はじめに
LangGraphは、複数のLLMと連携したAIマルチエージェントアプリケーション構築のためのライブラリです。
ところで、AIエージェント向けと謳いつつも、LangGraphにはAIモデルと直接やり取りする機能はなく、その部分はLangChainなど他のライブラリが担います。そのため、AIエージェントのサンプルコードはどうしてもLangChainとLangGraphを併用したものが多くなり、読んでみたけど実はLangGraphの機能ではなかったり、動かすためにはライセンスキーが必要だったりと、学習には少しハードルの高い部分があるのではと感じました。
そこでこの記事では、LangGraphのワークフロー制御機能のみに絞り解説することにしてみました。動かすことを重視するため、コード断片ではなく各機能を網羅的に解説できるような簡易ゲームを設計、実装してみました。AIモデルを呼び出す部分は含まれないので、OpenAIなどのアクセスキーは不要です。LangGraph以外はすべてPythonの標準ライブラリだけで動きます。
これにより、LangGraphのグラフ制御機能の範囲が明確化され、結果として他のAIエージェントのサンプルコードの読解がスムーズになると考えています。
PS > python.exe -V
Python 3.12.7
PS > pip.exe install langgraph
...
PS > pip.exe show langgraph | Select-String Version
Version: 0.2.48
概要
三目並べ

題材として、コンソールで動作する三目並べを取り上げます。

記事中にあるソースコードの全体はこちらに置いています。
フローチャートは以下の通り。
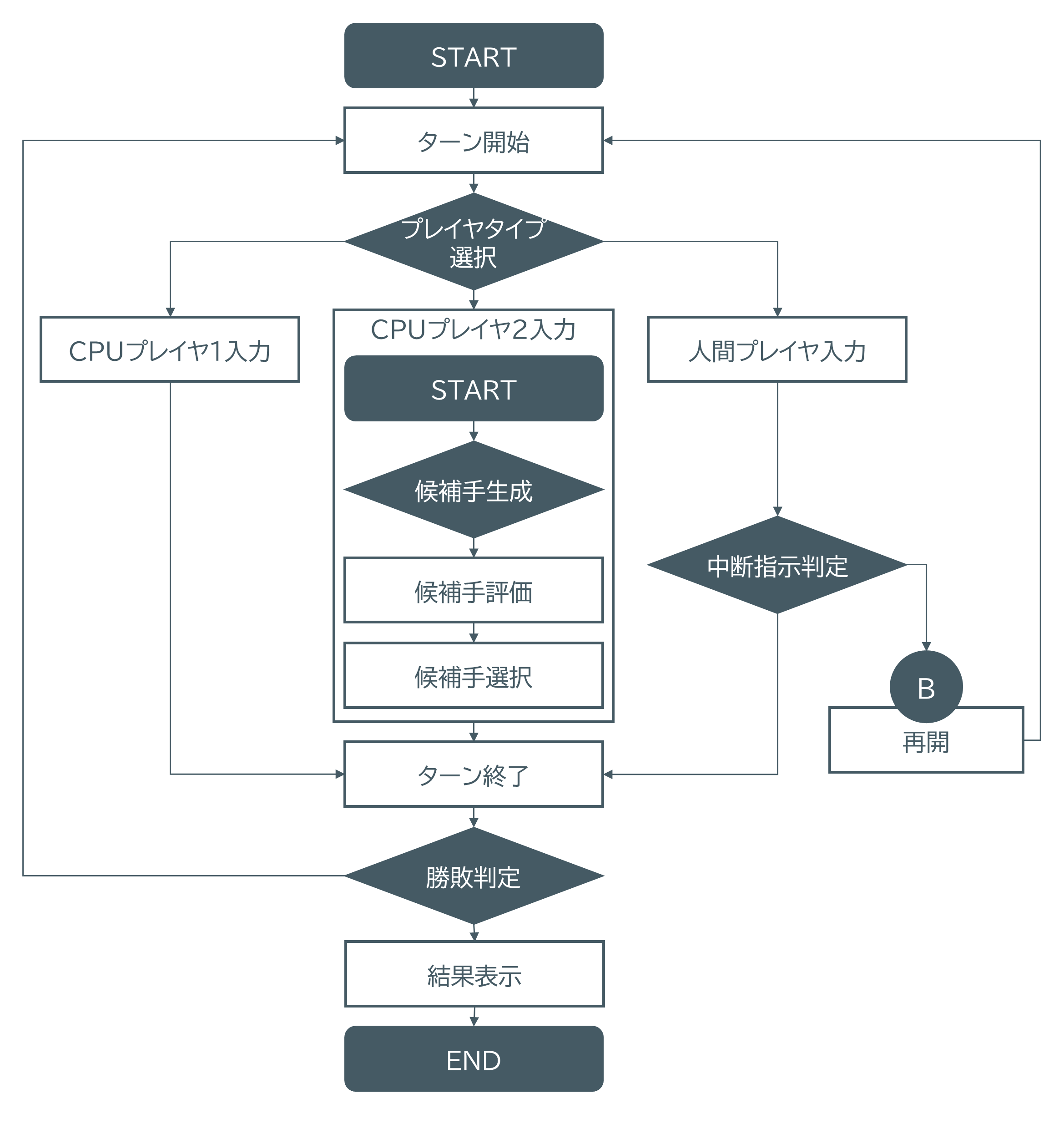
一回のループで一回のターンを実施します。特徴的な部分としては、CPU1、CPU2、人間の三種類のプレイヤタイプを選択できるようにします。CPUプレイヤ1はランダムに手を選択するだけですが、CPUプレイヤ2は並列処理を使った少し高度なことを行います。CPU対CPUの対戦も可能です。人間プレイヤタイプを指定すると人がプレイできます。さらに、ゲームを中断しまた再開できるようにしています。
機能マッピング
この三目並べが、LangGraphの機能をどのように利用しているかは以下の通りです。可能な限り網羅的に利用するよう設計しています。
ノード, エッジ, ステート
ゲームの骨格部分は、LangGraphの基本機能であるノードとエッジ、そしてステートを使います。
レデューサ関数, 条件分岐エッジ, コンフィグ
プレイヤが手を打った時に盤面を更新する部分は、リストを更新するレデューサ関数を使って実現します。また、勝負がついたり引き分けたりした場合はゲームを終了させる、そうでなければ継続するという条件分岐の部分は、条件分岐エッジを使います。
先手後手ともにCPUプレイヤタイプを指定した場合は、人の操作を介さず自動的にゲームが進むのですが、ここで必要となるLangGraphの内部制約設定を変更するため、コンフィグ機能を扱います。
ブレイクポイント, チェックポインタ, 永続化
人間プレイヤタイプの場合、長考したいこともあるかもしれません(?)。そこで、途中でゲームを中断できるようにします。Human in the loopと呼ばれるパターンです (ただし、中断中に盤面を更新するといったことは行わないので、パターンの一部だけです)。これにはブレイクポイント機能を利用します。また、中断からの再開には、チェックポインタによる永続化機能を用います。また、チェックポインタ機能に付随して、スレッドIDにも触れます。
動的並列化 (Send)
CPUプレイヤ2は、盤面の状況に応じて次の手の候補を動的に生成し、各候補を並列で評価しその評価値に基づいて次の手を決定します。この機能を通じて、Send機能による動的並列処理を説明します。
サブグラフ, マルチスキーマ
三目並べは、処理としてはそれなりに複雑ですので、サブグラフ機能とマルチスキーマ機能を使い、大規模なグラフを扱いやすくする例を示します。
カバーしていない機能
本記事では、以下の項目はカバーしていません。
-
イベントのストリーミングおよび非同期呼び出し機能
astream_eventsまわりのAPIが執筆時点でベータ版であること、これらの機能を活かすためにはサンプルプログラムをそこそこ大きく変えないといけないため -
動的ブレイクポイント
単純に使う場所がなかったため -
ストレージ
LangGraph自体を拡張するための機能であるため -
グラフ可視化
画像生成のための標準外ライブラリインストールが必要であるのと、他の解説記事で多数取り上げられているため -
MessageGraph
AIモデルとの接続が必要となること、どう考えても三目並べで使う場所がないため
LangGraphの基礎

なんか、ペンが中指を突き抜けていますがそれはともかく、LangGraphワークフローは、「処理」とそれらの間の「矢印」、そして「状態」を組み合わせたものです。

「状態」とは、いくつかの変数やリストを束ねたものです。そして、その変数を読み込み更新する「処理」を「矢印」で相互に接続することでワークフローが形成されます。
ワークフローを開始すると、ステップと呼ばれる単位で「処理」が実行されます。最初のステップでは、STARTから「矢印」でたどれる「処理」が実行状態になります。複数の「処理」が一つのステップ内で実行状態になることもあります。実行状態になった「処理」は、「状態」から変数を読み取り、必要ならその値を更新します。そして実行状態を終わります。ここまでが一つのステップです。
実行状態が終わったら、「矢印」でたどれる次の「処理」が実行状態になり、同様に「状態」の読み取りと更新を行います。その繰り返しがENDまで到達し、実行状態になり得る「処理」がなくなればワークフローが終了します。
この「状態」「処理」「矢印」を、LangGraphではそれぞれステート(State)、ノード(Node)、エッジ(Edge)と呼びます。ステートとして束ねられている変数をチャネル(Channel)と呼びます。ノードとエッジを組み合わせたものをグラフ(Graph)と呼びます。[グラフ理論][wk-grph]からのメタファ的なものだと思いますが、グラフ理論とはあまり関係ありません。
三目並べを使った解説 (基本機能)
ステート
三目並べの盤面や現在のターンなどゲーム進行状態をステートで表現します。
データを格納できればPythonのどのデータ構造を使ってもいいのですが、TypedDictまたはPydanticのBaseModelのいずれかを継承したクラスにするのが慣習のようです。この記事は標準ライブラリ縛りで書いているのでここではTypedDictを使います。
import operator
from typing import TypedDict, Annotated
class GameState(TypedDict):
turn: int
board: Annotated[list[int], _update_board]
is_next_playerBLUE: bool
result: str
record: Annotated[list[str, int], _set_or_append]
チャネルturnはターン番号で、プレイヤが手を進める毎に増えていきます。
boardは長さ9(=3x3)の整数型リストで盤面の状態を表現します。プレイヤ二人をそれぞれ red(🔴)、blue(🔵)としそれぞれ-1または1を設定することとします。マークされていないところは0です。is_next_playerBLUEは今の手番を表すブール値です。
resultは通常Noneですが、盤面判定でプレイヤのいずれかが勝利したり引き分けたりといった判定がされると、その結果をここに記入します。
recordはどちらのプレイヤがどのマス目をマークしたかを記録していく棋譜用のリストです。
ノード
ノードはPythonの関数を使って、そのノードで処理したい内容をPythonの関数で記述します。ステートをパラメタとして受け取り、ステートの更新したい内容を返します。
例として、CPUプレイヤ1入力のノード関数です。返り値として、盤面の更新部分と、棋譜の追加分を返します。
def _get_cpu1s_input(game: GameState) -> dict:
player = __PLAYERS[game["is_next_playerBLUE"] * 2]
while True:
idx = random.randrange(0, 9)
if game["board"][idx] == 0:
break
return {
"board": (idx, player["index"]),
"record": (player["index"], idx)
}
レデューサ関数
チャネルboardとrecordは、Annotated型ですがその第二パラメタでレデューサ関数を指定しています。
さきほどノード関数の処理から更新したい値を返しましたが、その値でチャネルをどのように更新するかはステートが決めます。その更新方法がレデューサ関数です。
 R: レデューサ関数
R: レデューサ関数
何も指定しない場合は上書き更新になるので、リストの追加・削除など上書き以外の操作を行いたい場合はレデューサ関数を指定します。レデューサ関数は、パラメタとしてチャネルの値と(ノード関数から返される)更新値を受け取り、更新後のチャネル値を返す二項関数です。
ここではプレイヤが指定したマス目に対応するboardチャネルの特定の要素だけを更新するレデューサ関数を自作しています。
def _update_board(brd: list, pv: Union[list, tuple]) -> list[int]:
if type(pv) == list:
brd = pv
elif type(pv) == tuple:
brd[pv[0]] = pv[1]
return brd
_update_board関数は、盤面内の更新位置インデックスと更新後の値の組(タプル)を渡すと、その位置の要素だけを上書きします。例えば、左上角のマス目をプレイヤ青がマークする場合は、pvに(0, 1) を渡します。あるいはリスト型を渡すことで単純上書きも可能です。これはinvoke()での初期化で利用しています。
もう一つは、recordで指定している_set_or_append関数で、棋譜への追加と上書きができるようにしています。これはサブクラスのところで説明します。
グラフ
ワークフロー部分は、ノードとエッジを組み合わせて作成します。典型的な実装パターンを挙げておきます。
from langgraph.graph import StateGraph, START, END
def define_graph():
builder = StateGraph(GameState)
builder.add_node("node1", ノード関数1)
builder.add_node("node2", ノード関数2)
..
builder.add_edge(START, "node1")
builder.add_edge("node1", "node2")
builder.add_edge(...)
builder.add_conditional_edges(...)
builder.add_edge(..., END)
return builder.compile()
graph = define_graph()
graph.invoke(チャネル初期値, コンフィグ)
先ほど定義したステートクラスGameStateを指定したStateGraphをインスタンス化し、これにノードやエッジを追加していきます。
ノードの追加はadd_node()で行います。ノード名とそのノードで実行されるノード関数を指定します。ノード名を省略すると、ノード関数の名前がノード名として用いられます。
なお、この関数には、ノード関数の呼び出しが失敗した場合のリトライ条件などを指定するretryオプションを指定することができます。このパラメタを指定する機会はあまりないと思いますが、ディフォルトでどのような設定がされているかは知っておいて損はないと思います。詳細は、How-toガイドHow to add node retry policies を参照ください。
| パラメタ | 解説 | ディフォルト値(現時点) |
|---|---|---|
| initial_interval | 最初のリトライ前の待ち時間 | 0.5秒 |
| backoff_factor | リトライ毎に間隔を拡げていくときの倍率 | 2.0倍 |
| max_interval | リトライ間の最大秒数 | 128秒 |
| max_attempts | 最大リトライ回数 | 3回 |
| jitter | リトライ間の時間にランダムな揺らぎを与えるかどうか | 与える |
| retry_on | リトライする例外のリストorリトライするしないを決める関数 |
add_edge()でノードとノードの間の実行順序を指定していきます。STARTとENDは、文字通りフローの最初と最後を表すノードです。add_conditional_edges()はこの後説明します。
最後にcompile()メソッドで、グラフを実行可能な形式に変換し、invoke()で呼びだすとワークフローが実行されます。
条件分岐エッジ
ステート (または後述のコンフィグ) に基づいて、次のステップで実行するノードを変更できるエッジです。
三目並べの中では、例えばゲームの勝敗が決まった時はループを抜ける分岐などで使っています。
def _define_graph(checkpointer):
...
builder.add_node("end_turn", _end_turn)
...
builder.add_conditional_edges("end_turn", _judge_game, {
"next_turn": "start_turn",
"game_over": "show_result"
})
def _judge_game(game: GameState) -> str:
if game["result"] is None:
return "next_turn"
else:
return "game_over"
ノードend_turnで盤面判定を行い、勝敗あるいは引き分けであることがわかればステートのresultチャネルに文字列を入れます。ノードend_turnの処理が終わると、add_conditional_edges()の二番目のパラメタで呼び出される_judge_game関数は文字列game_overを返します。この文字列は第三パラメタによりノード名show_resultにマッピングされ、これにより結果表示ノードに遷移します。
add_conditional_edges()の一般的な設定方法は以下の通りです。
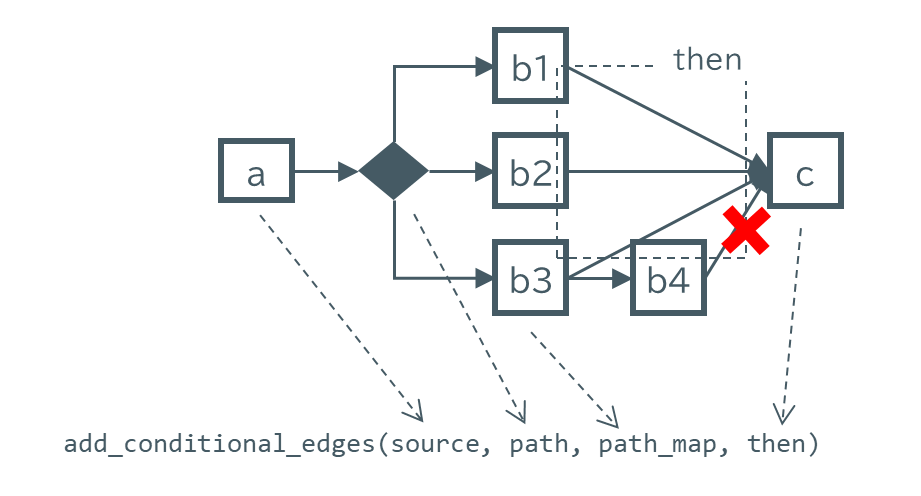
分岐元となるノードをsourceに指定します(ここではa)。どの分岐に進むかの条件判断を行う関数をpathに指定します。この関数の出力と、実際に分岐するノード名のマッピングディクショナリをpath_mapに指定します。省略すると、関数の出力値がそのまま分岐先ノード名と解釈されます。
あまり使う機会もないと思いますが、最後のパラメタthenにノード名を指定しておくと、分岐先からそのノードに遷移するエッジを自動追加してくれます。図の例だと点線で囲ったエッジを暗黙的に追加してくれるので、add_edge("b1", "c") や add_edge("b2", "c") をいちいち書かなくてよくなります。ただ、b3からb4にエッジを指定していても、b4からcのエッジは作ってくれません。b3からcへのエッジになります。
コンフィグ
recursion_limit
ワークフローを起動するinvoke()では、以下のようにrecursion_limitパラメタを設定しています。
game_graph.invoke(init_vals, config={
"recursion_limit": 40,
})
この設定がないと、上記のコンフィグでred, blue双方のプレイヤをともにCPUに指定した場合、高い頻度で以下のエラーが発生します。
Traceback (most recent call last):
...
packages/langgraph/pregel/__init__.py", line 1348, in stream
raise GraphRecursionError(msg)
langgraph.errors.GraphRecursionError: Recursion limit of 25 reached without hitting a stop condition. You can increase the limit by setting the `recursion_limit` config key.
For troubleshooting, visit: https://python.langchain.com/docs/troubleshooting/errors/GRAPH_RECURSION_LIMIT
これはゲームが長引いた時、エラーメッセージに書かれているようにステップ数上限である25回に達してしまったことによります。そこでコンフィグパラメタのrecursion_limitの設定値を多めに設定しています。
これでゲームがもつれても、問題ありません。
コンフィグパラメタ
コンフィグは、いわゆる設定値です。設定できるパラメタは二種類あり、recursion_limitのようにLangGraphの挙動を変更するシステムパラメタと、任意パラメタに分かれます。
game_graph.invoke(init_vals,
config={
"recursion_limit": 40,
"configurable": {
"thread_id": thread_id,
"red": "cpu1",
"blue": "human",
}
confugurableの下に設定されたパラメタが任意パラメタで、三目並べではコンフィグでどのプレイヤタイプを実行するかを指定するために用いています。この例ではプレイヤredをCPU1プレイヤ、blueを人間に指定しています。なお、thread_idについては後述します。
コンフィグは、ノード関数のパラメタとして渡されます。
def _select_playertype(game: GameState, config: RunnableConfig) -> str:
player = __PLAYERS[game["is_next_playerBLUE"] * 2]
return config["configurable"][player["id"]]
なお、このRunnableConfigはLangChain Coreのクラスです。システムパラメタとしてどのような値が利用できるかはLangChainのドキュメントに記載されています。
コンフィグスキーマ
LangGraphのガイドには、コンフィグがどのようなパラメタを受け付けるか明示するために、コンフィグ用スキーマを設定することができると記載されているので、三目並べでも利用しています。
class TictactoeConfig(TypedDict):
thread_id: str
red: Literal["human", "cpu1", "cpu2"]
blue: Literal["human", "cpu1", "cpu2"]
def _define_graph(checkpointer):
# Main graph
builder = StateGraph(GameState, TictactoeConfig)
ですが、このスキーマを指定したところで、スキーマチェックをしてくれるわけではないので、分かりやすくていいねくらいだと思います。参考まで。
ブレイクポイント
ワークフローを中断する機能です。本記事の三目並べでは再開ノードの直前に設定しています。図では「B」の位置であり、そのひとつ前の人間プレイヤ入力ノードで中断コマンドが入力された場合、中断指示判定の分岐により右のエッジに遷移しワークフローが終了します。

ブレイクポイントは、グラフをコンパイルする際に、interrupt_beforeまたはinterrupt_afterにノード名のリストを渡すことで、それぞれノードの直前または直後に中断するよう指定できます。
def _define_graph(checkpointer):
...
return builder.compile(interrupt_before=["resume_game"])
チェックポインタ
ワークフローを再開するには、ワークフローが中断前にどのような状態だったか、どこで中断したかなどのワークフローの実行中情報が必要です。LangGraphには、ステップ毎にワークフローの状態や進行状況をスナップショットとして保存するチェックポインタ機能があります。
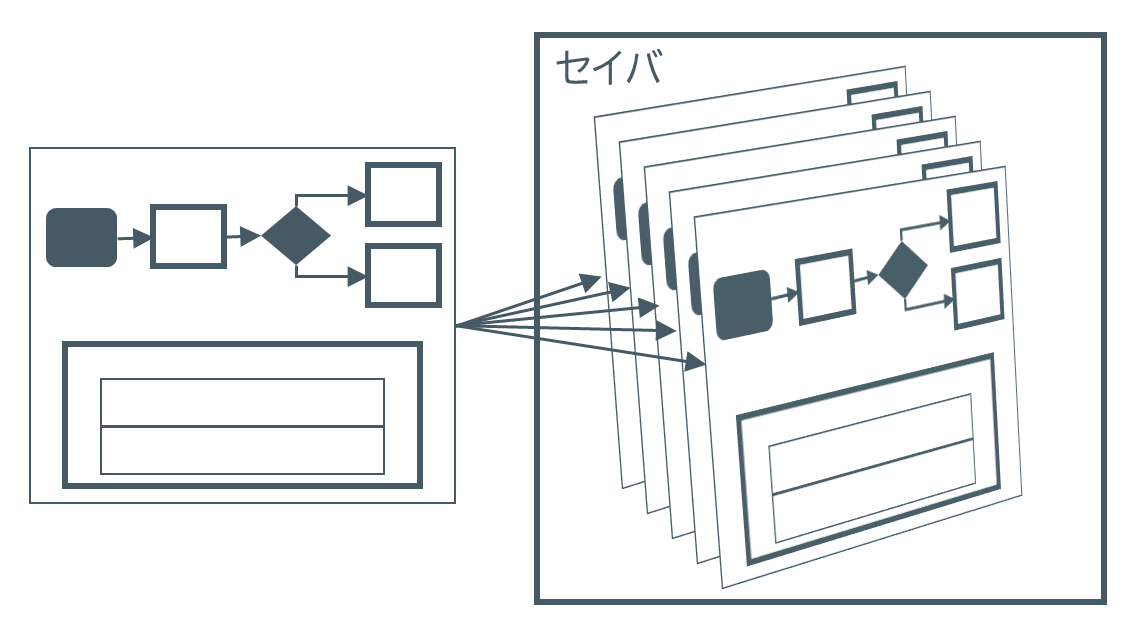
保存先をセイバ(Saver)と呼びますが、記事の執筆時点で以下の四種類のセイバが提供されています。
この記事では、Sqliteセイバを使います。pipコマンドでインストールできます。(ない場合は、sqlite自体もインストールが必要です)
PS > pip install langgraph-checkpoint-sqlite
実行時情報の保存時、または再開時には、どの実行情報化を示すスレッドIDを指定する必要があります。自動的に採番してくれることはないので、利用する側で生成する必要があります。
ワークフローを新規開始するのか、中断した時点から再開するのかは、invoke()で開始するとき、パラメタの以下の組み合わせに決まります。
inputパラメタ |
configurable.thread_id |
|
|---|---|---|
| 新規開始 | 初期値 | 指定しない |
| スナップショットからの再開 | None | 記録に使ったスレッドID |
ここでは、スレッドIDはUUIDを使っています。
from langgraph.checkpoint.sqlite import SqliteSaver
import uuid
DB_NAME = "tictactoe.sqlite"
def _define_graph(checkpointer):
...
builder = StateGraph(GameState, TictactoeConfig)
...
return builder.compile(checkpointer=checkpointer, interrupt_before=["resume_game"])
def run(thread_id):
if thread_id is None:
init_vals = { ... }
thread_id = str(uuid.uuid1())
else:
init_vals = None
with SqliteSaver.from_conn_string(DB_NAME) as chkpointer:
game_graph = _define_graph(chkpointer)
print(f"thread ID={thread_id}")
game_graph.invoke(init_vals,
config={ ...
"configurable": {
"thread_id": thread_id,
...
})
# 新規実行
run(None)
# 再開
# run("スレッドID")
ステップ毎にスナップショットを書き込むので、ワークフローを実行中は常にデータベースを開いておく必要があります。上記のコードでは SqliteSaver.from_conn_stringで取得したチェックポインタchkpointerは、表面的にはinvoke()では使われていないように見えますが内部で参照されていて、仮に呼び出し前にデータベースを閉じると、エラーが発生します。
動的並列化 (Send)
条件分岐する際に、その分岐の数や分岐条件が実行時に決まるようなエッジです。
三目並べのCPUプレイヤ2は、その時点で空いているマス目すべてについて評価を行い、その評価値が最も高いマス目を選択するというアルゴリズムを実装しています (ただし、評価はランダム値なので、強さとしてはCPUプレイヤ1と同じ)。
空いているマス目の数はターンごとに異なるため、エッジの数を事前に定義することは困難です。こういった分岐の数が動的に変化する場合にSend機能を使います。
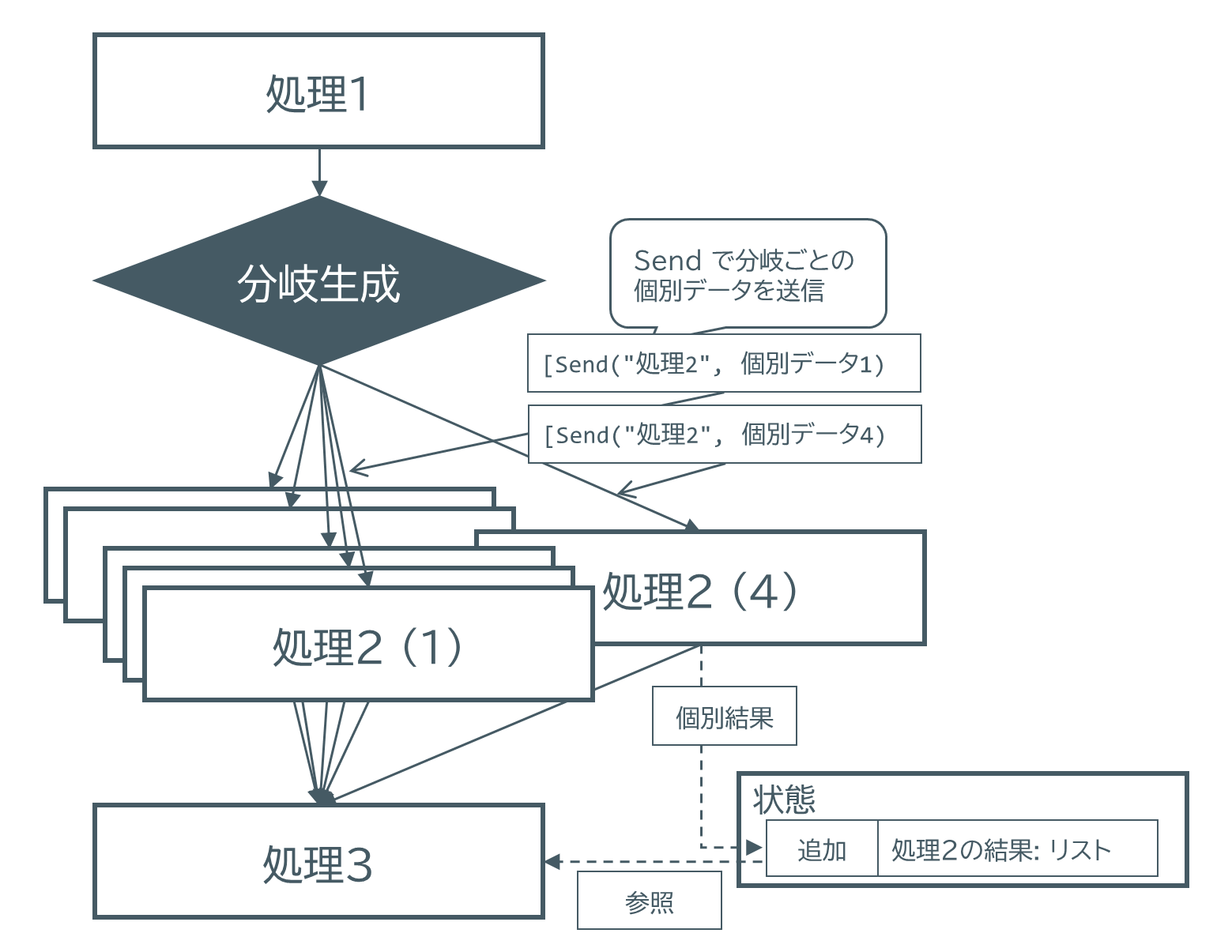
実装方法が少し複雑ではあるのですが、パターンなのでその通りに記述すれば簡単です。
まず、分岐生成の場所と生成方法の指定はadd_conditional_edges()を使います。
m2builder.add_conditional_edges(START, _generate_cpu2s_options)
m2builderは、後述のサブグラフで説明します。ここではあまり関係ありません。とにかく、STARTの直後に、分岐を生成するための関数を呼び出すことを指定しています。その条件分岐関数は、以下のとおりです。
from langgraph.types import Send
def _generate_cpu2s_options(game: GameState) -> dict:
board = game["board"]
def get_indexes_of_unmarked():
return map(lambda p: p[0], filter(lambda v: v[1] == 0, enumerate(board)))
return [Send("evaluate_cpu2s_option", n)
for n in get_indexes_of_unmarked()]
通常の条件分岐関数は最後に遷移先ノード名を返しますが、 動的分岐の場合はSendを使って、遷移先ノードとその分岐での個別データの組を送ります。この個別データはステートとは違い、他の分岐先とは共有されません。ここではマス目インデックスnが固有データです。
def _evaluate_cpu2s_option(pos_candidate: int):
return {
"m2scores": (pos_candidate, random.randrange(0, 100))
}
受け取った固有データは並列に処理され、結果を返します。結果は、ここではm2scoresというリストに評価値(ランダムですが)を追加されます。一つの分岐はタプルを一つ返すだけですが、複数の分岐があるためリスト型にする必要があります。
class M2Strategy(TypedDict):
...
m2scores: Annotated[list[int, int], _set_or_append]
リストに評価値を集約した後の処理ノードです。
def _select_cpu2s_input(m2s: M2Strategy):
player = __PLAYERS[m2s["is_next_playerBLUE"] * 2]
option_having_maxscore = (max(m2s["m2scores"], key=lambda s: s[1]))[0]
return {
"board": (option_having_maxscore, player["index"]),
"record": (player["index"], option_having_maxscore),\
"m2scores": []
}
リストに集約された評価値を比較し、CPUプレイヤ2の手で盤面を更新します。
上記のレデューサ関数_set_or_appendはサブグラフのところで説明しますが、リスト全体の上書きと追加の両方ができる関数です。通常は追加を行いますが、評価が終わったらクリアしないと次のCPU2のターンでまた評価値が末尾に追加されてしまうので、この時点で空リストにより上書きしています。
三目並べを使った解説 (大ステート向け機能)

これまで説明したLangGraphの機能で、おおよその三目並べあるいはAIエージェントを作成することができるのですが、ここから後はサイズの大きなステートやグラフを扱う場合に便利な機能、サブグラフとマルチスキーマについて書いてみます。
サブグラフ
小さなグラフを大きなグラフの一部として扱う機能です。複雑なグラフをまとめたり、繰り返し利用されるグラフをサブグラフとして再利用したりすることができます。
LangGraphの公式サイトでは、サブグラフのパターンが二つ紹介されています。
ただし後者は、本当にノード関数から別のグラフをinvoke()で呼び出しているだけであり、しかもノード関数にはステートとコンフィグのパラメタしか渡せないという制約を回避するため、公式サイトのサンプルコードは、その呼びだすグラフをグローバル変数経由で渡すといういまいちな方法で実装しているので、この記事でそれを参照してくださいとお勧めすることはできません。この記事では前者のみ取り上げます。
やり方自体は簡単で、コンパイルしたグラフを別のグラフのノード関数として指定するだけです。
def _define_graph(checkpointer):
# Sub graph
m2builder = StateGraph(M2Strategy)
m2builder.add_node("evaluate_cpu2s_option", _evaluate_cpu2s_option)
m2builder.add_node("select_cpu2s_input", _select_cpu2s_input)
m2builder.add_conditional_edges(START, _generate_cpu2s_options)
m2builder.add_edge("evaluate_cpu2s_option", "select_cpu2s_input")
m2graph = m2builder.compile() # これがサブグラフ
# Main graph
builder = StateGraph(GameState, TictactoeConfig)
...
builder.add_node("get_cpu2s_input", m2graph) # ノード関数の部分にサブグラフを指定
return builder.compile(checkpointer=checkpointer, interrupt_before=["resume_game"])
メインのグラフでCPU2プレイヤ入力ノード(get_cpu2s_input)に遷移したところで、サブグラフのSTARTから遷移が始まり、サブグラフが終わるとメイングラフの遷移に戻ります。
上記のコード例はサブグラフとメイングラフをあまり明確に分けずに書いているためあまりよい例ではないですが、もう少し書く場所を分けるなど整理して書くとコードがすっきりすると思います。
ここで一つ注意点があります。ステートの持つリスト型のチャネルをメイングラフとサブグラフで共有している場合、LangGraphは想定しない振る舞いをすることがあります。
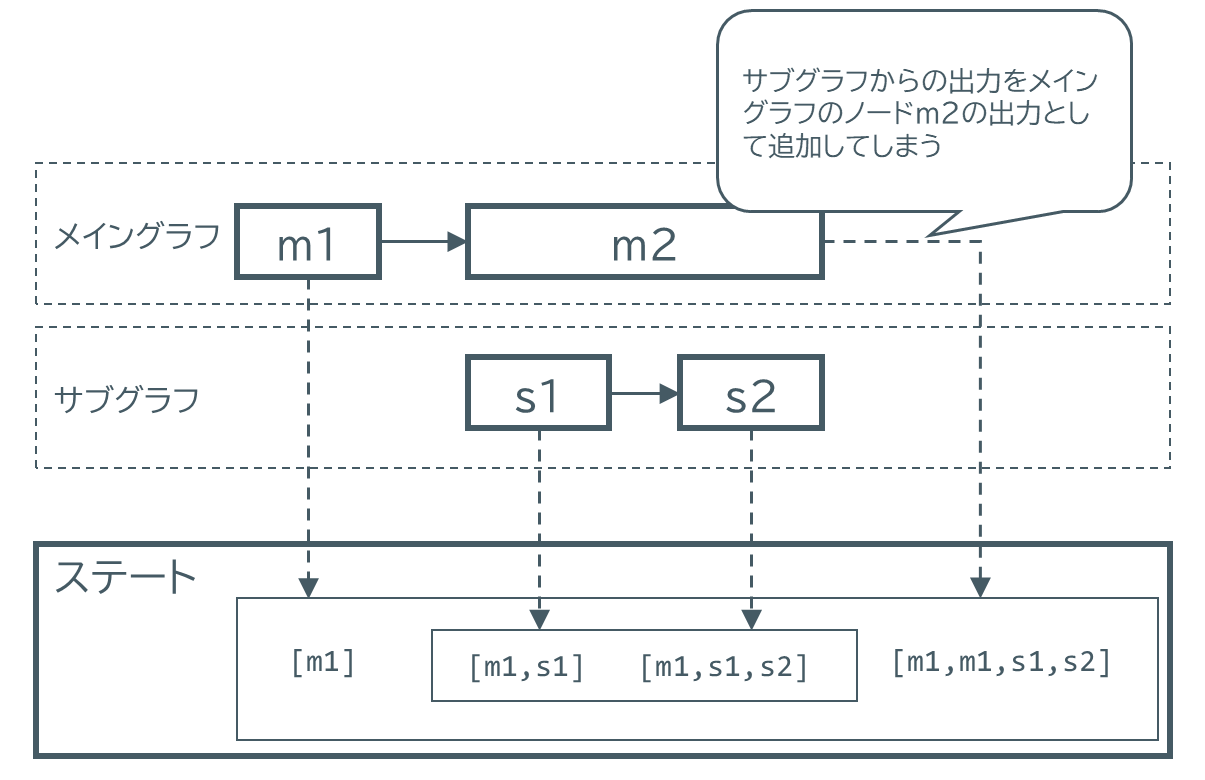
例えば、上図のようにノードm2のノード関数としてサブグラフを設定し、またレデューサ関数としてoperator.addを利用しているとします。メイングラフでm1が追加された後、サブグラフに遷移します。サブグラフのノードs1とs2でそれぞれチャネルに値を追加し、そしてメイングラフに戻ってくるのですが、メイングラフが改めてサブグラフの出力をノードm2の出力として追加してしまうため、結果としてステートの値はm1,m1,s1,s2となります。おそらくm1,s1,s2となることを期待したはずで、これは意図した結果ではないはずです。
サブグラフの結果がメイングラフのノードの返り値として二重に追加される例
import operator
from langgraph.graph import StateGraph, START, END
from typing import TypedDict, Annotated
class SubState(TypedDict):
track: Annotated[list[str], operator.add]
class MainState(TypedDict):
track: Annotated[list[str], operator.add]
def s1(s: SubState):
return {"track": ["s1"]}
def s2(s: SubState):
return {"track": ["s2"]}
def m1(s: MainState):
return {"track": ["m1"]}
def define_graph():
subgraph = StateGraph(SubState).\
add_node(s1). \
add_node(s2). \
add_edge(START, "s1"). \
add_edge("s1", "s2"). \
add_edge("s2", END).compile()
return StateGraph(MainState). \
add_node(m1). \
add_node("m2", subgraph). \
add_edge(START, "m1"). \
add_edge("m1", "m2"). \
add_edge("m2", END).compile()
graph = define_graph()
print(graph.invoke({"track": []}))
# 実行結果:
# {'track': ['m1', 'm1', 's1', 's2']}
この問題を回避するため、三目並べではレデューサ関数としてoperator.addではなく自作のレデューサ関数を使っています。この関数はスカラー値なら追加、リスト型なら置き換えを行うものです。ノードm2からの返り値はリストなので置き換えになります。
def _set_or_append(lst: list, v: Union[list, str]) -> list:
if type(v) == list: # リスト型の場合は追加ではなく置き換え
return v
else: # スカラー値の場合は追加
return lst + [v]
マルチスキーマ
ステートのすべてのチャネルがすべてのノードで使われるわけではありません。ステートが大きくなっていくと、特定のノードでしか使わないチャネルも出てくるはずです。こういった特定用途のチャネルがその目的とは関係ないノードで扱えるようだと、プログラミング言語におけるグローバル変数のようにバグのもとになりかねません。
チャネルの一部を隠したり、特定の機能で使うチャネルをまとめたりしたいときにスキーマを使います。スキーマとは、要はステートクラスのことです。
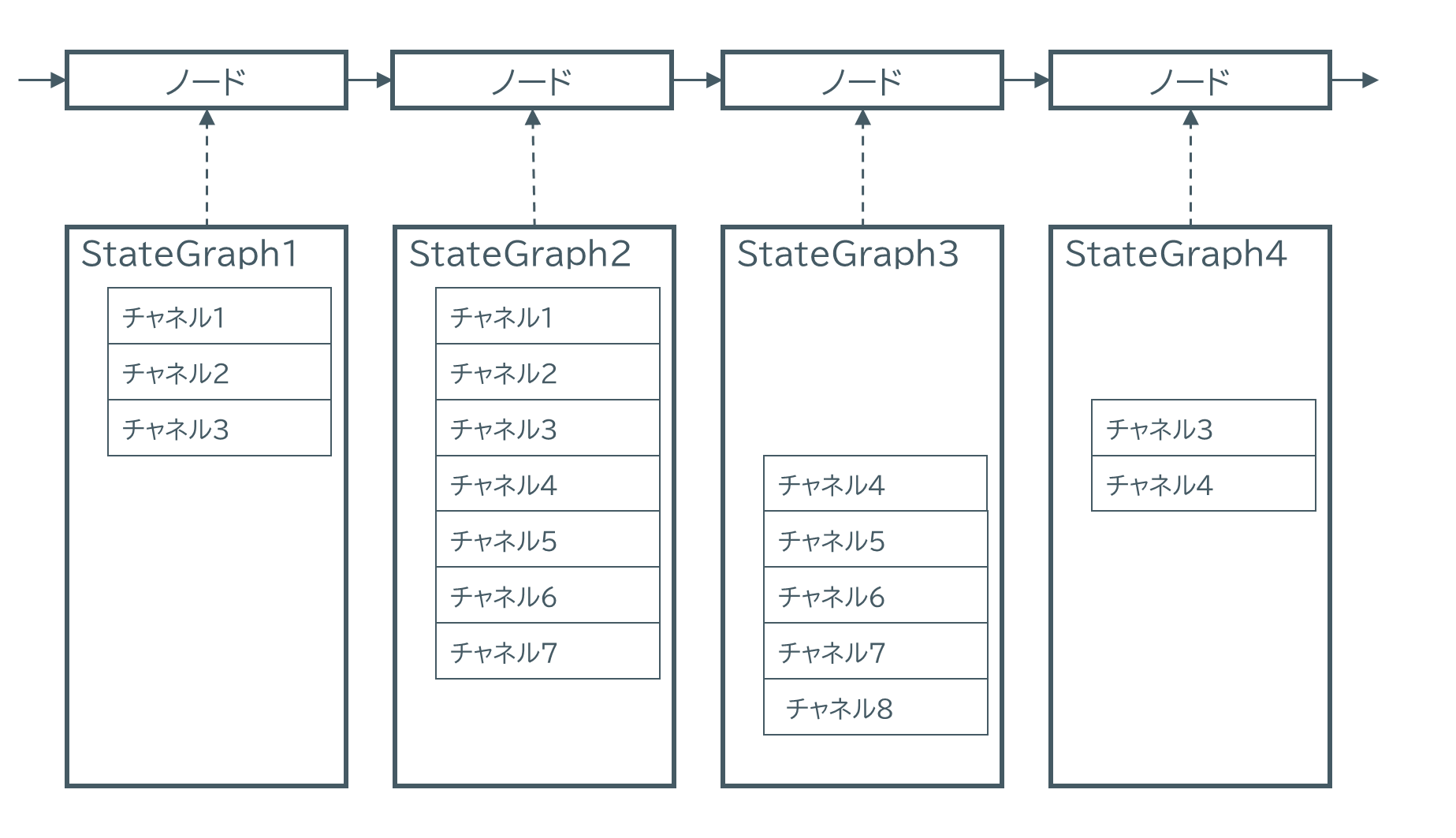
上図では一つのグラフの中で、StateGraph1から4まで四つのスキーマ (ステートクラス) があります。四つありますが、いくつかのチャネル名が共有です。
一つのグラフの中では、チャネルの名前が同じであればスキーマに関係なくノード間で値が共有されます。StateGraph1のチャネル3に値を格納すると、最後のノードでのチャネル3にもその値は共有されます。
逆に考えると、このグラフの中ではチャネル1から8までの大きなステートの上で動作しつつも、それぞれのノードでは、その八つのチャネルのうち処理に必要な部分だけを定義したStateGraph1,2,3,4により局所化が実現できているということです。
三目並べでも、この仕組みを利用しています。Send機能の節で登場したm2scoresは、CPUプレイヤ2の複数の手候補を評価するためだけに使われていて、ワークフロー全体で使えるようにする必要はありません。そのため、CPUプレイヤ2のフローの部分だけに必要なチャネルをM2Strategyという別スキーマに分け、メインの処理では見せないようにしています。
class M2Strategy(TypedDict):
board: Annotated[list[int], _update_board]
is_next_playerBLUE: bool
record: Annotated[list[str, int], _set_or_append]
m2scores: Annotated[list[int, int], _set_or_append]
また、マルチスキーマのうち、グラフを呼び出すときの入力パラメタに対するスキーマを入力スキーマ、グラフから返ってくる値に対するスキーマを出力スキーマと言います。これらはStateGraphをインスタンス化するときのパラメタに指定することができます。
graph = StateGraph(StateGraph1, input=StateGraph1, output=StateGraph4). \
add_node(...). \n
add_edge(...).compile()
output = graph.invoke(input, ...)
それぞれinvoke()メソッドの入力パラメタ(input)、およびこのメソッドの戻り値(output)に対するスキーマになります。
おわりに
この記事では、三目並べゲームを題材に、LangGraphのワークフロー制御機能だけを解説しました。
ここまで理解できれば、冒頭に書いたように他のLangGraphの記事やサンプルコードを読んだときに、各部分の役割が区別でき、理解が進むのではと考えています。