概要
・kaggleにあるABテストの結果のデータセットを用いて、広告の効果を検証。検証方法は4つ「平均の差、重回帰分析、傾向スコアマッチング、IPW」。
・一部(共変量を調整した重回帰分析)の検証方法では広告によりコンバージョン率が下がるというマイナスの効果が確認されたが、これはPost Treatment Bais(処置後変数バイアス)によるものだと考えられる。
・その他の分析手法では概ね広告にはプラスの効果があることが示された。
・今回の分析での壁は、本当の因果効果を推定するための必要な共変量がおそらくないこととドメイン知識不足により、どのような変数をコントロールすれば良いのかわからないことだった。
利用したデータセットとその説明
kaggleにあるデータセットで、広告マーケティングをする際にABテストを実施した結果をデータにしたものを利用。
データセットのサイズ:588101 rows × 6 columns
各カラムについての説明と前処理
・user id: User ID (unique)
・test group: If "ad" the person saw the advertisement, if "psa" they only saw the public service announcement
→分析ではダミー変数化し、adというカラムにした。今回の分析の処置変数。大多数(588101人中564577人)が広告を見ており、広告を見た場合は1、普通の広告または、広告を見ていない場合は0となっている。
説明文やデータを見ると、厳密なABテストを実施しているわけではないことがわかる。
・converted: If a person bought the product then True, else is False
→今回の分析の目的変数。ユーザーがコンバージョンした場合は1、していない場合は0。
・total ads: Amount of ads seen by person
→ユーザーがその広告を見た回数。
・most ads day: Day that the person saw the biggest amount of ads
→ユーザーがその広告を見た回数が最も多い曜日。ダミー変数化し、月曜日から日曜日の7つのカラムに変換。
・most ads hour: Hour of day that the person saw the biggest amount of ads
→ユーザーがその広告を最も見た時間帯。ダミー変数化し、0時から23時の24のカラムに変換。
# ダミー変数化
df['ad'] = df['test group'].replace({'ad':1,'psa':0})
df.drop(columns='test group', inplace=True)
df.converted.replace({True:1,False:0}, inplace=True)
df = pd.concat([df,pd.get_dummies(df['most ads day'])],axis=1)
df = pd.concat([df, pd.get_dummies(df['most ads hour'].astype('str'))],axis=1)
# 特徴量エンジニアリング
df['total ads**2'] = df['total ads'] ** 2
df['total ads log'] = np.log(df['total ads'])
# 交差項の作成
df['total ads * ad'] = df['total ads'] * df['ad']
df['total ads log * ad'] = df['total ads log'] * df['ad']
df['total ads**2 * ad'] = df['total ads**2'] * df['ad']
効果検証
①平均の差
トリートメント(介入群のこと)とコントロール(非介入群のこと)の平均の差を算出。
ABテストが完全なランダム化比較実験(RCT)である場合、2つの群の平均の差がATE(平均因果効果)になり、分析はこの段階で終了する。
広告をするとコンバージョン率が平均して0.769ポイント上昇する。
②重回帰分析
4パターンの共変量の組み合わせを試す。
「total ads」のみ
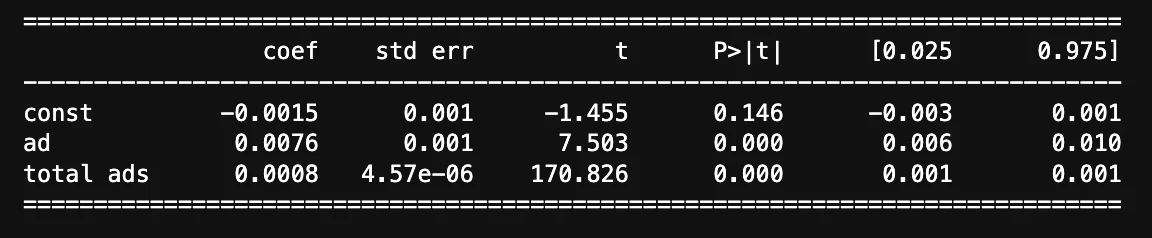
「total ads」と「most ads day」
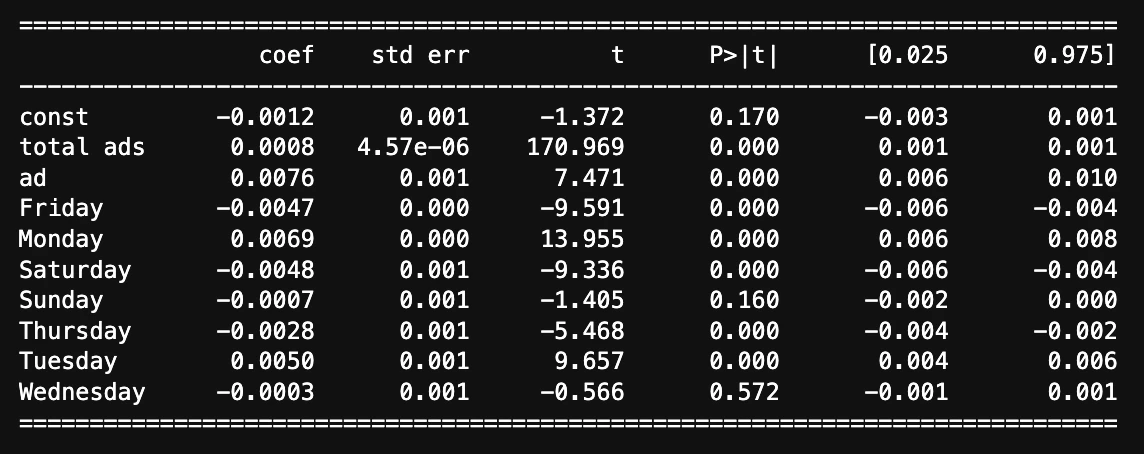
「total ads」とm「ost ads hour」
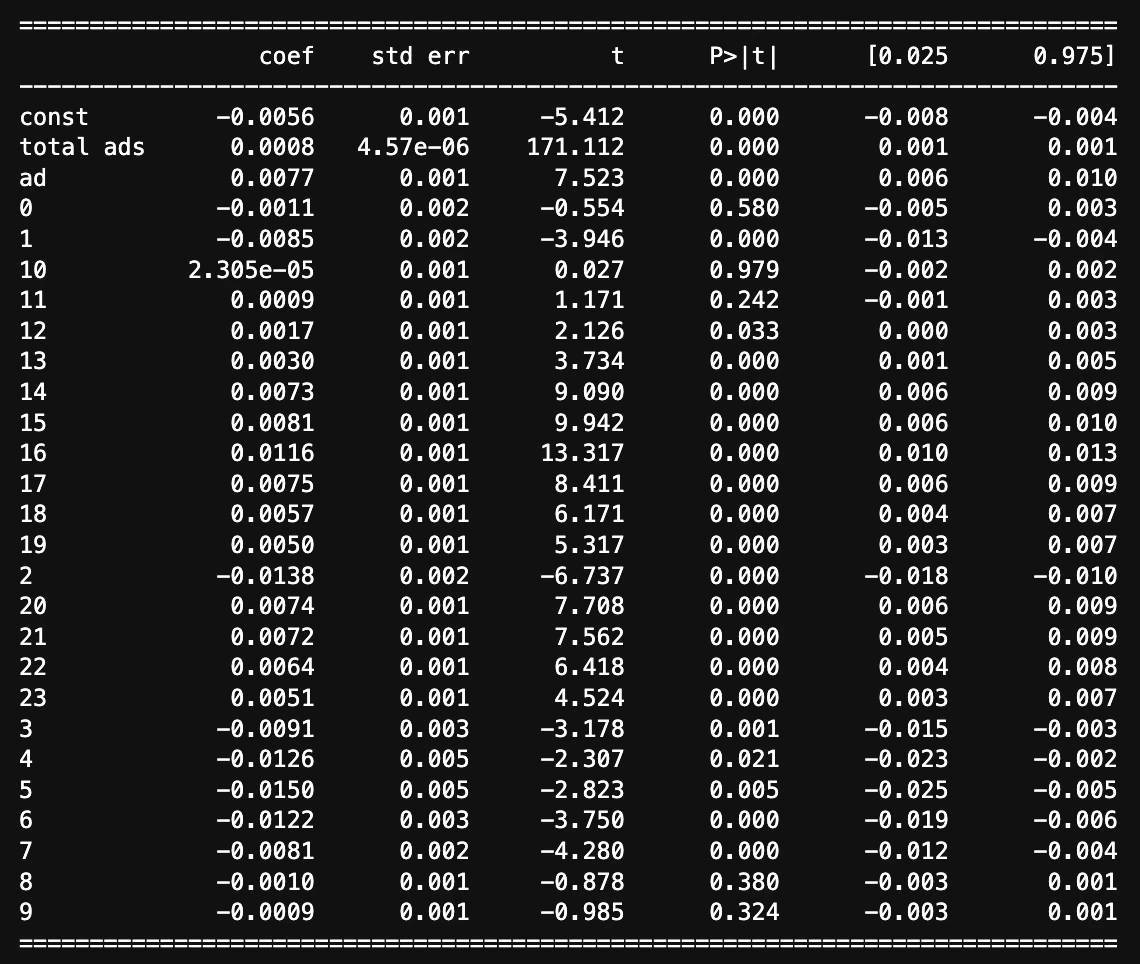
「total ads」と「most ads hour」と「most ads day」
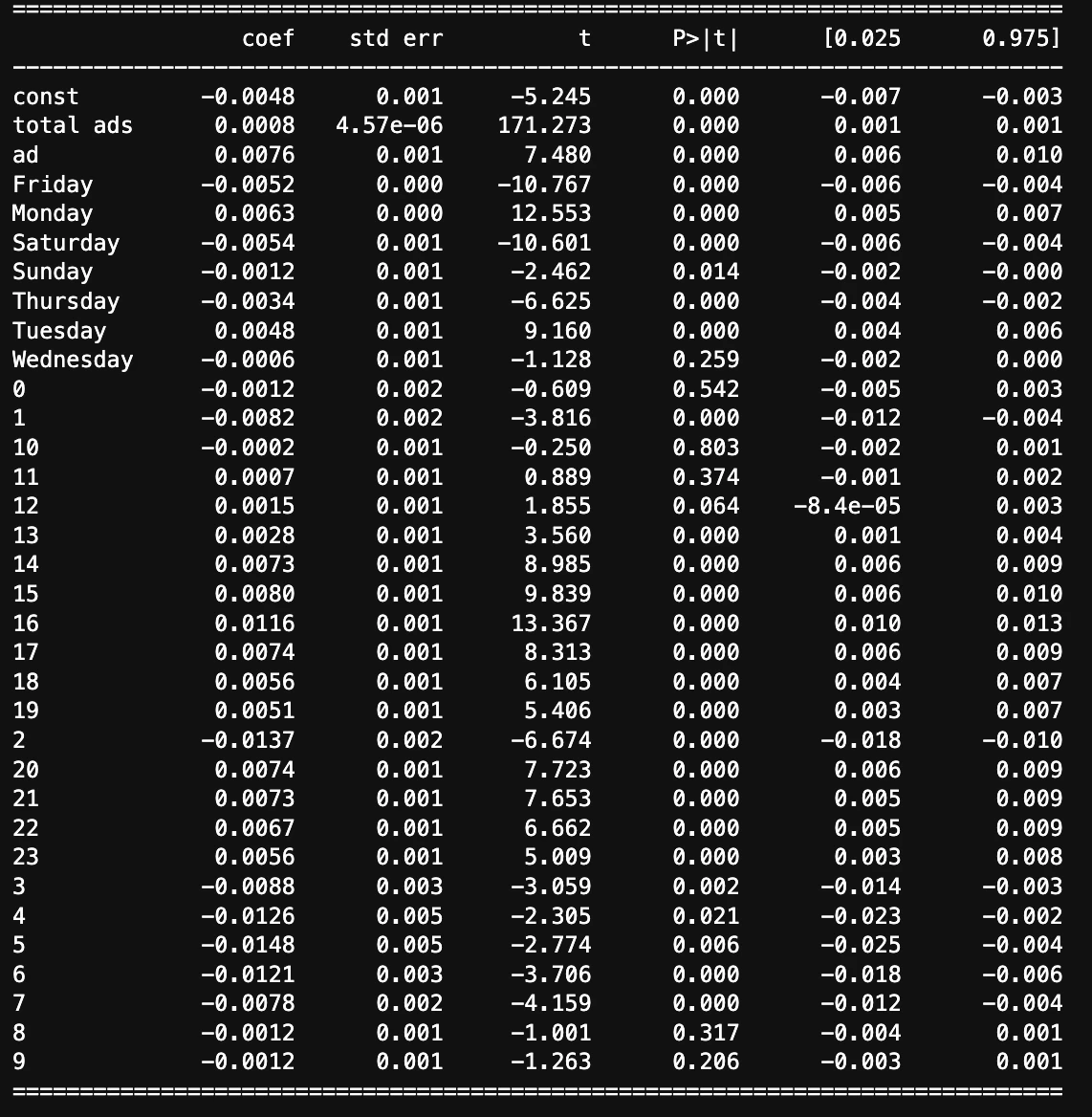
どのシュチュエーションにおいても介入変数の回帰係数は0.0077付近と現状ではロバストな結果を示すことがわかる。このように様々な変数を入れたり抜いたりして分析結果が安定していることを確認する行為をsensitive analysisという。
これらの結果と平均差を求めた時と結果はほとんど同じ。
# 共変量をコントロールし、広告の効果量を推定する。
col_linear1 = ['ad', 'total ads']
col_linear2 = [ 'total ads','ad','Friday','Monday', 'Saturday', 'Sunday', 'Thursday', 'Tuesday','Wednesday']
col_linear3 = [ 'total ads','ad',
'0', '1', '10', '11', '12', '13', '14', '15', '16', '17',
'18', '19', '2', '20', '21', '22', '23', '3', '4', '5', '6', '7', '8',
'9',]
col_linear4 = [ 'total ads','ad','Friday','Monday','Saturday','Sunday','Thursday','Tuesday','Wednesday',
'0', '1', '10', '11', '12', '13', '14', '15', '16', '17',
'18', '19', '2', '20', '21', '22', '23', '3', '4', '5', '6', '7', '8','9',]
# 4パターン試す
for i in range(1,5):
col_name = 'col_linear' + str(i)
x = df[locals()[col_name]]
y = df.converted
model = sm.OLS(y,sm.add_constant(x)).fit()
print(model.summary().tables[1],end = '\n\n\n\n')
③共変量を変換した重回帰分析
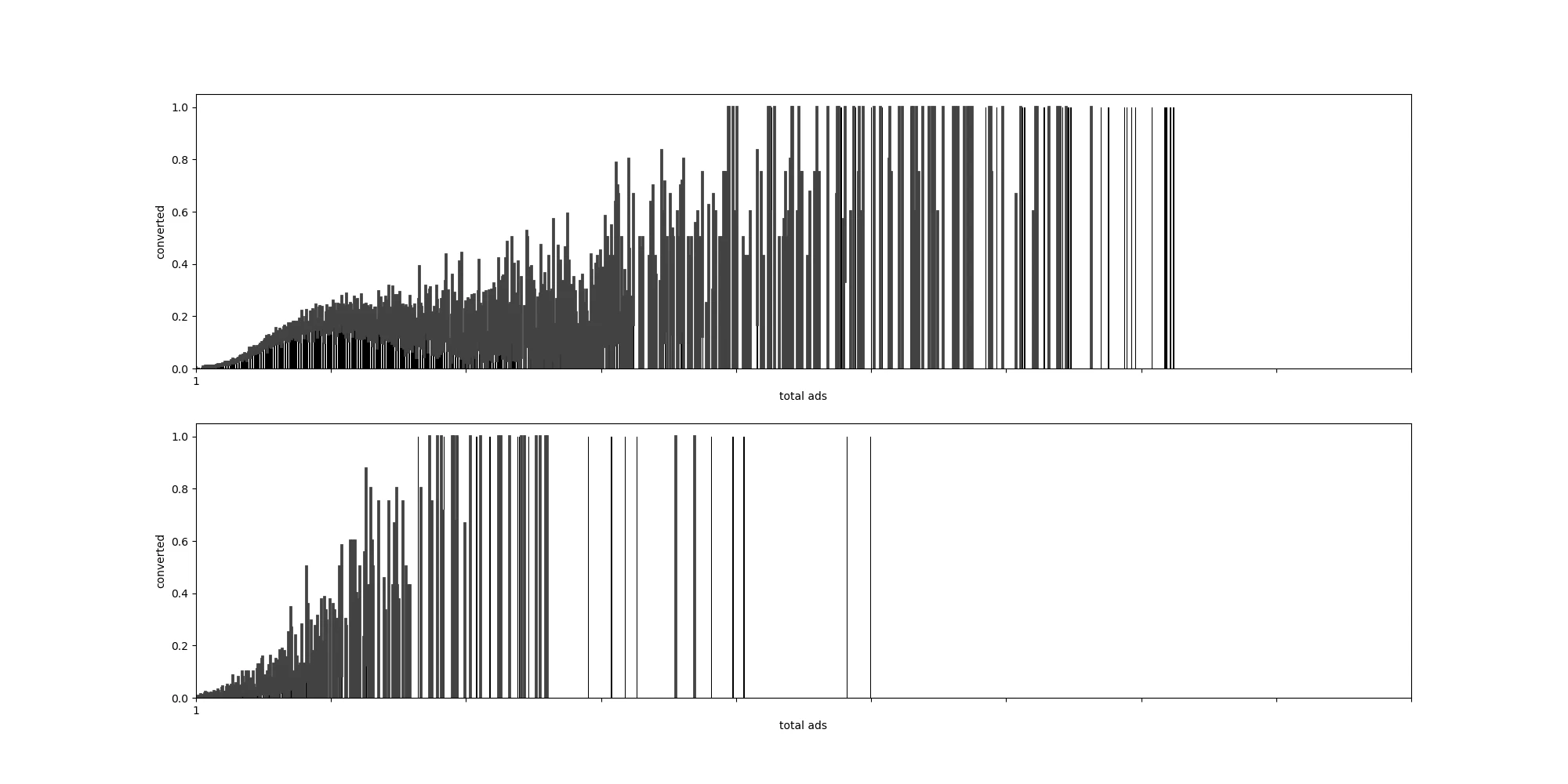
まず、total adsとconvertedの関係を可視化する。シンプルな発想として、ユーザーが広告に触れる回数が増えれば、コンバージョンもしやすくなる可能性がある。加えて、コンバージョンさせるためにとりあえず、新広告をユーザーに多量に打つという可能性も考えられるため。
上がトリートメント・、下がコントロール。横軸の縮尺は同じ。トリートメントを見ると、コントロールと比べて、広告を多量に打ってもなかなかコンバージョンしにくいことがわかる。また、下図より、total adsが増えるにつれて、コンバージョン率が指数関数的に増えていることがわかるので、対数変換を行う。
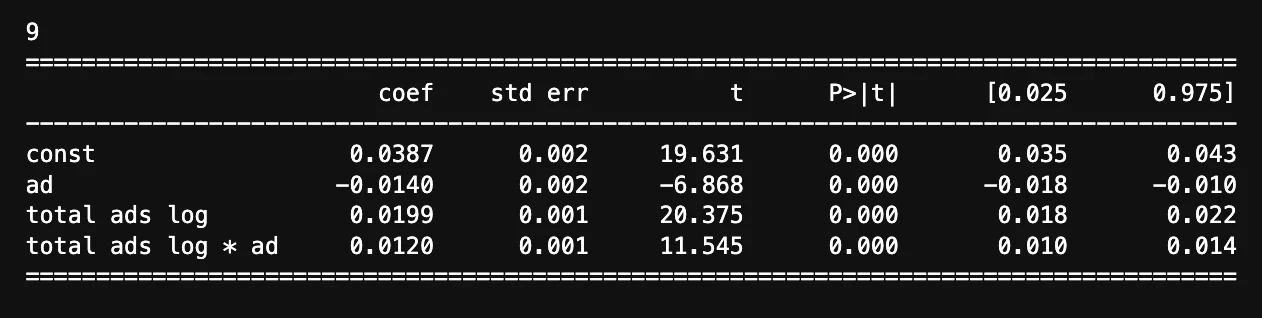
以下の2つの共変量を入れた重回帰分析を行う。
・total adsを対数変換したもの
・total adsを対数変換したものと介入変数との交差項
この時、広告するとコンバージョン率が下がることが示された。
介入変数と共変量の相関係数は低く、介入変数とその他でマルチコが発生している可能性は低い。

④傾向スコアマッチング法(最近傍マッチング)
コントロールをトリートメンtにマッチングさせた場合の結果(ATTを導出)。4562個マッチング。

トリートメントをコントロールにマッチングさせた場合(ATUを導出)。4586個マッチング。

それぞれの結果は平均の差を求めた時と値はほとんど変わらない。
⑤IPW
傾向スコアで逆重みづけを行った結果が下図。
広告の効果がほとんどないことが示されている。
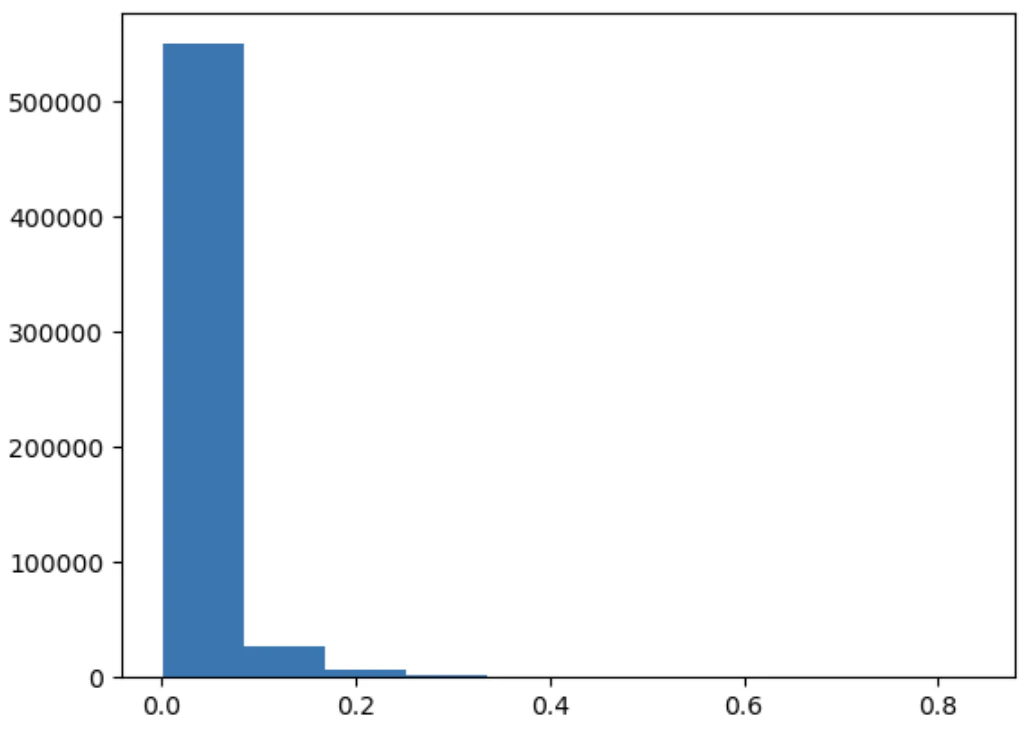
原因は傾向スコアがほぼ0のデータが頻繁の使われていることにある。
傾向スコアのヒストグラムを確認すると、ほぼ0のデータが大量にあることがわかる。
IPWの弱点の1つに、用いる確率が0に近いデータがあると、結果が過大・または過小に評価されがちになるというものがある。
なぜそうなるかというと、IPWにおいて確率で値を調整する際に、「値/確率」を計算するわけだが、この時分母である確率の値が0に近いと、そのデータは過大に評価されてしまうということが起こる。
分析の結論
・共変量を対数変換したものと、その値と介入変数との交差項を共変量に入れた重回帰分析では、広告すれば、コンバージョン率が下がるという結果が得られた。
・その他の分析では広告をするとコンバージョン率がおよそ0.77ポイント上昇することがわかった。
・IPWでは広告効果はほとんどないという結果が示されたが、これの原因は用いる逆確率がほぼ0に近いことに起因するものだと思われる。
効果検証の「③共変量を変換した重回帰分析」について深掘り
考えられる可能性は3つある。個人的には①番を押したい。
①含めてはいけない共変量を入れたことにより、PostTreatmentBias(処置後変数バイアス)が発生している。
共変量を重回帰分析に含めることでバイアスを少なくして推定することができる。一方で、重回帰分析に入れてはいけない共変量があり、それを重回帰分析に含めるとバイアスを発生させてしまうことがある。
バイアスを発生させるようなシチュエーションは、その共変量がコライダー(合流点)かチェーン(因果の効果の途中にある)にあるような状況の時である。下図が2つの大雑把なイメージ。
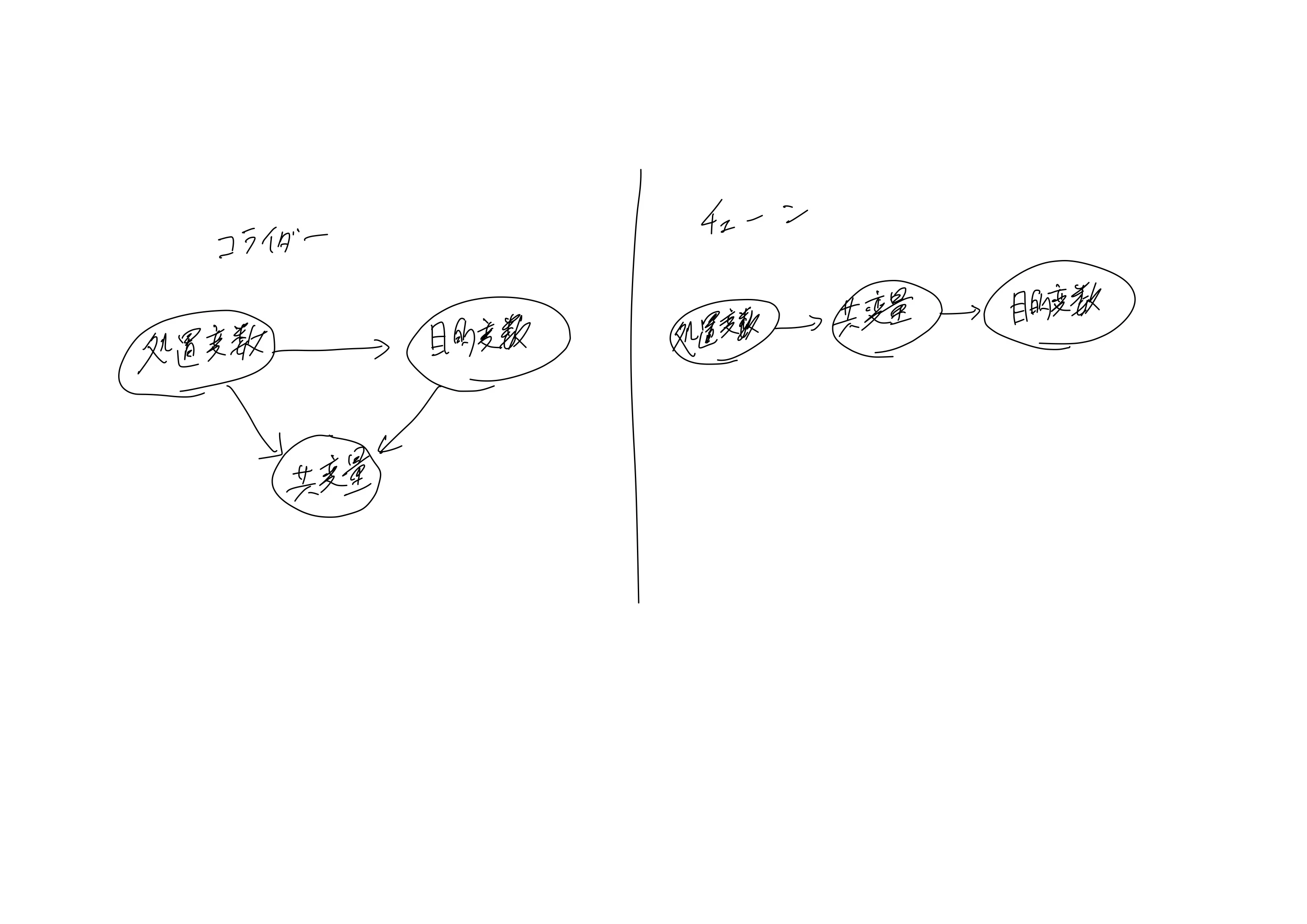
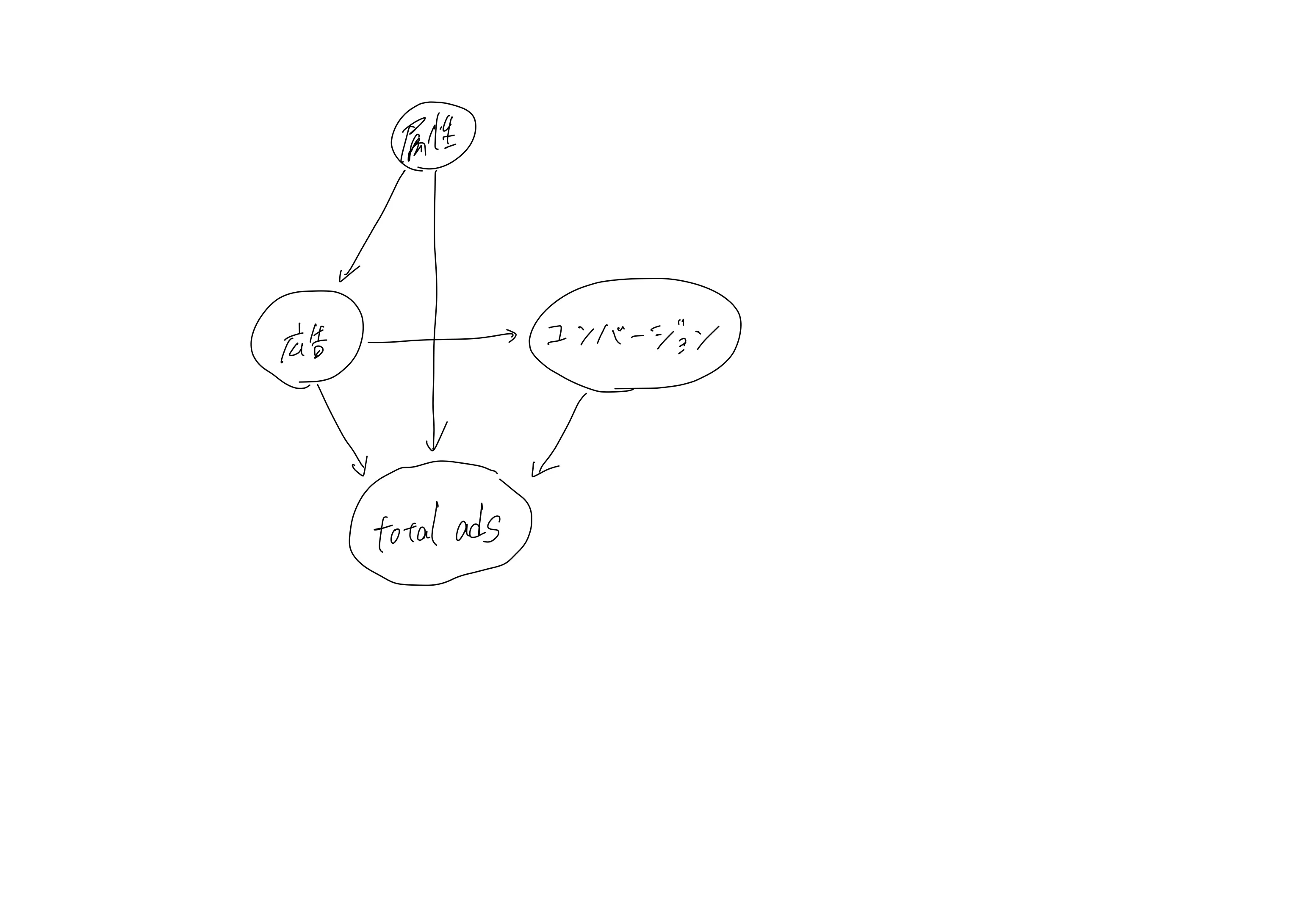
「total ads」がこのような共変量に該当するか考えると、コライダーに属する可能性がある。
言葉で説明すると、
・新広告を送付することわかった時点で、大量の広告を送る(ad(広告)→total ads)という経路
・とりあえずコンバージョンするまで広告をし続けるという「convertd→total ads」という経路
が可能性としては考えられる。この場合、この共変量はコライダーなので、重回帰分析の説明変数に含めるとバイアスが発生して、正しい効果検証ができなくなってしまうことがわかる。
データが抽出された背景やドメイン知識がないので、結論を出すことはできないが、本当は広告効果があるにも関わらず、効果がないように見える時もあるので分析は慎重に行う必要があると改めて思った。
②マルチコ(多重共線性)の発生
これは、共変量と介入変数の相関を確認すれば、ある程度わかる。上ですでに確認しており、相関係数が低いことがわかっているので、マルチコは発生していないと考えられる。
③本当に広告には効果がなかった。
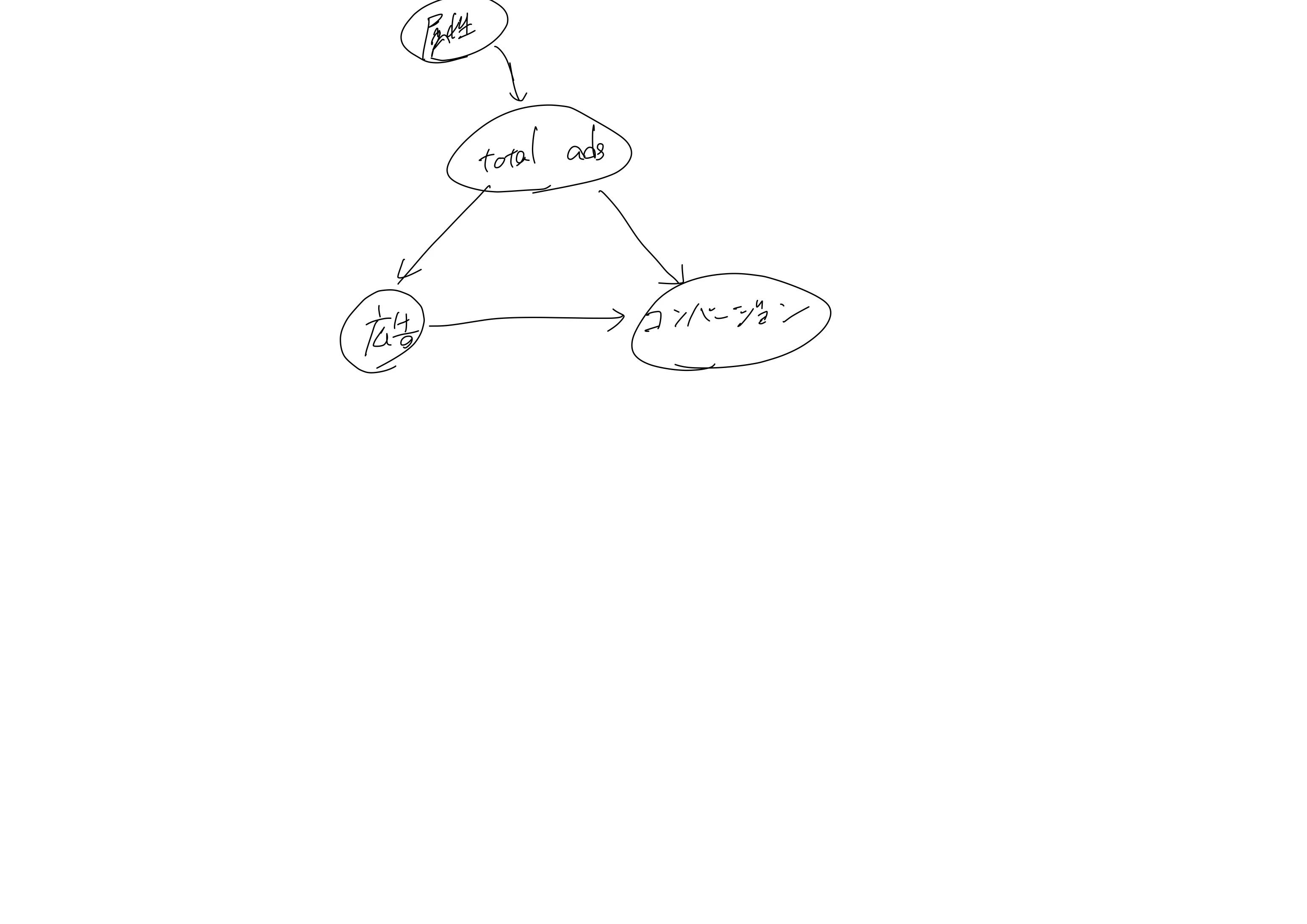
ここで論じる可能性は、2つの変数(total_adsを対数変換したもの、total_adsを対数変換したものと介入変数との交差項)がバイアスを少なくするための正しい共変量であるということである。この場合考えられる因果ダイアグラムの1例は下図のようになる。
言葉で説明すると、
・total adsが多くなりそうな顧客に対しては、広告を打つようにする。total ads→広告という経路。
・total adsが多いユーザーはコンバージョンしやすい。total ads→コンバージョンという経路。
となる。この場合total adsの対数化した値が広告を打つか否かのキーとなり、傾向スコアで分析した結果と似通っていないのは違和感ではある。
再度、介入の有無別にで縦軸をコンバージョン率、横軸をTotal adsをとった棒グラフを確認する。
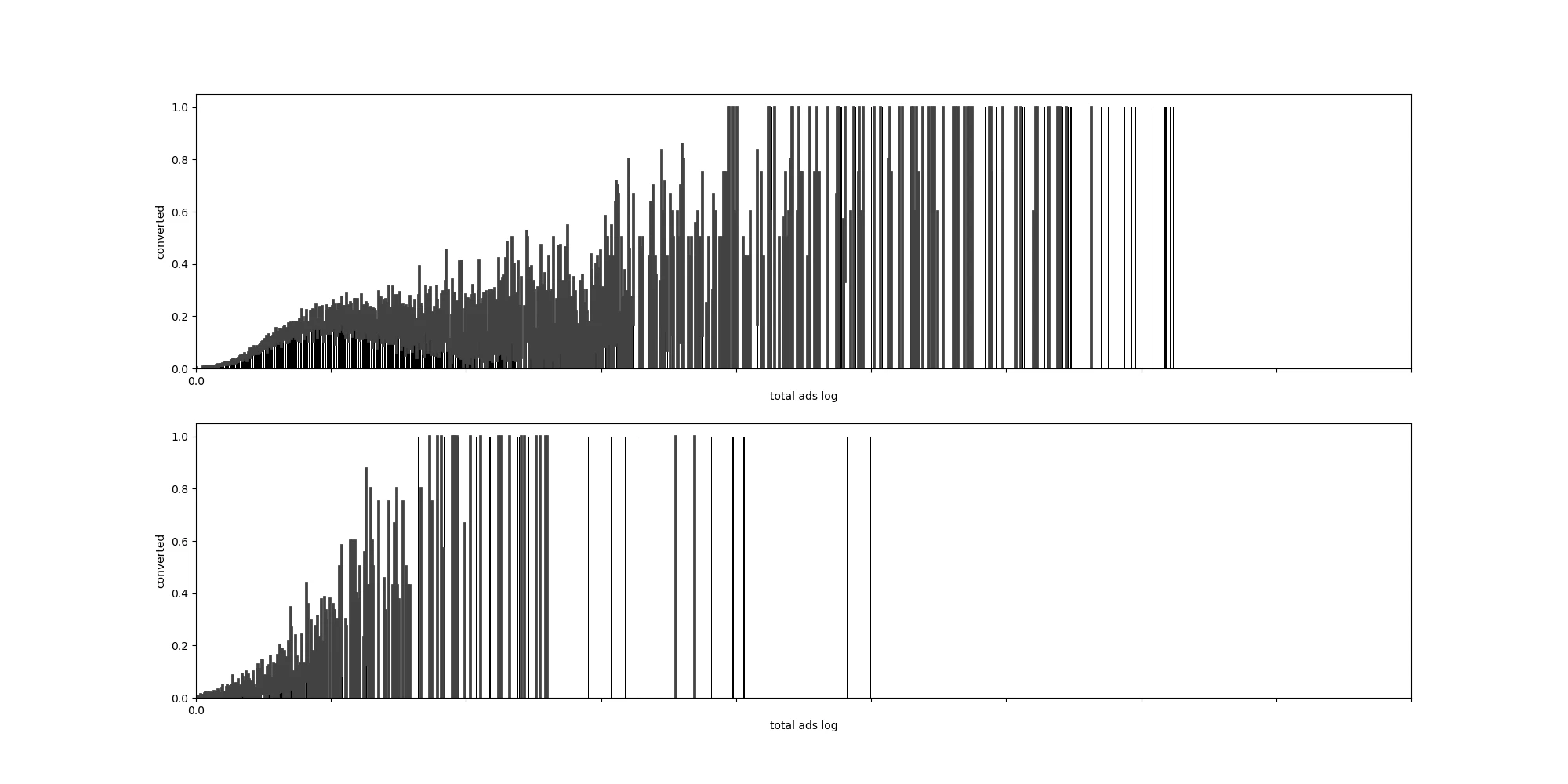
すると、トリートメント(上側)では広告を打っているから、コントロール(下側)よりも単純んいコンバージョン率が高いわけれもなく、また、トリートメント側でtotal adsが増えるに従って必ずしもコンバージョン率が増えるわけでもないので、もしかしたら本当に広告の効果はないのかもしれない。
また、このグラフ別の見方として、広告を打った人に対してはコンバージョンするまで多量に広告を打ち続ける結果このようなグラフになったと見ることもでき、介入変数adとtotal adsの交互作用が発生している場合も考えられる。
最後に注釈:この章では因果ダイアグラムを色々考慮したが、RCTを行っている場合、介入変数への矢印はすべてカットされるため、今まで考察してきた因果ダイアグラムは間違っていることになります。ただし、この記事のデータセットの説明のところでも書きましたが、そもそもこのデータがABテストと銘を打っていながら、RCTをしているように見えなかったため、この考察をする意味はあるのかなと思います。
各分析手法に対する考察
①傾向スコアの妥当性
傾向スコアの妥当性を考えるにあたってキーとなることは、その傾向スコアがセレクションバイアスをなくすかどうかである。
すなわち、セレクションバイアスを軽減する傾向スコアは良いということ。
セレクションバイアスはトリートメントとコントロールの2つのグループの性質に差がある場合に生じる。
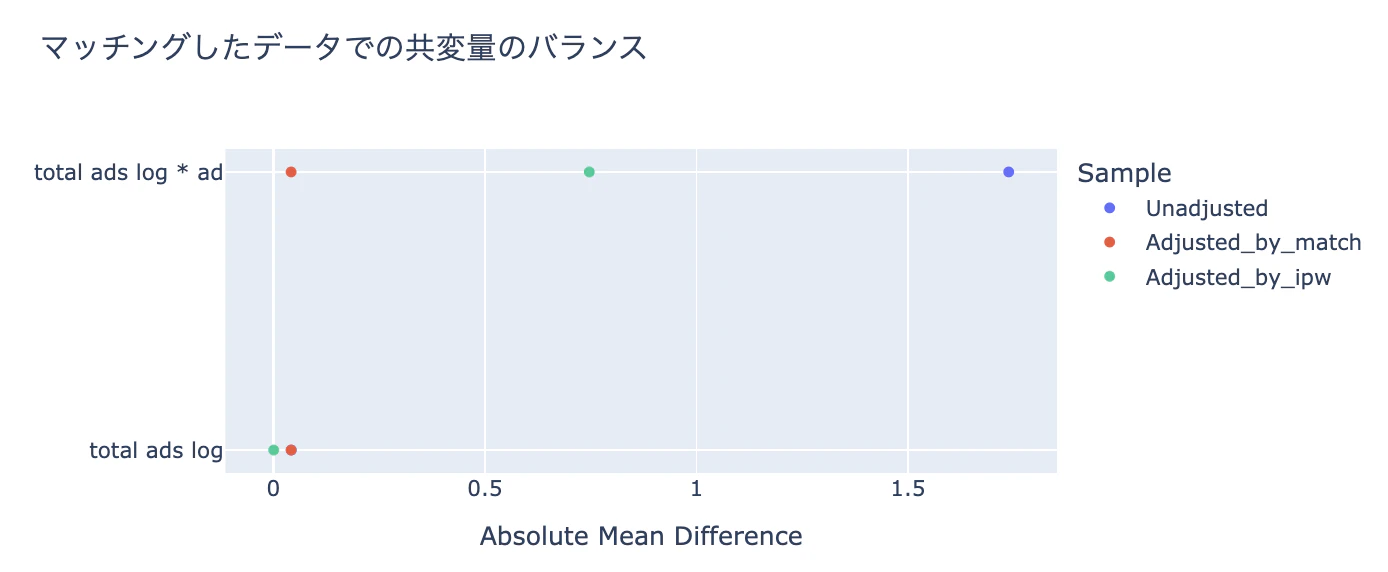
2つのグループの性質を可視化するための方法の1つとして、共変量のバランスを標準化平均差(ASAM)で確認する方法がある。
これを見て、調整後の共変量のASAMが0に近い場合、2つのグループのバランスは調整されており、セレクションバイアスをコントロールして分析できる見立てることができる。目安はすべての共変量でASAMが0.1以下に収まっていること。
下図を見るとマッチング法では共変量の調整がうまくいっていることがわかる。
②傾向スコアのメリット
回帰分析と比較して説明すると、回帰分析による因果効果推論ではバイアスを発生させるすべての共変量が説明変数に含まれている必要がある。ゆえに、回帰分析ではモデリングする労力が求められる。
一方、傾向スコアを用いた分析では、介入するか否かを決める基準となっている共変量を用いて、傾向スコア(介入群に割り振るか、否かの確率)を割り出せば、モデリングする必要もなく因果効果の推論をすことができる。
加えて、観測することが不可能な変数(例えば、能力や思いなど)が、交絡変数となっている場合、回帰分析ではバイアスが生じる(操作変数法などを使えば回避できる)が、傾向スコアマッチングではモデリングが不要なのでこのバイアスを回避することができる。
③IPWと傾向スコアマッチングの結果がズレる理由
結論はIPWでは全データを使うが、傾向スコアマッチングではマッチングしない1部のデータを捨てているため、同じ傾向スコアを用いても結果が一致しない。
以下は2つの方法を比較したメリット・デメリットを記述する。
IPWのメリット
=全データを使用するので、分析結果が恣意的にならない。
IPWのデメリット
=利用する確率の値が0に近いと、そのデータが異常に水増しされて、結果が過大・または過小に生じる可能性がある
傾向スコアマッチングのメリット
=IPWのデメリットが生じない(バイアスが生じないとは言ってない)。
傾向スコアマッチングのデメリット
=マッチングの許容範囲を調整することによって結果を恣意的にコントロールできる。
④IPWの推定した因果効果の値が小さい理由
③で記述した、IPWのデメリットが大きく出た形となっている。確率が0に近い値が多かったため、効果が過小に推定された可能性がある。