AtCoder Beginners Contest 328 (ABC328) をPythonで解きました。
見やすいコードを書く練習も兼ねてます。
A - Not Too Hard
問題
リスト $S$ の中にある $X$ 以下の要素をすべて足してください。
考察
for文をつかって、リスト $S$ にある数を1つずつ見ていきます。
もし見ている数が $X$ 以下だったら、答えの変数 $ans$ にその数を足します。
コード
N, X = map(int, input().split())
S = list(map(int, input().split()))
ans = 0
for s in S:
if s <= X:
ans += s
print(ans)
別解
sum関数+内包表記をつかった解法
先ほどは $4$ 行もつかって書いていた処理を、1行にまとめて書くこともできます。
詳しいことは書きませんが、「リスト内包表記」と調べるといろんな記事が出てきます。
N, X = map(int, input().split())
S = list(map(int, input().split()))
ans = sum(s for s in S if s <= X)
print(ans)
B - 11/11
問題
$2$ 月 $22$ 日みたいに、ゾロ目になっている日にちはいくつありますか?
考察
先に、次の小問題を考えます。
$A$ 月 $B$ 日の日付は、ゾロ目ですか?
要素の種類の数を知りたいときは、set() の要素数を求めます。
"""要素の種類の数を求める例"""
se = set()
se.add(1)
se.add(5)
se.add(20)
se.add(1)
se.add(20)
print(se) # {1, 5, 20} (← setは、同じ数を何度入れても変化しない)
print(len(se)) # 3 (← seの中の要素の数)
この性質を用いると、この小問題の答えは次のようにして解けます。
"""小問題の解答コード"""
A, B = map(int, input().split())
str_month = str(A)
str_day = str(B)
str_month_day = str_month + str_day
se = set()
for element in str_month_day:
se.add(element)
# ゾロ目 = つかわれている数の種類は1つだけ
if len(se) == 1:
print("Yes")
else:
print("No")
これで小問題を解くことはできました。
せっかく書いたので、このコードを関数にしておきます。
# A月B日がゾロ目ならTrueを、そうでないならFalseを返す関数
def is_ok(A, B):
str_month = str(A)
str_day = str(B)
str_month_day = str_month + str_day
se = set()
for element in str_month_day:
se.add(element)
return len(se) == 1
あとはfor文をつかって $1$ 月 $1$ 日から順番に、上の関数をつかってゾロ目かどうかをチェックしていけばokです。
コード
# A月B日がゾロ目ならTrueを、そうでないならFalseを返す関数
def is_ok(A, B):
str_month = str(A)
str_day = str(B)
str_month_day = str_month + str_day
se = set()
for element in str_month_day:
se.add(element)
return len(se) == 1
N = int(input())
D = list(map(int, input().split()))
ans = 0
for i in range(N):
for d in range(D[i]):
month = i + 1
day = d + 1
if is_ok(month, day):
ans += 1
print(ans)
C - Consecutive
問題
$S_l, S_{l+1}, \cdots S_r$ の中で、同じ英小文字が隣り合っているところはいくつありますか?
考察
区間 $[l,r]$ の何かを求めるときあるある、累積和をつかいます。
今回は隣り合っている文字が同じかどうかが知りたいので、まずはそれを見える化します。
# same[i]: S[i]=S[i+1]なら1, それ以外は0
same = [0] * (N - 1)
for i in range(N - 1):
if S[i] == S[i + 1]:
same[i] = 1
$S_l, S_{l+1}, \cdots S_r$ の中で、同じ英小文字が隣り合っている箇所の数は、$same[l]~same[r-1]$ の総和です。
ここで、リスト $same$ の累積和を取ります。
累積和は、itertools.accumulate() をつかうのがラクです。
from itertools import accumulate
acc = [0] + list(accumulate(same)) # 累積和リスト
これで、$same[l]~same[r-1]$ の総和は、$acc[r]-acc[l]$ と1度の計算で求められるようになりました。
これをクエリがとんでくるたびに計算すればokです。
コード
from itertools import accumulate
N, Q = map(int, input().split())
S = input()
same = [0] * (N - 1)
for i in range(N - 1):
if S[i] == S[i + 1]:
same[i] = 1
acc = [0] + list(accumulate(same))
for _ in range(Q):
l, r = map(lambda x: int(x) - 1, input().split())
ans = acc[r] - acc[l]
print(ans)
別解
Fenwick Tree をつかった解法
累積和より計算量は悪くなりますが、累積和のときよりも添え字がごちゃごちゃしにくくなると思うので紹介しておきます。
Fenwick Tree をつかうと、ある区間 $[l,r)$ の値の総和を $O(logN)$ で求められます。Python版ACLの中にあるので、下のコードではそれをつかっています。
この問題だと全体の計算量は $O(N+QlogN)$ で十分間に合います。
from itertools import accumulate
from atcoder.fenwicktree import FenwickTree
N, Q = map(int, input().split())
S = input()
ft = FenwickTree(N - 1)
for i in range(N - 1):
if S[i] == S[i + 1]:
ft.add(i, 1)
for _ in range(Q):
l, r = map(lambda x: int(x) - 1, input().split())
print(ft.sum(l, r))
D - Take ABC
問題
「一番左にある "ABC" を削除する」の操作を、"ABC" がなくなるまでやってね。
考察1 (シミュレーションする)
"ABC" を削除するたびに新たに左から見ていると最悪で $N^2$ 回くらいの処理が発生してTLEしてしまいます。
なので、どうにか工夫しないといけません。
いったん、文字列 $S$ が"BBAACAABABCCB"だったらどうなるかをシミュレーションしてみます。
一番左にある "ABC" を探さないといけないので、左から順に見ていきます。けっこう右の方に1つだけあります。これを削除します。
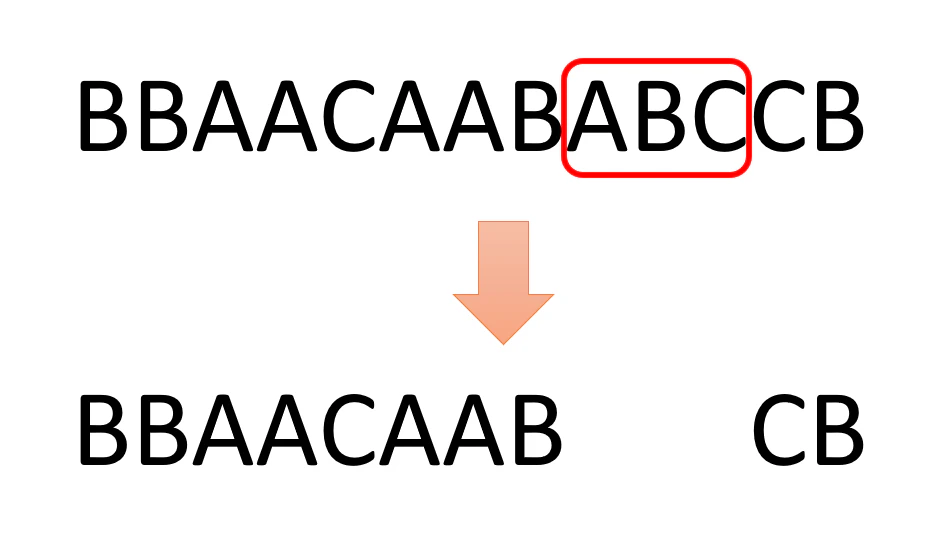
で、また最も左にある "ABC" を探します。
あなたなら、また一番左から順番に見るでしょうか?
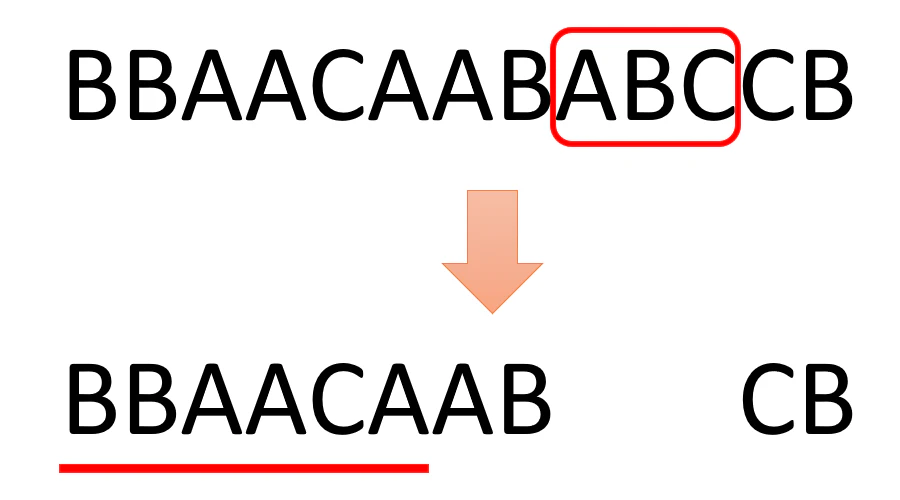
下線部分はすでに一度見ていて、どうやっても "ABC" はありません。
この部分を省略することで、プログラムの処理の回数を減らせそうです。
考察2 (スタックをつかった問題に置き換える)
「最も左にある "ABC" を削除する」を繰り返す操作を、次のように言い換えます。
左から順番に要素をスタックに入れていく。
スタックの先頭 $3$ つが "ABC" になっていれば、その要素 $3$ つを削除する。
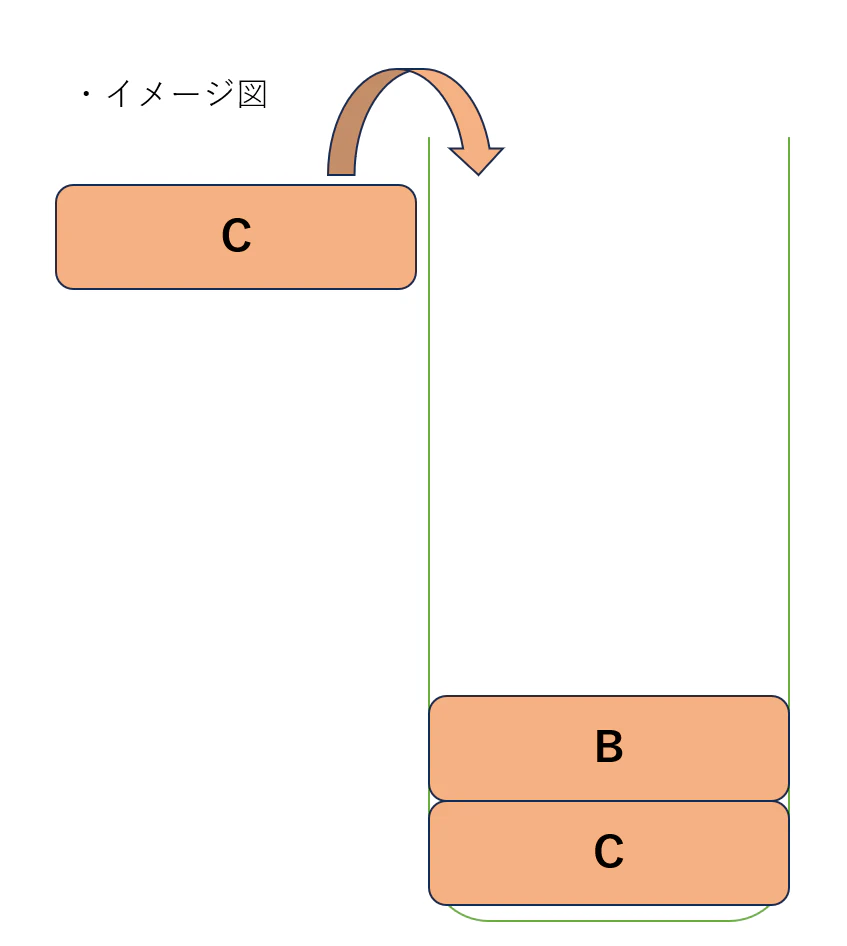
これなら処理は $O(N)$ で済みます。
これを実装すればACできます。
下のコードでは、あらかじめ適当な文字 "X" を 2つ入れておくことで、スタック内の要素の数が少ないときの場合分けを省略しています。
コード
S = input()
ans_stack = ["X", "X"]
for s in S:
ans_stack.append(s)
if ''.join(ans_stack[-3:]) == "ABC":
for _ in range(3):
ans_stack.pop()
print(*ans_stack[2:], sep="")
E - Modulo MST
問題
最小全域木(ただしコストは $K$ で割ったあまり) のコストはいくらでしょう?
考察
今までもそうでしたが、まずは愚直に解くことができるかチェックします。だいたいは無理ですが、無理でもどの部分がネックで計算量が多くなっているのかが分かりやすくなります。
今回は $N \leqq 8, M \leqq N(N-1)/2$ なので、頂点の数は最大で $8$ 個、辺の数は最大で $8\times 7/2=28$ 本あります。
$28$ 本の辺から $7$ 本の辺を選ぶ方法は全体で $_{28}C_7$ 通りです。
計算してみます。
val = 1
for i in range(22, 29):
val *= i
for i in range(1, 8):
val //= i
print(val) # 1184040
だいたい $10^6$ 通りくらいだと分かりました。
これなら、つかう辺を全パターン列挙することができそうです。
組み合わせのパターンの列挙は、itertools.combinations()が便利です(下のコードも参考にしてください)。
全域木になっているかどうかは、 $N$ 個の頂点がすべて連結かどうかが分かればokなので、UnionFindをつかいます。
この計算は、1パターンあたり $O(Nα(N))$ でかなり小さいので、実行制限時間に十分に間に合います。
コード
from itertools import combinations
from atcoder.dsu import DSU
N, M, K = map(int, input().split())
edge = []
for _ in range(M):
u, v, w = map(int, input().split())
edge.append((u - 1, v - 1, w))
ans = 1 << 70
for comb in combinations(range(M), N - 1):
uf = DSU(N)
total_cost = 0
for i in comb:
u, v, w = edge[i]
uf.merge(u, v)
total_cost += w
if len(uf.groups()) == 1:
ans = min(ans, total_cost % K)
print(ans)
F - Good Set Query
問題
$X_{A_i}-X_{B_i}=d_i$ が成立するように、左から順番に集合を増やしていってね。
考察
かなり天下り的ですが、グラフで各頂点に高さやポテンシャルがあると考えて、高低差アリで頂点どうしを結合していくときにつかえるのが、重み付き(ポテンシャル付き)Union Find です。
ライブラリを持っているだけですぐ解けるので、持っていなかった人は手元に持っておきましょう。
コード
class WeightedDSU:
"""重み付きUnionFind
wuf=WeightedDSU(N): 初期化
wuf.leader(x): xの根を返します。
wuf.merge(x,y,w): weight(x)-weight(y)でx,yを結合
wuf.same(x,y): xとyが同じグループに所属するかどうかを返す
wuf.diff(x,y): weight(x)-weight(y)を返す
"""
def __init__(self, n: int):
self.par = [i for i in range(n + 1)]
self.rank = [0] * (n + 1)
self.weight = [0] * (n + 1)
def leader(self, x: int) -> int:
if self.par[x] == x:
return x
else:
y = self.leader(self.par[x])
self.weight[x] += self.weight[self.par[x]]
self.par[x] = y
return y
def merge(self, x: int, y: int, w: int):
rx = self.leader(x)
ry = self.leader(y)
if self.rank[rx] < self.rank[ry]:
self.par[rx] = ry
self.weight[rx] = w - self.weight[x] + self.weight[y]
else:
self.par[ry] = rx
self.weight[ry] = -w - self.weight[y] + self.weight[x]
if self.rank[rx] == self.rank[ry]:
self.rank[rx] += 1
def same(self, x: int, y: int) -> bool:
return self.leader(x) == self.leader(y)
def diff(self, x: int, y: int) -> bool:
return self.weight[x] - self.weight[y]
N, Q = map(int, input().split())
uf = WeightedDSU(N)
ans_lst = []
for i in range(1, Q + 1):
a, b, d = map(int, input().split())
a, b = a - 1, b - 1
if uf.same(a, b):
if uf.diff(a, b) == d:
ans_lst.append(i)
else:
uf.merge(a, b, d)
ans_lst.append(i)
print(*ans_lst)