はじめに
今回はCloudTrailに保管しているS3オブジェクトを、Athenaで分析してみました。
個人的にはじめてAthenaを使ってみたので、備忘録として記録しておきたいです。
事前準備としては、
・CloudTrailを有効化し、ログをS3バケットに保管するよう設定します。
・Athena用のS3を作っておきます。S3作成後に、Athena設定画面の「クエリの結果と暗号化の設定」で当S3を指定します。
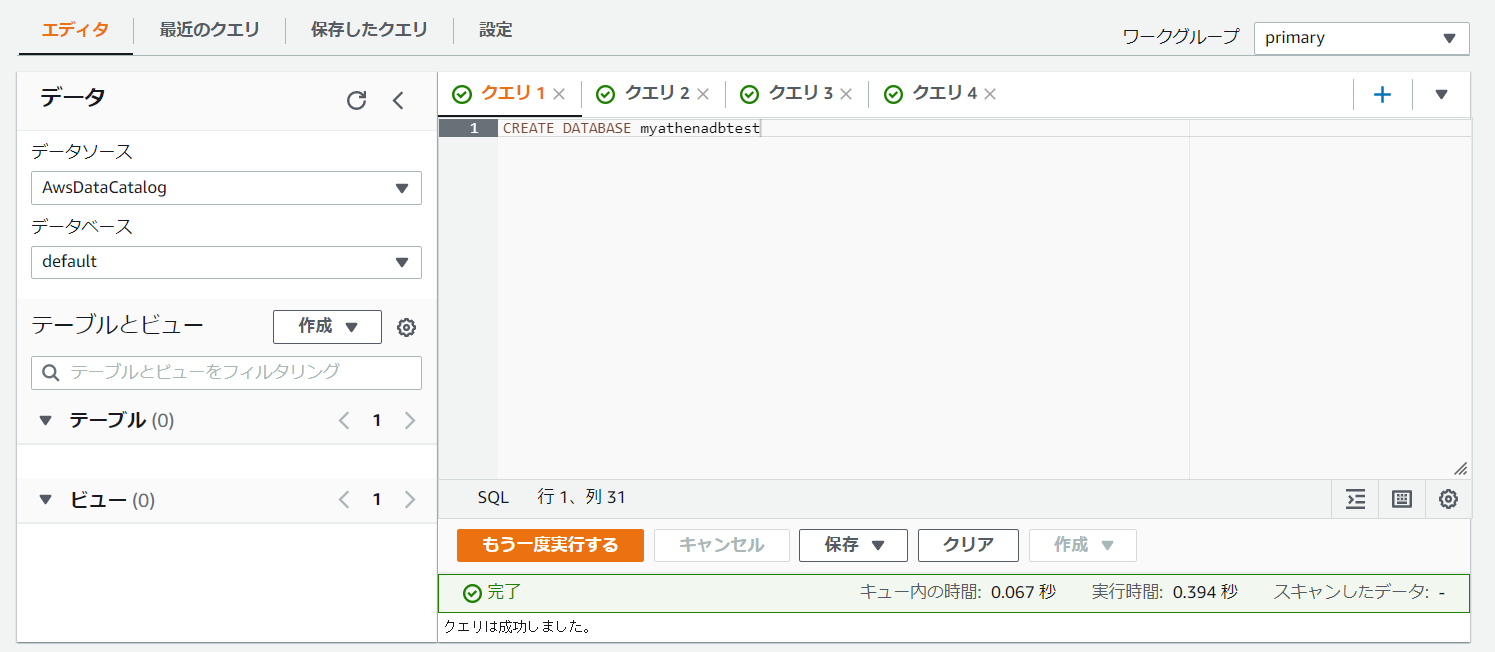
1.AthenaのDB作成
使ったコマンドは下記です。
CREATE DATABASE myathenadbtest
このような感じで、DBを作成しました。
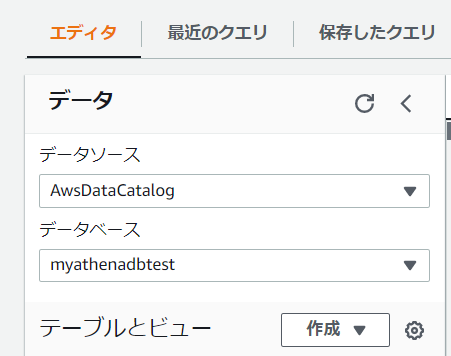
作成完了後に、データベースを上記で作ったmyathenadbtestを選択します。
2.テーブルの作成
AWS公式サイトが提供していただいたテーブルテンプレートに準じて、作成しておきます。
公式サイトのURLは最後の参考資料にご覧ください。
CREATE EXTERNAL TABLE cloudtrail_logs (
eventversion STRING,
useridentity STRUCT<
type:STRING,
principalid:STRING,
arn:STRING,
accountid:STRING,
invokedby:STRING,
accesskeyid:STRING,
userName:STRING,
sessioncontext:STRUCT<
attributes:STRUCT<
mfaauthenticated:STRING,
creationdate:STRING>,
sessionissuer:STRUCT<
type:STRING,
principalId:STRING,
arn:STRING,
accountId:STRING,
userName:STRING>>>,
eventtime STRING,
eventsource STRING,
eventname STRING,
awsregion STRING,
sourceipaddress STRING,
useragent STRING,
errorcode STRING,
errormessage STRING,
requestparameters STRING,
responseelements STRING,
additionaleventdata STRING,
requestid STRING,
eventid STRING,
resources ARRAY<STRUCT<
ARN:STRING,
accountId:STRING,
type:STRING>>,
eventtype STRING,
apiversion STRING,
readonly STRING,
recipientaccountid STRING,
serviceeventdetails STRING,
sharedeventid STRING
)
ROW FORMAT SERDE 'com.amazon.emr.hive.serde.CloudTrailSerde'
STORED AS INPUTFORMAT 'com.amazon.emr.cloudtrail.CloudTrailInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 's3://CloudTrail_bucket_name/AWSLogs/Account_ID/CloudTrail/';
ここで注意していただきたいのは、公式サイト上に提供しているSQL文に、パーティション化しているので、私はその行を削除しました。
PARTITIONED BY (region string, year string, month string, day string)
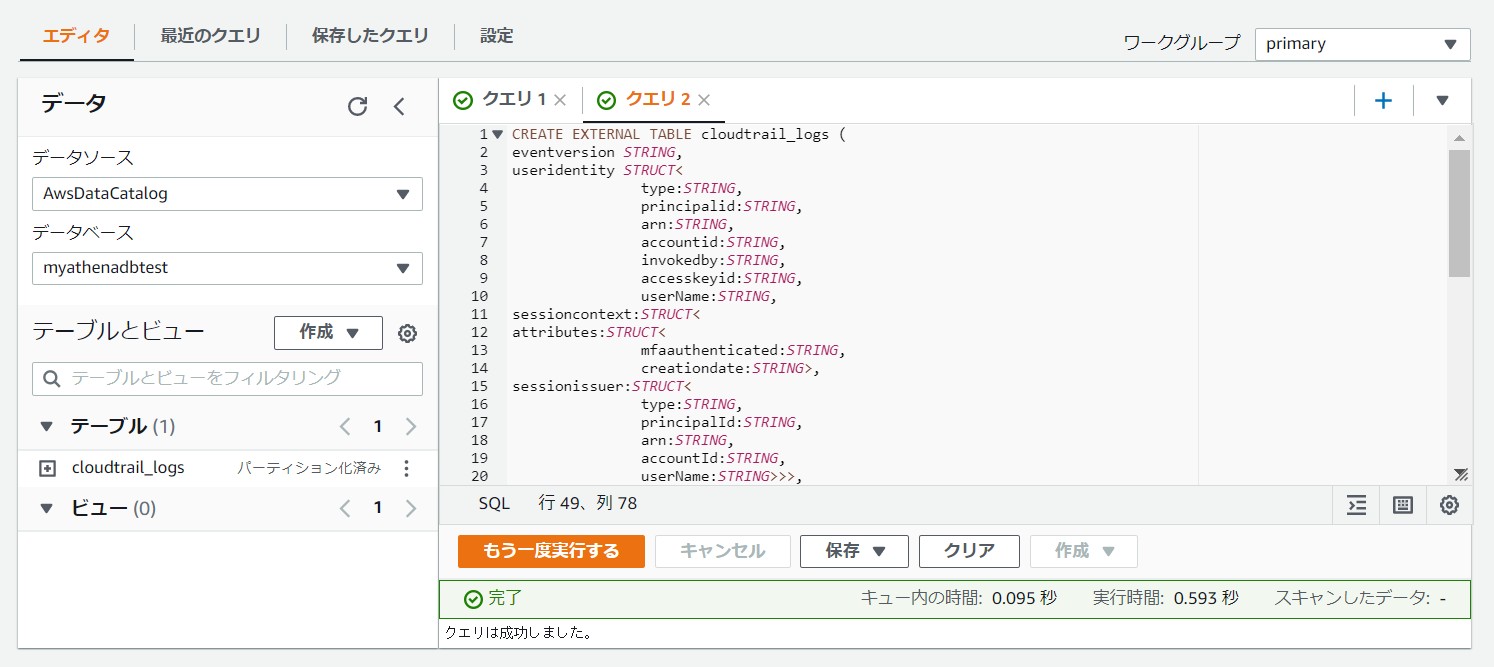
上記修正完了後に実行ボタンを押下してください。
実行完了後に、左側のテーブルに定義していたcloudtrail_logsが表示されます。
3.クエリをかけて分析
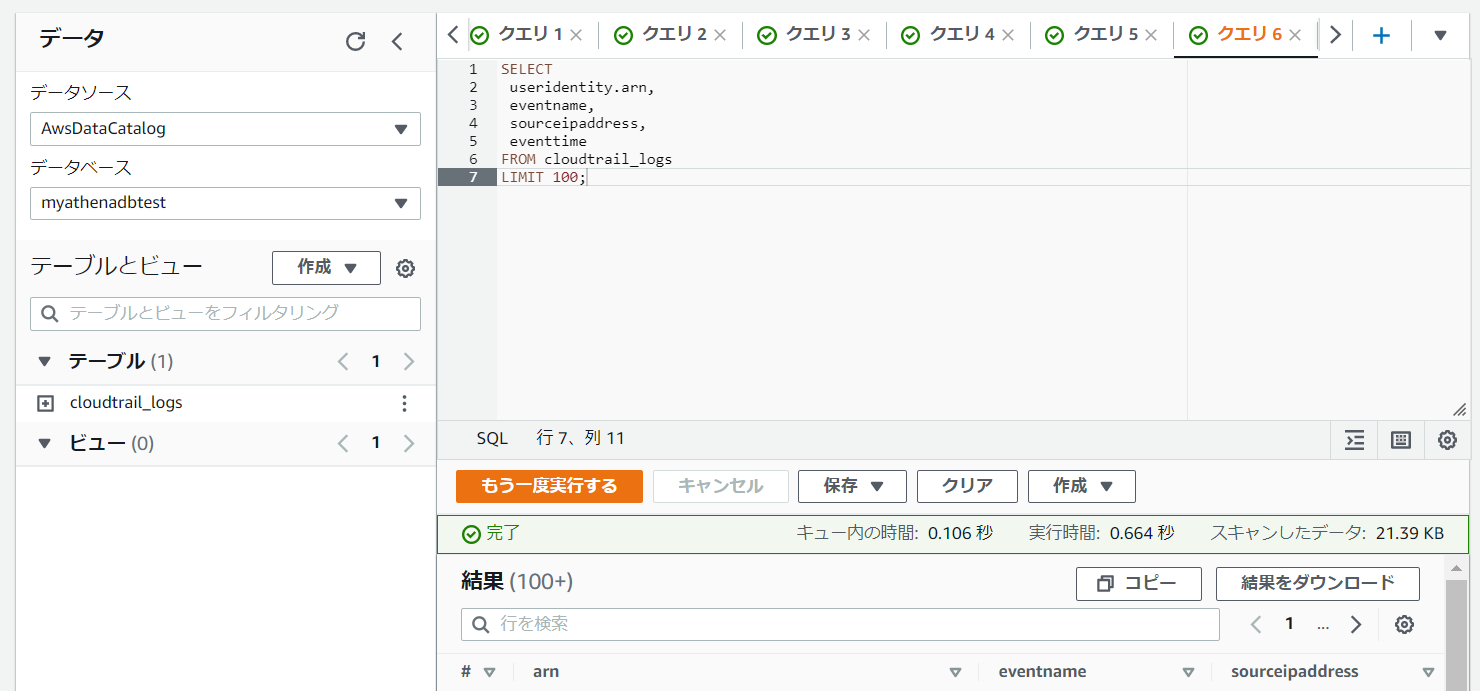
以下のクエリを流して、ログが吐き出されているかを確認します。
SELECT
useridentity.arn,
eventname,
sourceipaddress,
eventtime
FROM cloudtrail_logs
LIMIT 100;
以下のように、CloudTrailのログが検索できていることを確認できました。
参考資料: