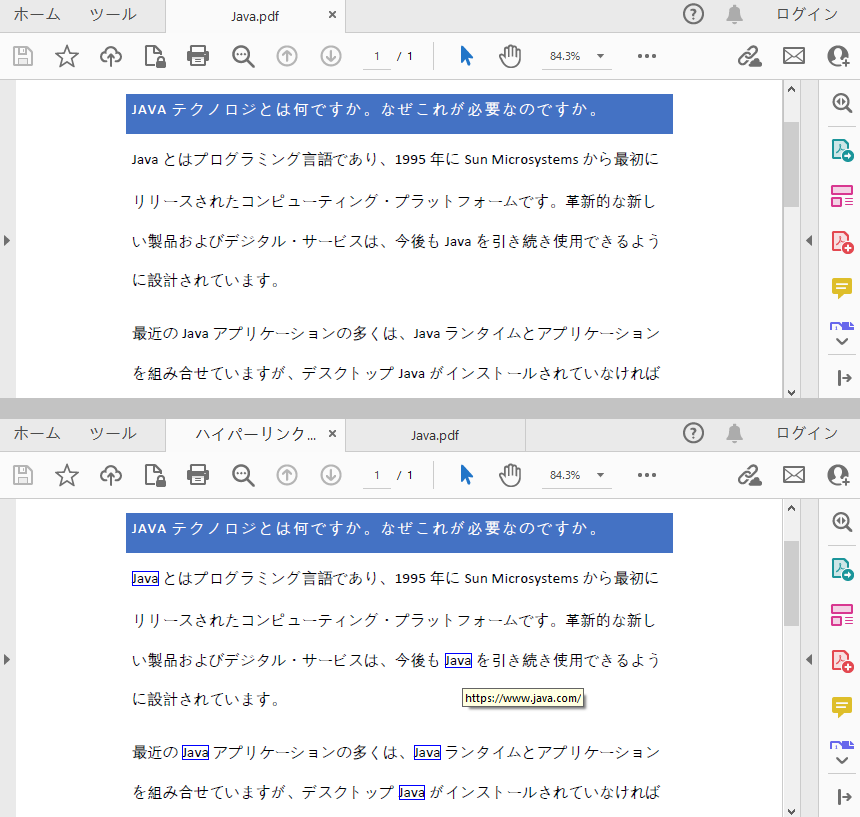
PDF文書内の特定のテキストにハイパーリンクを挿入する
PDF文書にハイパーリンクを挿入するには、対象のテキストを探し出し、そこにハイパーリンクを追加する必要があります。
詳細な手順は以下の通りです。
- PdfDocument クラスのインスタンスを生成し、PdfDocument.loadFromFile() メソッドを使用してPDFドキュメントを読み込みます。
- PdfDocument.getPages().get() メソッドを使用して、ドキュメントの特定のページを取得します。
- PdfPageBase.findText()** メソッドを使用してページ内のすべてのマッチを検索し、PdfTextFindCollection クラスのオブジェクトを返します。
- 特定の検索結果の範囲に基づいて、PdfUriAnnotation クラスのインスタンスを作成します。
- PdfUriAnnotation.set() メソッドを使用して注釈の URL アドレスを設定し、その境界線と色を設定します。
- PdfPageBase.getAnnotationWidget().add() メソッドを使用して、新しい注釈としてPDF注釈コレクションにURL注釈を追加していきます。
- PdfDocument.saveToFile() メソッドを使用して、ドキュメントを保存します。
Java
import com.spire.pdf.*;
import com.spire.pdf.annotations.*;
import com.spire.pdf.general.find.*;
import com.spire.pdf.graphics.PdfRGBColor;
import java.awt.*;
public class insertHyperlink {
public static void main(String[] args) {
//PdfDocumentクラスのインスタンスを作成する
PdfDocument pdf = new PdfDocument();
//PDF文書を読み込む
pdf.loadFromFile("Java.pdf");
//最初のページを取得する
PdfPageBase page = pdf.getPages().get(0);
//すべてのマッチを検索し、PdfTextFindCollection クラスのオブジェクトを返す
PdfTextFindCollection collection = page.findText("Java", false);
//マッチのコレクションをループする
for(PdfTextFind find : collection.getFinds())
{
//PdfUriAnnotationクラスのインスタンスを作成し、マッチのハイパーリンクを追加する
PdfUriAnnotation uri = new PdfUriAnnotation(find.getBounds());
uri.setUri("https://www.java.com/");
uri.setBorder(new PdfAnnotationBorder(1f));
uri.setColor(new PdfRGBColor(Color.blue));
page.getAnnotationsWidget().add(uri);
}
//ドキュメントを保存する
pdf.saveToFile("ハイパーリンクの挿入.pdf");
}
}
PDF文書内の特定のハイパーリンクを更新する
PDF文書内のハイパーリンクを変更することも可能です。詳しい手順は、以下の通りです。
- PdfDocument クラスのインスタンスを生成し、PdfDocument.loadFromFile() メソッドを使用してPDFドキュメントを読み込みます。
- PdfDocument.getPages().get() メソッドを使用して、ドキュメントの最初のページを取得します。
- PdfPageBase.getAnnotationsWidget() メソッドを使用して、注釈コレクションを取得します。
- PdfAnnotationCollection.get() メソッドを使用して、2番目のURLアノテーションウィジェットを取得します。
- PdfAnnotationWidget.setUri() メソッドを用いてURLを再設定します。
- PdfDocument.saveToFile() メソッドを使用して、ドキュメントを保存します。
Java
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import com.spire.pdf.annotations.PdfAnnotationCollection;
import com.spire.pdf.annotations.PdfUriAnnotationWidget;
public class changeHyperlink {
public static void main(String[] args) throws Exception {
//PdfDocument クラスのオブジェクトを作成する
PdfDocument document = new PdfDocument();
//PDFファイルを読み込む
document.loadFromFile("ハイパーリンクの挿入.pdf");
//最初のページを取得する
PdfPageBase page = document.getPages().get(0);
//注釈コレクションを取得する
PdfAnnotationCollection widgetCollection = page.getAnnotationsWidget();
//2つ目のURL注釈ウィジェットを取得する
PdfUriAnnotationWidget uriWidget = (PdfUriAnnotationWidget)widgetCollection.get(1);
//URLを再設定する
uriWidget.setUri("https://www.oracle.com/");
//ファイルを保存する
document.saveToFile("ハイパーリンクの変更.pdf");
}
}

PDF文書からハイパーリンクを削除する
PDF文書内のハイパーリンクを削除する手順は、更新する場合と似ています。URLアノテーションウィジェットを取得し、それを削除する必要があります。
詳細な手順は以下の通りです。
- PdfDocument クラスのインスタンスを生成し、PdfDocument.loadFromFile() メソッドを使用してPDFドキュメントを読み込みます。
- PdfDocument.getPages().get() メソッドを使用して、ドキュメントの最初のページを取得します。
- PdfPageBase.getAnnotationsWidget() メソッドを使用して、注釈コレクションを取得します。
- PdfAnnotationCollection.removeAt() メソッドを使用して特定のURL注釈ウィジェットを削除するか、PdfAnnotationCollection.clear() メソッドを使用してすべてのURL注釈ウィジェットを削除しています。
- PdfDocument.saveToFile() メソッドを使用して、ドキュメントを保存します。
Java
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import com.spire.pdf.annotations.PdfAnnotationCollection;
import com.spire.pdf.annotations.PdfUriAnnotationWidget;
public class changeHyperlink {
public static void main(String[] args) throws Exception {
//PdfDocument クラスのオブジェクトを作成する
PdfDocument document = new PdfDocument();
//PDFファイルを読み込む
document.loadFromFile("ハイパーリンクの挿入.pdf");
//最初のページを取得する
PdfPageBase page = document.getPages().get(0);
//注釈コレクションを取得する
PdfAnnotationCollection widgetCollection = page.getAnnotationsWidget();
//2つ目のURL注釈ウィジェットを削除する
widgetCollection.removeAt(1);
//すべてのURL注釈ウィジェットを削除する
//widgetCollection.clear();
//ファイルを保存する
document.saveToFile("ハイパーリンクの削除.pdf");
}
}

この記事では、PDF文書内のハイパーリンクを処理する方法を紹介します。もし、PDF文書内のハイパーリンクやその他の要素の操作方法についてもっと知りたい場合は、Spire.PDF Forumにアクセスしてください。