モチベ(?)
去年、東京に友人と行きました。
秋葉原で友人が「ノラと皇女と野良猫ハート」っていうエロゲを買ってて、
後日やらせてもらったんだけど、
クソおもろいやんけ!
まだ全部やってクリアしてないにわかなので、そんな偉い口はたたけないのだが、
クソおもろいやんけ!
ストーリーが筋が通ってるというか、ギャグセンもある。
アニメもショート枠でやってた。見ろ。
キャラが可愛い!
(...まぁエロゲのキャラが可愛くないわけないんだが)
ノラと皇女と野良猫ハート オープニングムービー - youtube
購入はこちら
買ったな???
買った?よし、本題に入ろう。
このままだと最初から脱線してるキモすぎる記事になる。
モチベ
去年、ゼロから作るDeepLearningっていう本を買ったはいいけど、
ただ積んでただけだったのでちょうど長期の休みだったから改めて読むことに。
この本はMNISTを例にAIを作っていく超解りやすい本。
ただ、画像を読みこむ関数などのセットアップ系は既に
サンプルコードとして提供されていて、
どうもゼロから作ってる感じは自分の中ではしなかったのが残念だった。
だから本当にゼロから作ってみようと思って、
数字の判定なんてつまらないAIじゃなくて何か別のAIが作りたいと
思ってた時に上記のエロゲですよ。キャラの顔を判定するAIを作るぞ!
構成
入力層は50×50(画像サイズ)=2500ニューロン
隠れ層は1層で100ニューロン
出力層は10(キャラ9人+その他)ニューロン
全体では3層構成。
学習用データの作成
opencvの検出器にアニメ顔向けのを見つけたので、これを使う。
1[sec]ずつ動画から1コマ持ってきて、検出器にアニメ顔を見つけさせて、
それを手打ちで分類していく。
あ。学習データはアニメ全12話のうち7話までのデータを使うよ。
エロゲからは画像は取得しない。(CGを除いて数パターンの立ち絵しかないため。)
'''
顔の分類を行う
'''
import cv2
import os
classifier = cv2.CascadeClassifier('lbpcascade_animeface.xml')
# この数字が画像の名前になるので、
# 各話終了ごとに保存した枚数+1に書き換える必要あり。
# めんどくさい仕様ですまん。
asu=0
ida=0
michi=0
nobu=0
other=0
pato=0
ru=0
shachi=0
tanaka=0
yu=0
msec=0
output_dir = 'F:/faces50/'
cap=cv2.VideoCapture("./01.mp4")#ここを7話まで逐次変えて実行する
while(cap.isOpened()):
cap.set(0,msec*1000)
ret, frame = cap.read()
if ret:
gray_image = cv2.cvtColor(frame,cv2.COLOR_BGR2GRAY)
faces = classifier.detectMultiScale(gray_image)
for i, (x,y,w,h) in enumerate(faces):
print(str(msec)+"[sec]")
print("0:明日原 1:井田 2:黒木 3:ノブチナ 4:その他")
print("5:パトリシア 6:ルーシア 7:シャチ 8:田中 9:ユーラシア")
cv2.imshow("FRAME",frame)
face_image = frame[y:y+h, x:x+w]
face_image_resize=cv2.resize(face_image,(50,50))
cv2.imshow("DETECT",face_image_resize)
flg=cv2.waitKey(0)
if flg==48:#0
output_path = output_dir+'asu/'+'{0}.jpg'.format(michi)
asu+=1
elif flg==49:#1
output_path = output_dir+'ida/'+'{0}.jpg'.format(ida)
ida+=1
elif flg==50:#2
output_path = output_dir+'michi/'+'{0}.jpg'.format(michi)
michi+=1
elif flg==51:#3
output_path = output_dir+'nobu/'+'{0}.jpg'.format(nobu)
nobu+=1
elif flg==52:#4
output_path = output_dir+'other/'+'{0}.jpg'.format(other)
other+=1
elif flg==53:#5
output_path = output_dir+'pato/'+'{0}.jpg'.format(pato)
pato+=1
elif flg==54:#6
output_path = output_dir+'ru/'+'{0}.jpg'.format(ru)
ru+=1
elif flg==55:#7
output_path = output_dir+'shachi/'+'{0}.jpg'.format(shachi)
shachi+=1
elif flg==56:#8
output_path = output_dir+'tanaka/'+'{0}.jpg'.format(tanaka)
tanaka+=1
elif flg==57:#9
output_path = output_dir+'yu/'+'{0}.jpg'.format(yu)
yu+=1
elif flg==113:#q
exit(-1)
print("save "+output_path)
cv2.imwrite(output_path,face_image_resize)
msec+=1
else:
break
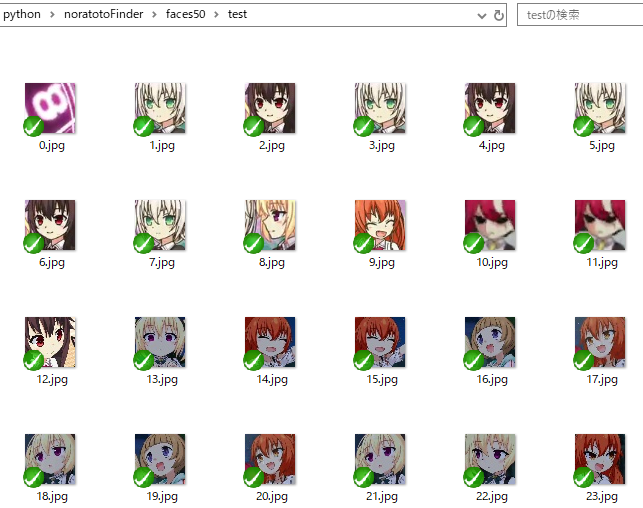
実行中はこんな感じ。(testというフォルダは次の手順で作成される。)
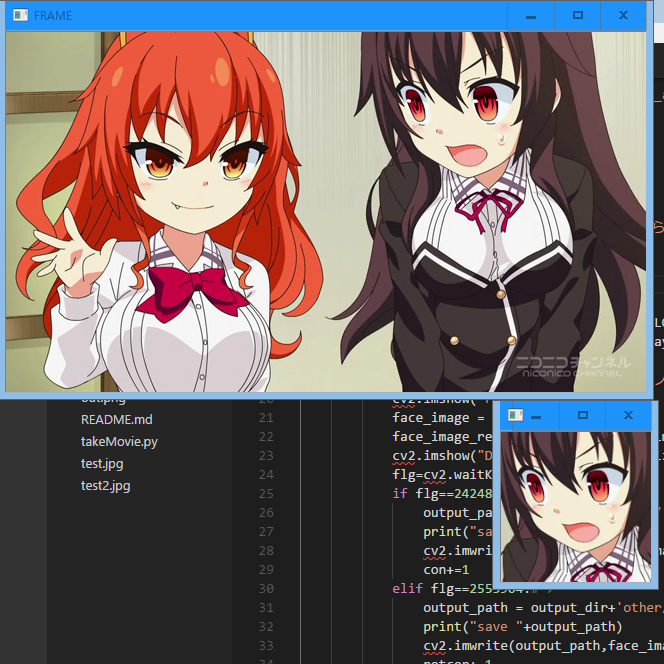
実行結果はこう。
(./faces50)
(./faces50/pato)
テスト用データの作成
学習したパラメータを使ってうまく判定できるかの確認用のデータを作る。
これは学習用のデータセットではない為、
各キャラごとにフォルダを分ける必要はない。
つまり全自動で顔を検出して、切り取って保存するプログラムである。
今回は8話の顔をテスト用のデータとする。
'''テスト用の顔を保存する'''
import cv2
import os
classifier = cv2.CascadeClassifier('lbpcascade_animeface.xml')
msec=0
cnt=0
output_dir = 'F:/faces50/test/'
cap=cv2.VideoCapture("08.mp4")
while(cap.isOpened()):
cap.set(0,msec*1000)
ret, frame = cap.read()
if ret:
gray_image = cv2.cvtColor(frame,cv2.COLOR_BGR2GRAY)
faces = classifier.detectMultiScale(gray_image)
for i, (x,y,w,h) in enumerate(faces):
print(str(msec)+"[sec]")
face_image = frame[y:y+h, x:x+w]
face_image_resize=cv2.resize(face_image,(150,150))
cv2.imwrite(output_dir+str(cnt)+".jpg",face_image_resize)
cnt+=1
msec+=1
else:
break
実行結果はこう。アニメ顔検出器の精度も100%正確なわけではないので若干変なのも交じってるけど、できればそれも判定して欲しい。
(./faces50/test)
TwoLayerNetクラス
今回の要となるクラス。異論は認める。
このソースコードの後、各メソッドをざっくり紹介する。
import numpy as np
from PIL import Image
import os
import sys
class TowLayerNet:
def __init__(self,input_size,hidden_size,output_size,weight_init_std=0.01):
print("初期化中")
self.params={}
self.params['W1']=weight_init_std*np.random.randn(input_size,hidden_size)
self.params['b1']=np.zeros(hidden_size)
self.params['W2']=weight_init_std*np.random.randn(hidden_size,output_size)
self.params['b2']=np.zeros(output_size)
def sigmoid(self,x):
'''シグモイド関数'''
return 1/(1+np.exp(-x))
def sigmoid_grad(self,x):
'''シグモイド勾配関数'''
return (1.0 - self.sigmoid(x)) * self.sigmoid(x)
def softmax(self,x):
'''ソフトマックス関数'''
c=np.max(x)
exp_x=np.exp(x-c)
sum_exp_x=np.sum(exp_x)
y=exp_x/sum_exp_x
return y
def crossEntropyError(self,y,t):
'''
交差エントロピー誤差
y:予想ラベル(ソフトマックス関数の出力)
t:正解ラベル
return:0に近いほど正確
'''
delta=1e-7
if y.ndim==1:
t=t.reshape(1,t.size)
y=y.reshape(1,y.size)
batch_size=y.shape[0]
return -np.sum(t*np.log(y+delta))/batch_size
def gradient(self, x, t):
'''偏微分'''
W1, W2 = self.params['W1'], self.params['W2']
b1, b2 = self.params['b1'], self.params['b2']
grads = {}
batch_num = x.shape[0]
# forward
a1 = np.dot(x, W1) + b1
z1 = self.sigmoid(a1)
a2 = np.dot(z1, W2) + b2
y = self.softmax(a2)
# backward
dy = (y - t) / batch_num
grads['W2'] = np.dot(z1.T, dy)
grads['b2'] = np.sum(dy, axis=0)
da1 = np.dot(dy, W2.T)
dz1 = self.sigmoid_grad(a1) * da1
grads['W1'] = np.dot(x.T, dz1)
grads['b1'] = np.sum(dz1, axis=0)
return grads
def predict(self,x):
'''
推論を行う
'''
W1=self.params['W1']
W2=self.params['W2']
b1=self.params['b1']
b2=self.params['b2']
a1=np.dot(x,W1)+b1
z1=self.sigmoid(a1)
a2=np.dot(z1,W2)+b2
y=self.softmax(a2)
return y
def loss(self,x,t):
y=self.predict(x)
return self.crossEntropyError(y,t)
def load_test(self,path,data_max):
'''
テストデータの読み込み
path:画像までのパス
data_max:読みこむ画像数
'''
x_test=[]
for i in range(data_max):
img_pixels = []
img = Image.open(path+str(i)+'.jpg')
gray_img = img.convert('L')
width, height = gray_img.size
for y in range(height):
for x in range(width):
img_pixels.append(gray_img.getpixel((x,y))/255.0)
img_pixels = np.array(img_pixels)
x_test.append(img_pixels)
return x_test
def load_train(self,path,data_max,teach):
'''
教師データの読み込み
path:画像までのパス
data_max:読みこむ画像数
teach:正解ラベル(np.array)
'''
x_train=[]
t_train=[]
for i in range(data_max):
img_pixels = []
img = Image.open(path+str(i)+'.jpg')
gray_img = img.convert('L')
width, height = gray_img.size
for y in range(height):
for x in range(width):
img_pixels.append(gray_img.getpixel((x,y))/255.0)
img_pixels = np.array(img_pixels)
x_train.append(img_pixels)
t_train.append(teach)
return x_train,t_train
def saveGradient(self,par):
'''
勾配をテキストに保存する
'''
path_w='gradient'+par+'.txt'
f=open(path_w,mode='w')
it = np.nditer(self.params[par], flags=['multi_index'], op_flags=['readwrite'])
while not it.finished:
idx=it.multi_index
f.write(str(self.params[par][idx]))
f.write("\n")
it.iternext()
f.close()
def saveLoss(self,loss):
path_w='loss.txt'
f=open(path_w,mode='w')
for i in loss:
f.write(str(i)+"\n")
f.close()
def loadGradient(self,par):
'''
勾配を読みこむ
'''
path_r='gradient'+par+'.txt'
with open(path_r) as f:
l = f.readlines()
it = np.nditer(self.params[par], flags=['multi_index'], op_flags=['readwrite'])
cnt=0
while not it.finished:
idx=it.multi_index
self.params[par][idx]=l[cnt]
it.iternext()
cnt+=1
def getGradient(self):
'''各パラメータを保存する'''
self.saveGradient('W1')
self.saveGradient('b1')
self.saveGradient('W2')
self.saveGradient('b2')
def setGradient(self):
'''各パラメータを設定する'''
self.loadGradient('W1')
self.loadGradient('b1')
self.loadGradient('W2')
self.loadGradient('b2')
def judge(self,x):
index=np.argmax(x)
if index==0:
print("明日原")
elif index==1:
print("井田")
elif index==2:
print("黒木")
elif index==3:
print("ノブチナ")
elif index==4:
print("その他")
elif index==5:
print("パトリシア")
elif index==6:
print("ルーシア")
elif index==7:
print("シャチ")
elif index==8:
print("田中")
elif index==9:
print("ユーラシア")
コンストラクタ
def __init__(self,input_size,hidden_size,output_size,weight_init_std=0.01):
input_sizeは今回の場合、50*50=2500を指定する。
hidden_sizeは100を指定する。
output_sizeは10種類に分類して欲しいので10を指定する。
パラメータW1は偏差0.01の2500行100列のガウス分布で初期化する。
パラメータW2は偏差0.01の100行10列のガウス分布で初期化する。
パラメータb1は全ての要素が0の1行100列のガウス分布で初期化する。
パラメータb2は全ての要素が0の1行10列のガウス分布で初期化する。
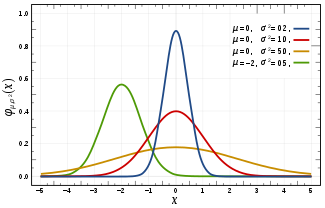
要は0~1の分布。学校の試験の結果などもすべてこのグラフに近似するすごいグラフ。(小並感)
シグモイド関数
def sigmoid(self,x):
特に各種グラフに現れるシグモイド曲線 (英: sigmoid curve) を指す。
このようなグラフは個体群増加や、ある閾値以上で起きる反応
(例えば急性毒性試験での死亡率)などに見られる。
シグモイド関数-wikipedia
ステップ関数のような離散的な、ある閾値を超えたときに突然発火するより、
連続的である方が自然だよねって話。
ソフトマックス関数
def softmax(self,x):
各要素の大小関係を維持したまま全ての要素を足すと1になるようにする。
つまり、この関数の戻り値は各出力の確率をそのまま表す。
勾配関数
def gradient(self, x, t):
各パラメータ(W1,W2,b1,b2)を用いて、
正解ラベルtとの勾配を求める。求め方は誤差逆伝搬法。
数値微分法もあり、こっちの方が理解しやすいけど、
恐ろしく低速なのでお勧めしない。
損失関数
def loss(self,x,t):
中身は交差エントロピー誤差を求めるもので、
このAIの目的はこの誤差を0に近づけることともいえる。
学習用データの読み込み
def load_train(self,path,data_max,teach):
pathにはフォルダへのパス。
data_maxには何枚読みこむかを指定する。
teachにはその画像の正解ラベル。
いざ学習
import TwoLayerNet
import numpy as np
from PIL import Image
# ハイパーパラメータ
iters_num=50000
lerning_rate=0.01
batch_size=1
# 各キャラの枚数
batch_size_asu=59
batch_size_ida=8
batch_size_michi=86
batch_size_nobu=86
batch_size_other=23
batch_size_pato=109
batch_size_ru=44
batch_size_shachi=57
batch_size_tanaka=51
batch_size_yu=36
net=TwoLayerNet.TowLayerNet(2500,100,10)
x=[]
t=[]
loss=[]
x_train,t_train=net.load_train("./faces50/asu/",batch_size_asu,np.array([1,0,0,0,0,0,0,0,0,0]))
x=x_train
t=t_train
x_train,t_train=net.load_train("./faces50/ida/",batch_size_ida,np.array([0,1,0,0,0,0,0,0,0,0]))
x.extend(x_train)
t.extend(t_train)
x_train,t_train=net.load_train("./faces50/michi/",batch_size_michi,np.array([0,0,1,0,0,0,0,0,0,0]))
x.extend(x_train)
t.extend(t_train)
x_train,t_train=net.load_train("./faces50/nobu/",batch_size_nobu,np.array([0,0,0,1,0,0,0,0,0,0]))
x.extend(x_train)
t.extend(t_train)
x_train,t_train=net.load_train("./faces50/other/",batch_size_other,np.array([0,0,0,0,1,0,0,0,0,0]))
x.extend(x_train)
t.extend(t_train)
x_train,t_train=net.load_train("./faces50/pato/",batch_size_pato,np.array([0,0,0,0,0,1,0,0,0,0]))
x.extend(x_train)
t.extend(t_train)
x_train,t_train=net.load_train("./faces50/ru/",batch_size_ru,np.array([0,0,0,0,0,0,1,0,0,0]))
x.extend(x_train)
t.extend(t_train)
x_train,t_train=net.load_train("./faces50/shachi/",batch_size_shachi,np.array([0,0,0,0,0,0,0,1,0,0]))
x.extend(x_train)
t.extend(t_train)
x_train,t_train=net.load_train("./faces50/tanaka/",batch_size_tanaka,np.array([0,0,0,0,0,0,0,0,1,0]))
x.extend(x_train)
t.extend(t_train)
x_train,t_train=net.load_train("./faces50/yu/",batch_size_yu,np.array([0,0,0,0,0,0,0,0,0,1]))
x.extend(x_train)
t.extend(t_train)
x=np.array(x)
t=np.array(t)
for i in range(iters_num):
print(str(i+1)+"/"+str(iters_num))
batch_mask=np.random.choice(x.shape[0],batch_size)
x_batch=x[batch_mask]
t_batch=t[batch_mask]
grad=net.gradient(x_batch,t_batch)
net.params['W1']-=lerning_rate*grad['W1']
net.params['b1']-=lerning_rate*grad['b1']
net.params['W2']-=lerning_rate*grad['W2']
net.params['b2']-=lerning_rate*grad['b2']
l=net.loss(x_batch,t_batch)
loss.append(l)
print("Err:"+str(l))
# 保存
net.saveLoss(loss)
net.getGradient()
一番よくいったハイパーパラメータは以下の通り。
イテレータは5万。
学習率は0.01。
バッチサイズは1。
具体的にパラメータの更新はコード後半のこの部分。
net.params['W1']-=lerning_rate*grad['W1']
net.params['b1']-=lerning_rate*grad['b1']
net.params['W2']-=lerning_rate*grad['W2']
net.params['b2']-=lerning_rate*grad['b2']
学習率(lerning_rate)をhとおく。
例えばgrad['W1'][0]が0.05の時、
パラメータを更新するとgrad['W1'][0]は0.05hだけ値が変化することになる。
確立勾配降下法(SGD)にのっとってパラメータを更新するので、上記コードのような式になる。
損失関数の遷移は以下の通り。
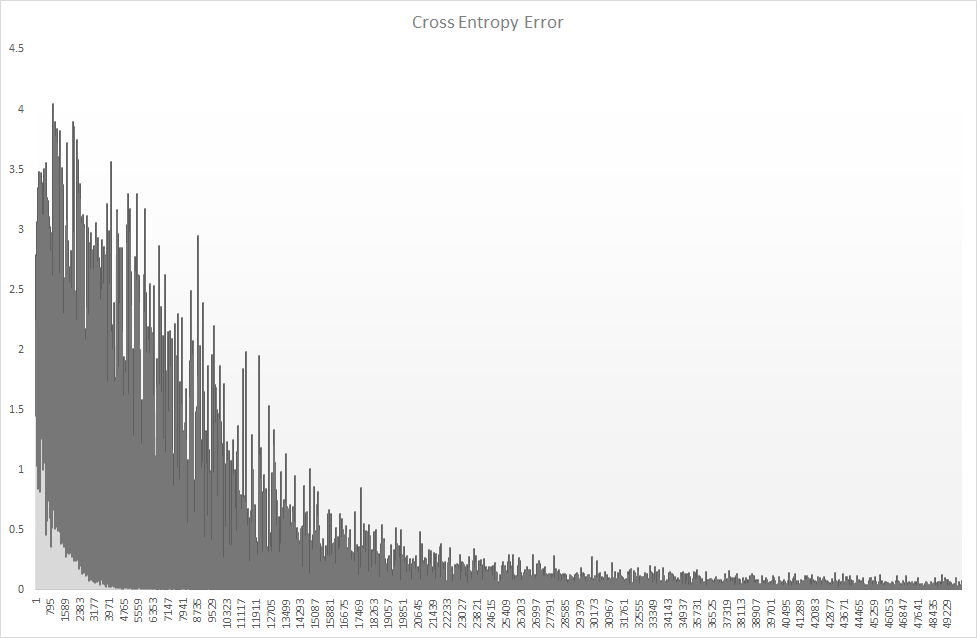
序盤は誤差がめちゃくちゃにブレたので、失敗したかと思ったが、
回数を重ねるそれらしくなったのでよかった○
結果
8話の顔ディレクトリをさきほど学習したパラメータを使って
判定してみる。
import TwoLayerNet
import numpy as np
net=TwoLayerNet.TowLayerNet(2500,100,10)
net.setGradient()
x_test=net.load_test("./faces50/test/",164)
x=np.array(x_test)
x_res=net.predict(x)
for i in range(164):
print(str(i)+".jpg ",end="")
net.judge(x_res[i])
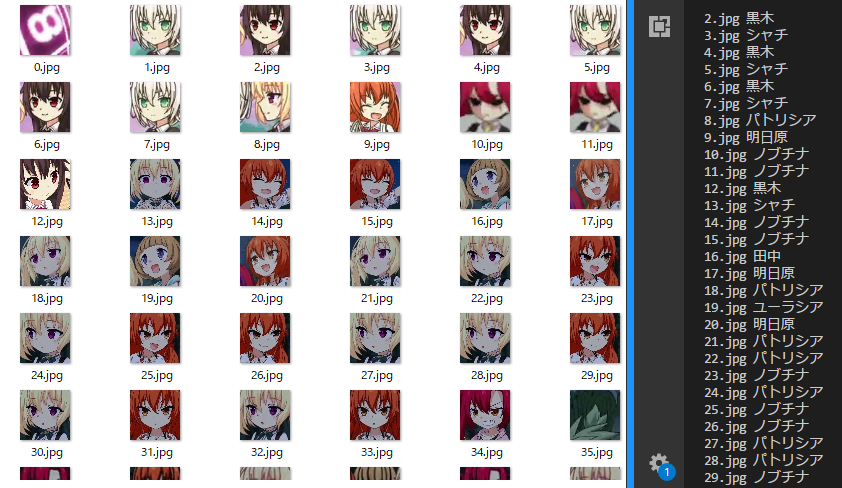
ノブチナと明日原を間違えるのが目立つが、ほぼ当たっていて感動の極み。
所感
バッチサイズが1じゃないとうまくいかないのは恐らく、
どっか間違ってるんだろうなぁとは思ってる。
あとお前らノラトトをやれ。