先日Listの実装から学ぶScala&関数型プログラミング入門に参加してScalaのListのデータ構造について少し勉強してきました。JavaのListのデータ構造とともに復習しておきます。
JavaのList
JavaのListと言えばArrayListとLinkedListがあると思いますので、中身を見ていきたいと思います。下記は要素(データ)の追加と取得に関する部分だけを抜粋しています。
ArrayList
ArrayListは内部で要素情報を配列で保持します。
package java.util;
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
private static final int DEFAULT_CAPACITY = 10;
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
transient Object[] elementData;
private int size;
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
/* 中略 */
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
private void ensureCapacityInternal(int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
public E get(int index) {
rangeCheck(index);
return elementData(index);
}
E elementData(int index) {
return (E) elementData[index];
}
/* 中略 */
}
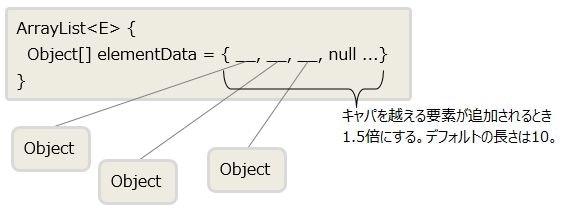
elementDataが要素情報の配列ですね。要素の追加はaddメソッドで行い、入力された要素をelementDataに格納していきます。面白いのが配列の拡張方法なのですが、elementDataに最初の要素を格納する際デフォルトで10の長さの配列が作られます。その後elementDataの長さを超える要素を格納しようとするとelementDataの1.5倍の長さの配列を作り、そちらにデータを移しています。配列にある程度遊びを作って、配列インスタンス生成のコスト削減をしているんですね。
int newCapacity = oldCapacity + (oldCapacity >> 1) // 1.5倍の長さを取得
要素の取得は、getメソッドで入力されたindexを用いて直接配列のindexを参照するようになっているので、シーケンシャルアクセスはもちろんランダムアクセスでも高いパフォーマンスを発揮します。絵心のカケラもない僕ですが、イメージ図を作ってみたので載せておきます。
LinkedList
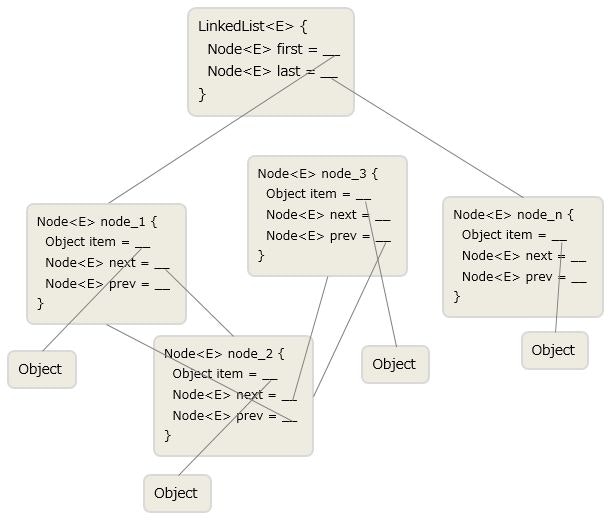
LinkedListは要素をNodeという内部クラスで管理します。LinkedList自身は先頭Nodeと末尾Nodeの情報しか持っておらず、Node自身が前後のNodeの情報を持つ構造となっています。addメソッドで要素を追加する度に新規Nodeを作り、その新規Node情報を末尾Nodeのnextに、末尾Node情報を新規Nodeのprevに格納します。
package java.util;
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
{
transient int size = 0;
transient Node<E> first;
transient Node<E> last;
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
public boolean add(E e) {
linkLast(e);
return true;
}
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
/* 中略 */
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
/* 中略 */
}
要素の取得は、getメソッドで入力されたindexまで先頭か末尾のどちらか近い方から追っていき取得します。ここがArrayListと違いランダムアクセスに弱い理由です。下のイメージ図で言うと、node_3の要素を取得しようと思ったときnode_1からたどっていかないといけないのです。
ArrayListとLinkedListの使い分け
これは僕の個人的な意見で、アルゴリズムに詳しい方からの助言を頂けると良いのですが、基本はArrayListで良いかと。ArrayListであれば要素へのアクセスも早いですし、LinkedListに比べメモリの使用量も少ないからです。ただListに大量のデータを持たせ、要素の追加削除を繰り返す(例えばキューのような役割)場合はLinkedListを使うと良いかと。ArrayListの場合、要素削除により配列に空きがでたときや要素間への追加を行うとき要素の移動処理が発生するからです。LinkedListの場合は前後のNodeの情報を書き換えるだけなので効率的なのです。
ScalaのList
ScalaのListでは要素情報をheadとtailで表現しています。名称だけ見ると、JavaのLinkedListと似ているような気がしますが、実は全く違う構造になっていてheadは先頭要素の情報、tailは先頭以外の要素情報をList型で表現しています。そもそもScalaのListはイミュータブル設計になっていて、JavaのようにListオブジェクト自身に変更を加えるのではなく、変更後のListを新しく作っていくようにできています。
package scala
package collection
package immutable
sealed abstract class List[+A] extends AbstractSeq[A]
with LinearSeq[A]
with Product
with GenericTraversableTemplate[A, List]
with LinearSeqOptimized[A, List[A]]
with Serializable {
override def companion: GenericCompanion[List] = List
import scala.collection.{Iterable, Traversable, Seq, IndexedSeq}
def isEmpty: Boolean
def head: A
def tail: List[A]
def ::[B >: A] (x: B): List[B] =
new scala.collection.immutable.::(x, this)
/* 中略 */
}
final case class ::[B](override val head: B, private[scala] var tl: List[B]) extends List[B] {
override def tail : List[B] = tl
override def isEmpty: Boolean = false
}
object List extends SeqFactory[List] {
/** $genericCanBuildFromInfo */
implicit def canBuildFrom[A]: CanBuildFrom[Coll, A, List[A]] =
ReusableCBF.asInstanceOf[GenericCanBuildFrom[A]]
def newBuilder[A]: Builder[A, List[A]] = new ListBuffer[A]
override def empty[A]: List[A] = Nil
override def apply[A](xs: A*): List[A] = xs.toList
private[collection] val partialNotApplied = new Function1[Any, Any] { def apply(x: Any): Any = this }
/* 中略 */
}
Scalaでは実際にプログラムを動かしてheadとtailを確認してみます。まずはListにいくつか要素を追加します。要素の追加は::メソッドで行います。
//(1) List作成
val list1 = List("ABC")
println(list1) // List(ABC)
//(2) 要素追加
val list2 = "DEF"::list1
println(list2) // List(DEF, ABC)
//(3) 要素追加
val list3 = list2.::("GHI")
println(list3) // List(GHI, DEF, ABC)
(2)と(3)は記法は違いますが同じメソッドを使用しています。index指定せず通常追加する場合、Javaと違って先頭に要素を追加していくイメージですね、Javaは末尾に要素を追加しますから。
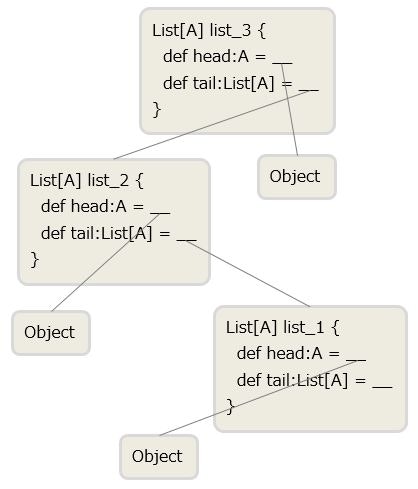
では(1)から(3)のオブジェクトのheadとtailをそれぞれ見てみます。
List(list1, list2, list3).zip(Range(1, 4)).foreach {
case (x, i) => println(s"list${i} => head:${x.head} tail:${x.tail}")
}
// list1 => head:ABC tail:List()
// list2 => head:DEF tail:List(ABC)
// list3 => head:GHI tail:List(DEF, ABC)
やはりheadからは先頭の要素、tailからは先頭以外の要素をListで返していますね。これもイメージ図を作ってみたので良ければ見てください。
ちなみにインスタンスからクラス名を取得して見てみると
val list4 = List("ABC")
println(list4.getClass) // class scala.collection.immutable.$colon$colon
val list5 = Array("ABC").toList
println(list5.getClass) // class scala.collection.immutable.$colon$colon
となってます。これscala.collection.immutable.::クラスのことのようで、このクラスのことをcons(おそらくconstructorのこと)と呼ぶらしい。List.::()メソッドを見ると、たしかに::インスタンスが作られ、引数をheadに設定しList自らはtailになっているのがわかります。
メソッド
メソッドについても少し書きます。と言っても書くのは個人的に便利だなと感じたものを列挙するだけです。
val range = Range(0, 10).toList
println(range) // List(0, 1, 2, 3, 4, 5, 6, 7, 8, 9)
val fill = List.fill(10)(5)
println(fill) // List(5, 5, 5, 5, 5, 5, 5, 5, 5, 5)
val rangefill = range.zip(fill).map { case (x, y) => x * y }
println(rangefill) // List(0, 5, 10, 15, 20, 25, 30, 35, 40, 45)
val flatmap = List(List(1, 2, 3), List(3, 4, 5), List(5, 6, 7)).flatten.distinct
println(flatmap) // List(1, 2, 3, 4, 5, 6, 7)
val reduce = List("ABC", "DEF", "GHI").reduceLeft(_+_)
println(reduce) // ABCDEFGHI
よくやる処理がだいたいメソッド定義されていてとても楽(他にも便利なメソッドたくさんあります)。Scalaには型推論やタプルもあるので、Javaよりも直感的かつ効率的にプログラミングができると思うし、なにより書いていて楽しいです。
最後に
標準ライブラリをほんの少し見ただけでも、とても勉強になりますね。標準ライブラリには天才的かつ芸術的なデザイン、技術が詰まっています。Javaではればオブジェクト指向プログラミング、Scalaであれば関数型プログラミングをこういったところから理解し習得していくのも良さそうです。