「機械学習モデル$f:{\cal X} \rightarrow \mathbb{R}$に$\boldsymbol{x} = (x_1, x_2,\ldots, x_M)$を入力するとき,$\boldsymbol{x}$のどの特徴が重要なのか」
この問いに明確に答えてくれるのがSHAP(SHapley Additive exPlanation)です.
NIPS2017の論文で発表されたこの手法は,魅力的なPython実装のおかげもあり一気に広まっているようです.遅ればせながらこのSHAPについて勉強したのでまとめます.
ただ,SHAPについての解説は既にQiitaを含めたくさん公開されています.
そこで,ここでは私が論文や解説記事を読んでもすんなりと理解できなかった部分を自分の言葉でまとめてみました.
特に,同筆者の翌年の論文で提案された決定木に対するSHAPであるTreeExplainerの解説が日本語ではそれほど見当たらなかったので,具体例や図を交えながら説明してみます.
NIPS2017の論文では様々な機械学習モデルの説明が可能なKernel SHAPという手法が提案されていました.それなのになぜ決定木に対するSHAPが翌年に提案されたのでしょう?それは,Kernel SHAPが近似計算を含んでいるため正確性に欠け,かつ,計算速度も遅いからです.逆にいうとTree SHAPは高速かつ正確に特徴重要度を算出できます.
なお,理解がおかしい箇所があればご指摘いただけると幸いです.
また,一部元の論文とは式の表記(文字など)を変えている部分があるのでご留意ください.
SHAPとは
とはいえSHAPをまだ知らない人・名前だけは聞いたことがある人など様々だと思うので,簡単にSHAPの導入を行います.
SHAPとは,機械学習モデル$f$の$\boldsymbol{x}$に関する特徴重要度を算出し,それにより学習モデルの出力の根拠を説明しようという手法です.GitHubで公開されている以下の図が非常に分かりやすいです.

この特徴重要度とは何でしょうか?
SHAPでは入力$\boldsymbol{x}=(x_1,x_2, \ldots, x_M)$の各特徴$i \in N = \{1, 2, \ldots, M\}$が協力して出力$f(\boldsymbol{x})$を実現していると考えます.この発想が,特徴重要度とゲーム理論を結びつけています.
「$M$人からなるチーム$N=\{1, 2, \ldots, M\}$がある協力ゲームを行った結果,利得$v(N) \in \mathbb{R}$を得たとき,各プレイヤー$i \in N$の分け前$\phi_i \in \mathbb{R}$をどうするか?」
という問題が実は,
「$M$個の特徴が協力して出力$f(\boldsymbol{x})$を実現した結果,各特徴$i$の特徴重要度$\phi_i \in \mathbb{R}$をどう算出するか」
という問題と全く同じ構造になっているんです!
協力ゲームにおける利得の分配
協力ゲームにおける分け前は次のShapley値で決めることができます.
$$
\phi_i = \sum_{S \subseteq N \setminus \{i\}} Pr(S) \left(v(S\cup \{i\}) - v(S)\right)
$$
ただし
- $S$ : 集合$N$の部分集合(プレイヤー$i$は含まれない)
- $v(S)$ : チーム$S$で協力してゲームを行ったときの利得
- $v(S\cup \{i\})$ : $S$にプレイヤー$i$が加わった場合の利得
- $Pr(S)$ : チーム$S$が組まれる確率1
です.
以上を合わせると,Shapley値はチーム$S \subseteq N \setminus \{i\}$に対するプレイヤー$i$の貢献度の期待値であり,Shapley値を用いることで合理的に利得$v(N)$を分配することが可能になります.
なお,分配ですので$\sum_{i=1}^M \phi_i = v(N)$を満たします.
Shapley値を実問題で利用する場合の難しさ
ゲーム理論の考え方を使って特徴重要度を算出するという考え方は何となく分かりました.しかし,そんなにうまくいくのでしょうか?
実はShapley値を算出するにあたって重要な仮定があります.
それは全てのプレイヤーがゲームに関する知識を完全に共有していることです.より具体的には実現可能な全てのチーム$S \subseteq N$に関して$v(S)$の値が完全に分かっているという仮定がなされています. この仮定があるからこそ,貢献度$v(S \cup \{i\}) - v(S)$の期待値が計算できるのです.
$f(\boldsymbol{x})$の特徴重要度の話に移ります.
いま,$\boldsymbol{x}$のうち,特徴集合$S \subseteq N$だけを用いた場合の出力を$f_x(S)$と表現します.Shapley値における$v(S)$を$f_x(S)$で置き換えた2以下の値がSHAP値です.
$$
\phi_i(f; \boldsymbol{x}) = \sum_{S \subseteq N \setminus \{i\}} Pr(S) (f_x(S \cup \{i\}) - f_x(S))
$$
ゲーム理論における$v(S)$と$f_x(S)$が対応関係にあり,Shapley値を用いて特徴重要度を計算するためには,ありとあらゆる$S \subseteq N$に関して$f_x(S)$の値が分かっている必要があります.このとき$f_x(N) = f(\boldsymbol{x})$は自明です. しかし$S \neq N$の場合はどうするのでしょう?
簡単な例
イメージを固めるために,学習済みモデル$f$に対して$\boldsymbol{x}=(1.5,2.4, -3.3)$を入力した場合を考えてみましょう. この場合$N = \{1, 2, 3\}$です.
$S=\{1, 2, 3\}$であれば$f_x(S) = f_x(N) = f(x)$となるので簡単に求めることができます.しかし,残りの$2^3-1 = 7$通りある$S$に対する$f_x(S)$も求めなければなりません.
例えば$S = \{1, 2\}$の場合には,$f_x(\{1, 2\}) = f(1.5, 2.4, *)$を求めたいです.ここで$*$はdon't careの記号です3.
やりたいことは伝わったでしょうか?
従来の研究
実はShapley値を使って特徴重要度を算出しようという研究は過去にもあり,SHAPの論文でも触れられています.その研究では$f_x(S)$を非常に素直な方法で計算していました.
その方法とはあらかじめ特徴の集合$S$だけを用いて予測モデルを訓練しておくという方法です4.
上の例のように$N=\{1, 2, 3\}$であれば$2^3-1=7$通りの訓練を予め行っておきます.
しかしながらこの方法は計算コストが非常に大きいです.$M$が小さければどうにか計算できそうですが,$M$が10,20と大きくなると莫大な数のモデルを予め訓練しておくことが求められてお手上げです.
fx(S)を如何に推定するか
さすがに事前に$2^M$通りの学習モデルを用意するのは現実的ではなさそうです.
というわけで学習済みの$f$だけからどうにかして$f_x(S)$を推定しましょう.
SHAPの論文では,次の期待値計算を行います.
$$
f_x(S) = \mathrm{E}_\boldsymbol{Z} [f(\boldsymbol{Z}) | \boldsymbol{Z}_S =\boldsymbol{x}_S]
$$
ただし$\boldsymbol{Z}_S = \boldsymbol{x}_S$というのは,全ての$j \in S$に関して$Z_j = x_j$ということを表現しています(確率変数であることを協調するために$\boldsymbol{Z}$と大文字にしています).
上の式そのままでは少しイメージしづらいのでもう少し式展開してみましょう.
$$
\begin{align*}
f_x(S) &= \mathrm{E}[f(\boldsymbol{Z}) | \boldsymbol{Z}_S =\boldsymbol{x}_S] \\
&= \int_{{\cal Z}_\bar{S}} Pr(\boldsymbol{Z}_{\bar{S}}|\boldsymbol{Z}_S = \boldsymbol{x}_S)f([\boldsymbol{x}_S, \boldsymbol{Z}_{\bar{S}}]) d\boldsymbol{Z}_{\bar{z}}
\end{align*}
$$
ここで$\bar{S} = N \setminus S$です.また,$f([\boldsymbol{x}_S, \boldsymbol{Z}_\bar{S}])$は特徴集合$S$に関しては$\boldsymbol{x}_S$の値が入力されていて$\bar{S}$に関しては$\boldsymbol{Z}_\bar{S}$が入力されていることを意味します.
積分記号や文字がごちゃごちゃしてきましたが,要するに上で出てきた具体例でいうと
$f_x(\{1, 2\}) = f(1.5, 2.4, *)$の$*$の部分にあらゆる数値を入力して重み付き平均を取ることに相当します.ただ,この場合,$Pr(Z_3|Z_{1,2}=(1.5,2.4))$が計算できる必要があります.
どうやら$f_s(S)$を計算するためには$Pr(\boldsymbol{Z}_{\bar{S}}|\boldsymbol{Z}_S = \boldsymbol{x}_S)$が分かっている必要があるようです.
決定木なら特徴ごとの条件付き確率も計算できる
$N$のあらゆる部分集合$S$に関して$Pr(\boldsymbol{Z}_{\bar{S}}|\boldsymbol{Z}_S = \boldsymbol{x}_S)$を求めようとすると,結局$Pr(\boldsymbol{Z}) = Pr(Z_1, Z_2, \ldots, Z_M)$が分かっていなければなりません5. これは中々難しいでしょう.
しかし,決定木ならば$f(\boldsymbol{Z})$と$Pr(\boldsymbol{Z})$の両方を計算できます.
決定木に特化したSHAPがTreeExplainerです.
実はあらゆる機械学習モデルに対してSHAP値を求めるKernelSHAPや,深層学習モデルに対してSHAP値を求めるDeep SHAPといった手法もNIPS2017の論文内で提案されています.
しかしこれらの手法では$Pr(\boldsymbol{Z}_{\bar{S}}|\boldsymbol{Z}_S = \boldsymbol{x}_S)$の近似値からSHAP値を求めており,近似であるにも関わらず計算コストは高いです.
一方で同筆者が翌年発表した論文で提案されたTreeExplainerは$Pr(\boldsymbol{Z}_{\bar{S}}|\boldsymbol{Z}_S = \boldsymbol{x}_S)$を正確に求めるだけでなく低い計算コストでSHAP値を計算できます.
Kaggleでも大人気のXGBoostは決定木で構成される学習モデルです.
決定木は質的データ・量的データ問わずに利用可能であり,この決定木に対する∅SHAPが計算できれば実用性は非常に高いといえるでしょう.
具体例と絵で説明
決定木はIf-thenルールで表現されるモデルというイメージが強いですが,少し視点を変えてみましょう.
$$
f(\boldsymbol{x}) = w_{q(\boldsymbol{x})}
$$
$q : {\cal X} \rightarrow \{1, 2, \ldots, L\}$は入力$\boldsymbol{x}$が決定木のどの葉ノードに落ちるかを返し,$w_l \in \mathbb{R}$は$l$番目の葉ノードの値です.
こう表現すると,$q$は入力空間${\cal X}$を有限個($L$個)の領域に分割しているといえます.
${\cal X} \subset \mathbb{R}^2$の例で考えてみましょう.
二次元実数空間のサンプルを用いて決定木$f$を訓練したとします.
その結果,次のような決定木が得られました.
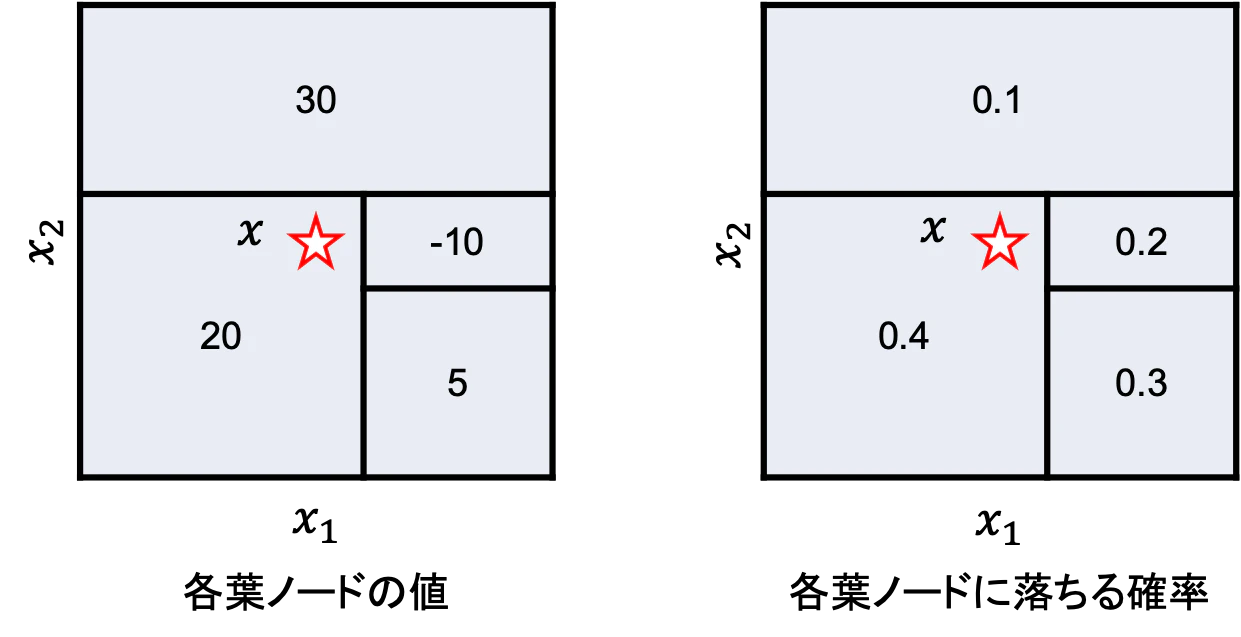
星マークが入力$\boldsymbol{x}$を表しています.
この決定木に対してSHAP値を計算してみます.
SHAP値を計算するためには$f_x(S)$を全ての$S \subseteq N$に関して求めなければなりません.
今回の場合,$S=\emptyset, \{1\}, \{2\}, \{1, 2\}$です.
fx(S)の計算
S=Nの場合
この場合は$f_x(S) = f(\boldsymbol{x}) = 20$です.
S={1}の場合
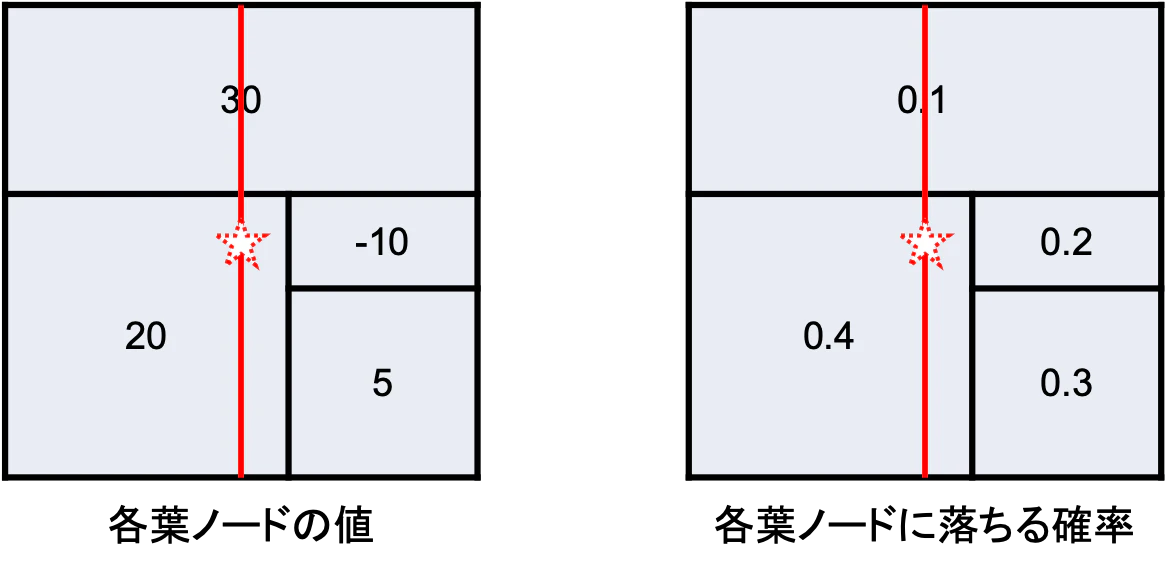
この場合,$x_1$の値だけが与えられていて$x_2$は不明です.
これはデータ$\boldsymbol{z}$が上図の赤線上のどこかに落ちることを意味しています.
そこで,赤線上のデータ$\boldsymbol{z}$に対する出力$f(\boldsymbol{z})$の期待値を計算します.
$$
f_x(\{1\}) = \frac{0.1 \times 30 + 0.4 \times 20}{0.1 + 0.4} = 22
$$
S={2}の場合
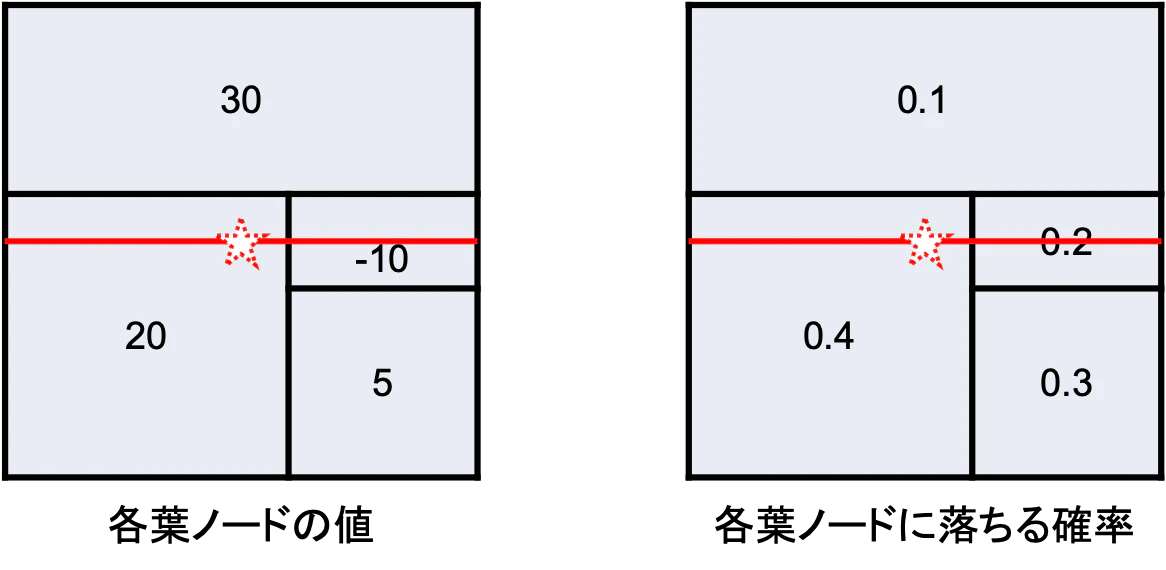
$S=\{1\}$の場合と同様に,赤線上のデータ$\boldsymbol{z}$に対する出力$f(\boldsymbol{z})$の期待値を計算します.
$$
f_x(\{2\}) = \frac{0.4 \times 20 + 0.2 \times (-10)}{0.4 + 0.2} = 10
$$
S=∅の場合
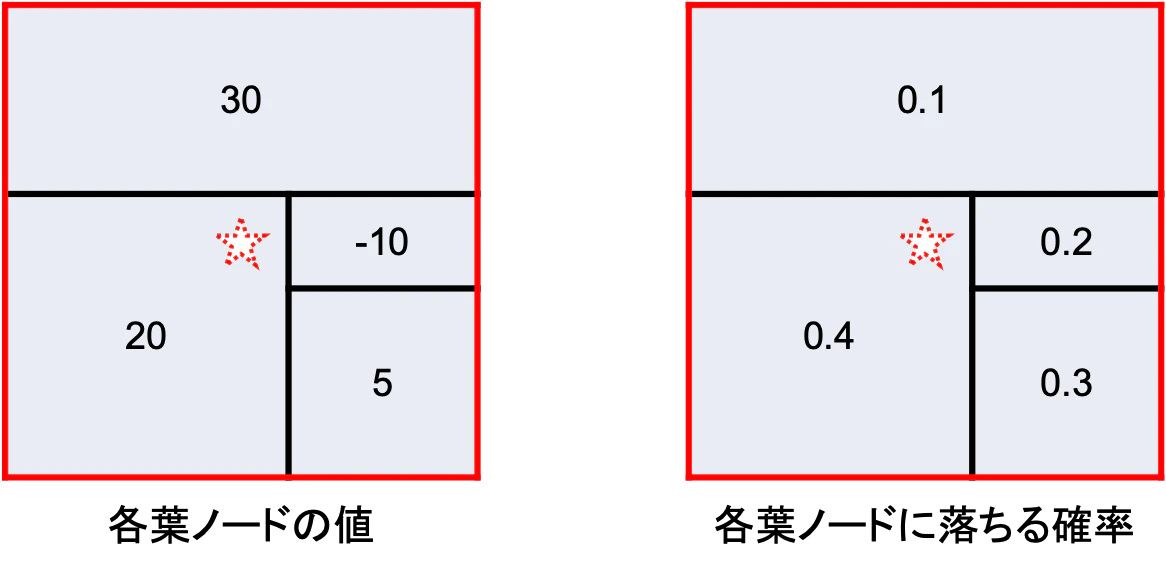
この場合$z$はどこに落ちるか全くわかりません.上図の赤枠内のどこかに落ちます.
$$
f_x(\emptyset) = \frac{0.1 \times 30 + 0.4 \times 20 + 0.2 \times (-10) + 0.3 \times 5}{0.1 + 0.4 + 0.2 + 0.3} = 10.5
$$
特徴重要度の計算
$2^2=4$通りの$f_x(S)$が計算できたので,SHAP値を計算できます.
$$
\begin{align*}
\phi_1 &= Pr(S=\emptyset)(f_x(\{1\}) - f_x(\emptyset)) + Pr(S=\{2\})(f_x(\{1, 2\}) - f_x(\{2\})) \\
&= 0.5(22 - 10.5) + 0.5(20-10) = 10.75
\end{align*}
$$
$$
\begin{align*}
\phi_2 &= Pr(S=\emptyset)(f_x(\{2\}) - f_x(\emptyset)) + Pr(S=\{1\})(f_x(\{1, 2\}) - f_x(\{1\})) \\
&= 0.5(10 - 10.5) + 0.5(20-22) = -1.25
\end{align*}
$$
また,詳しく説明しませんでしたが,
$$
\phi_0 = f_x(\emptyset) = 10.5
$$
です.
この$\phi_0$から$\phi_2$までを全て足し合わせると,本来の出力$f(\boldsymbol{x})$と一致します.
実際
$$\phi_0 + \phi_1 + \phi_2 = 10.5+10.75 - 1.25 = 20 = f(\boldsymbol{x})$$
です. これでめでたくSHAP値が計算できました.
2番目の特徴に関するSHAP値$\phi_2$がマイナスになっていますが,今回の例では$x_2$が出力$f(\boldsymbol{x})$を減少させる働きをしているようです.

ざっくりとした理解
- SHAP値を計算するためには$f_x(S)$が必要
- $f_x(S)$の計算のためには,don't careを扱うことが必要
Don't careは真理値表で出てきますよね.
そして決定木はIf-thenルールで表現されるモデルであり,真理値表と関わりが深いです.
決定木ならdon't careをうまく扱えるというのは,直感的な気がします.
Don't careを視覚的に表現すると,上の具体例の赤い線になります.
また,今回は2次元でしたが,高次元になると赤い線が超平面($\boldsymbol{x}$を含む部分空間)になります.
今回の説明では,計算コストには全く触れませんでしたが,論文内には決定木に対するSHAP値算出の効率的なアルゴリズムも示されています.決定木をtraverseしていく過程で計算した結果をメモリに保存しておいて無駄な再計算を省くイメージでしょうか.ここに関しては機械学習云々というよりもデータ構造とアルゴリズム的な話だと思うので,深追いはしません.
【補足】XGBoostのようなアンサンブル木のSHAPを求めるためには?
SHAP値の元になっているShapley値は次の加法性を満たしています6.
$$
\phi_i(v, w) = \phi_i(v) + \phi_i(w)
$$
同様にSHAP値も2つの学習済みモデル$f$, $g$に関して
$$
\phi_i(f+g; \boldsymbol{x}) = \phi_i(f; \boldsymbol{x}) + \phi_i(g; \boldsymbol{x})
$$
が成り立ちます.
XGBoostでは複数の決定木$h$を用いて$f(\boldsymbol{x})=\sum_{t=1}^T h_t(\boldsymbol{x})$と表現されるモデルですので,
$$
\phi_i(f; \boldsymbol{x}) = \phi_i(\sum_t h_t; \boldsymbol{x}) = \sum_{t=1}^T \phi_i(h_t; \boldsymbol{x})
$$
です.つまり$T$個の決定木に対するSHAP値を計算した後で,それらを足し合わせると$\phi_i(f; \boldsymbol{x})$が算出できます.
おわりに
SHAPについて,特にTreeExplainerの計算方法について,具体例を絡めて説明しました.
今回は説明を省きましたが,SHAP値は特徴重要度として最低限満たすべき性質を3つ定め,それをShapley値導出の際に使われる公理と結びつけることで,論理的な妥当性を明確に主張しています.
さらにJupyter上で動くインタラクティブなPython実装も公開されており,単に特徴重要度を計算すること以上の解釈性を提供しています.
論理的妥当性と実用性の両方を兼ね備えているのは凄いですね.
このまとめが皆様の理解の一助になれば幸いです!
-
実際には$Pr(S)=\frac{|S|!(M-|S|-1)!}{M!}$という式で表現されます.単に「期待値計算に必要」ということだけ分かれば良いので表現をシンプルにするために$Pr(S)$で留めました. ↩
-
通常の協力ゲームでは$v(\emptyset) = 0$と仮定することが多いですが,特徴重要度算出に関しては$f_x(\emptyset)=0$とは限りません.本質的ではありませんが,この部分は若干違います.通常は$\sum_{i=1}^M \phi_i = v(N)$ですが,SHAP値に関しては$\phi_0 = f_x(\emptyset)$として$\phi_0(f; \boldsymbol{x}) + \sum_{i=1}^M \phi_i(f; \boldsymbol{x}) = f(\boldsymbol{x})$となります. ↩
-
真理値表で出てくるやつです ↩
-
Shapley regression valuesという手法に対応します. ↩
-
$Pr(\boldsymbol{Z}_{\bar{S}}|\boldsymbol{Z}_S = \boldsymbol{x}_S) = Pr(\boldsymbol{Z}_S=\boldsymbol{x}_S, \boldsymbol{Z}_\bar{S}) / A$.ただし$A = \int Pr(\boldsymbol{Z}_S = \boldsymbol{x}_S, \boldsymbol{Z}_\bar{S}) d\boldsymbol{Z}_\bar{S}$ ↩
-
というよりも加法性を満たすようにShapley値が導出されています. ↩