現代のデータ駆動型テクノロジー環境において、JSON、XML、YAMLは、その階層的な構造表現と高い互換性により、システム間のデータ交換に広く利用されている主要な構造化データ形式です。しかし、これらの半構造化データを、直感的な可視化、動的な計算、共同編集などの機能を備えた形式に変換する必要がある場合、Excelファイルが最適な選択肢となります。Excelは、ビジネス分析、研究管理、部門間の情報共有といった分野において、欠かすことのできないツールです。
Pythonを使ってこの変換プロセスを自動化することで、異なるデータ形式間のギャップを埋め、元データの構造を保持しつつ、ソート、数式計算、ピボットテーブルなどの機能を付加することが可能になります。
この記事では、Pythonを使ってJSON、XML、YAML形式のデータをExcelファイルにインポートする方法を解説します。
内容:
本記事のExcelデータの書き込み方法では、Free Spire.XLS for Pythonを使用します。インストールは以下のコマンドで行えます:
pip install spire.xls.free
PythonでExcelワークシートにデータを書き込む方法
Free Spire.XLS for Pythonでは、Excelファイルの新規作成や既存ファイルの読み込み、データの書き込み、セルの書式設定などを簡単に行うことができます。基本的な手順は以下の通りです:
-
Workbookクラスを使って新しいExcelワークブックを作成(初期状態では3つのワークシートが含まれます)、またはWorkbook.LoadFromFile()メソッドで既存のワークブックを読み込みます。 -
Workbook.Worksheets.get_Item()メソッドで特定のワークシートを取得、またはWorkbook.Worksheets.Add(sheetName: str)メソッドで新しいワークシートを作成します。 - Pythonの組み込みモジュール
json、xml.etree.ElementTree、yamlを使用して、各種データを読み込みます。 -
Worksheet.Range.get_Item()メソッドでセルを指定し、CellRange.Valueプロパティで値を書き込みます。 -
CellRange.BuiltInStyle、CellRange.ApplyStyle()、Worksheet.AutoFitColumn()などの機能を使って、セルやワークシートの書式を整えます。 - 最後に、
Workbook.SaveToFile()メソッドでExcelファイルを保存します。
PythonでJSONデータをExcelに取り込む
JSONは軽量なデータ交換フォーマットで、Webアプリケーションにおけるフロントエンドとバックエンドのデータ通信などに広く利用されています。Pythonでは、標準ライブラリの json モジュールを使ってJSONファイルを読み込むことができます。読み込んだデータは、Spire.XLS for Pythonを使ってExcelに書き込むことが可能です。必要に応じてセルの書式設定も行えます。
コードの例:
# 必要なライブラリをインポート
from spire.xls import Workbook, FileFormat, BuiltInStyles
import json
# JSON形式の注文データを読み込み・解析する
with open("E-Commerce Order Data.json", "r", encoding="utf-8") as f:
jsonData = json.load(f)
# Excelの列ヘッダーを定義する
headers = ["order_id", "customer", "order_date", "status", "total", "product", "quantity", "price"]
# ネストされたJSON構造をフラットな表形式データに変換する
rows = []
for order in jsonData:
for item in order["items"]:
# 注文のメインデータと商品の明細データを結合する
row = [
order["order_id"], order["customer"], order["order_date"],
order["status"], str(order["total"]), item["product"],
str(item["quantity"]), str(item["price"])
]
rows.append(row)
# Excelブックとワークシートを初期化する
workbook = Workbook()
workbook.Worksheets.Clear()
sheet = workbook.Worksheets.Add("Orders")
# 1行目にヘッダーを書き込む
for col, header in enumerate(headers):
sheet.Range[1, col + 1].Value = header
# データ行の内容を書き込む
for row_idx, row_data in enumerate(rows):
for col_idx, value in enumerate(row_data):
sheet.Range[row_idx + 2, col_idx + 1].Value = value
# 表のスタイルを設定する
sheet.Rows[0].BuiltInStyle = BuiltInStyles.Heading2 # ヘッダー行のスタイル
for row in range(1, sheet.Rows.Count):
sheet.Rows[row].BuiltInStyle = BuiltInStyles.Accent2_40 # データ行のスタイル
# 列幅を自動調整する
for col in range(sheet.Columns.Count):
sheet.AutoFitColumn(col + 1)
# 保存してリソースを解放する
workbook.SaveToFile("output/JSONToExcel.xlsx", FileFormat.Version2016)
workbook.Dispose()
💡 明確に示すために、上記のコードは既知のフィールド構造に基づいて直接抽出を行っています。実際のプロジェクトでは、データの形式に応じてフィールドを動的に処理するか、構造の変更に対応できるようにエラーハンドリングのロジックを追加することを推奨します。
JSONファイル:

出力Excelファイル:
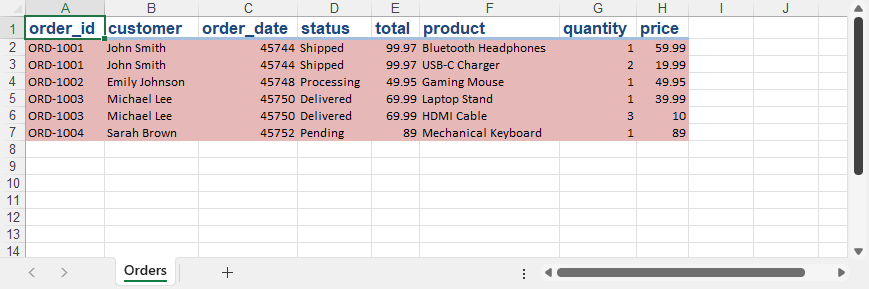
PythonでXMLデータをExcelに取り込む
XMLは、複雑な構造を持つデータの表現に適したマークアップ言語で、属性やコメントなどの機能も備えています。Python標準ライブラリの xml.etree.ElementTree を使うことで、XMLファイルからデータを抽出できます。Free Spire.XLS for Pythonと組み合わせて、XMLデータをExcelに取り込むことができます。
コードの例:
# XML処理ライブラリとExcel操作ライブラリをインポートする
import xml.etree.ElementTree as ET
from spire.xls import Workbook, FileFormat, BuiltInStyles
# XML形式の変更履歴ファイルを解析する
tree = ET.parse("Software Manual Changelog.xml")
root = tree.getroot()
# 表の列ヘッダーを定義する
headers = ["version", "date", "editor", "change"]
rows = []
# XMLデータ構造を抽出して変換する
for entry in root.findall("entry"):
# 共通フィールドを抽出する
version = entry.findtext("version", "")
date = entry.findtext("date", "")
editor = entry.findtext("editor", "")
# 複数の変更項目を個別行として展開する
for change in entry.find("changes").findall("change"):
rows.append([version, date, editor, change.text.strip()])
# Excelブックを作成する
workbook = Workbook()
workbook.Worksheets.Clear()
sheet = workbook.Worksheets.Add("Changelog")
# 表のヘッダー行を書き込む
for col, header in enumerate(headers):
sheet.Range[1, col + 1].Value = header
# 変更履歴データを入力する
for row_idx, row_data in enumerate(rows):
for col_idx, value in enumerate(row_data):
sheet.Range[row_idx + 2, col_idx + 1].Value = value
# スタイルテンプレートを適用する
sheet.Rows[0].BuiltInStyle = BuiltInStyles.Heading1 # メインタイトルのスタイル
for row in range(1, sheet.Rows.Count):
sheet.Rows[row].BuiltInStyle = BuiltInStyles.Accent1_40 # 交互行の背景色
# 列幅を自動調整する
for col in range(sheet.Columns.Count):
sheet.AutoFitColumn(col + 1)
# ファイルを出力してリソースを解放する
workbook.SaveToFile("output/XMLToExcel.xlsx", FileFormat.Version2016)
workbook.Dispose()
💡 明確に示すために、上記のコードは既知のフィールド構造に基づいて直接抽出を行っています。実際のプロジェクトでは、データの形式に応じてフィールドを動的に処理するか、構造の変更に対応できるようにエラーハンドリングのロジックを追加することを推奨します。
XMLファイル:
出力Excelファイル:

PythonでYAMLデータをExcelに取り込む
YAMLは、可読性に優れた構成ファイル形式で、DevOpsやシステム設定などの分野で広く使われています。表形式データに特化しているわけではありませんが、構造化された設定情報をExcelに変換することで、レビューや記録、共有がしやすくなります。Pythonの yaml モジュールを使ってYAMLファイルを解析し、Spire.XLS for PythonでExcelに書き込むことが可能です。
コードの例:
# YAML処理ライブラリとExcel操作ライブラリをインポートする
import yaml
from spire.xls import Workbook, FileFormat, BuiltInStyles
# CI/CDパイプラインの設定ファイルを読み込む
with open("CI CD Pipeline Configuration.yaml", "r", encoding="utf-8") as f:
yaml_data = yaml.safe_load(f) # YAML内容を安全に解析する
# パイプライン分析レポートの列構成を定義する
headers = ["stage", "command", "output_file", "coverage", "environment"]
rows = []
# パイプラインステージの多次元データを展開する
for stage in yaml_data["stages"]:
# ステージの基本情報を抽出する
name = stage.get("name", "")
commands = stage.get("commands", [])
coverage = str(stage.get("coverage", "")) # 数値を文字列に変換
environment = stage.get("environment", "")
outputs = stage.get("artifacts", []) or [""] # 出力ファイルが空の場合を処理
# コマンドごとに明細行を展開する
for i, cmd in enumerate(commands):
# 指標データは先頭行のみに保持してデータを結合する
row = [
name,
cmd,
outputs[i] if i < len(outputs) else "", # コマンドと出力ファイルを対応付け
coverage if i == 0 else "", # カバレッジは先頭行のみに表示
environment if i == 0 else "" # 環境情報も先頭行のみに表示
]
rows.append(row)
# レポート用のワークブックを作成する
workbook = Workbook()
workbook.Worksheets.Clear()
sheet = workbook.Worksheets.Add("Pipeline")
# ヘッダー構造を作成する
for col, header in enumerate(headers):
sheet.Range[1, col + 1].Value = header
# 動的に生成されたパイプラインデータを入力する
for row_idx, row_data in enumerate(rows):
for col_idx, value in enumerate(row_data):
sheet.Range[row_idx + 2, col_idx + 1].Value = str(value) # 強制的に文字列に変換して入力
# ステップ状のスタイルを適用する
sheet.Rows[0].BuiltInStyle = BuiltInStyles.Heading4 # ダークグラデーションのタイトル
for row in range(1, sheet.Rows.Count):
sheet.Rows[row].BuiltInStyle = BuiltInStyles.Accent2_40 # ライトグレーの交互行背景
# 列の表示幅を最適化する
for col in range(sheet.Columns.Count):
sheet.AutoFitColumn(col + 1)
# レポートファイルを保存する
workbook.SaveToFile("output/YAMLToExcel.xlsx", FileFormat.Version2016)
workbook.Dispose()
💡 明確に示すために、上記のコードは既知のフィールド構造に基づいて直接抽出を行っています。実際のプロジェクトでは、データの形式に応じてフィールドを動的に処理するか、構造の変更に対応できるようにエラーハンドリングのロジックを追加することを推奨します。
YAMLファイル:

出力Excelファイル:

本記事では、Pythonを用いてJSON、XML、YAMLといった構造化データをExcelファイルに取り込む方法を紹介しました。各形式の読み込みからExcelへの書き込みまでの手順と、コード例を通じて具体的な実装方法を解説しています。