これはFJCT Advent Calendar2日目の記事です。
1日目は@fuku2014のLet's EncryptのDNS-01方式をニフクラDNSで認証して無料のSSL証明書を取得し自動更新するです。
3日目は@riowさんの勘違いして定時前に帰った話とその再発防止策です。
こちらはOJTでelkスタック(elasticsearch-logstash-kibana)を使ってログ基盤を開発していた時に、logstashに関する記事があまりなかったため、自分が面白いと感じた部分について描いてみました。下記は主に次の2つの内容を、logstashドキュメントを参考にしながら説明します。
- logstashのPersistent queuesとbackpressureの紹介
- メッセージキューのようなツールを作成する時に参考にできるアーキテクチャの紹介
logstashのご紹介
logstashのご紹介は以下のホームページを参照していただくことにします
オープンソースのサーバーサイドデータ処理パイプラインで、膨大な数のソースから同時にデータを取り込み、
変換して、指定された任意の「格納庫(スタッシュ)」(私たちの場合は当然、Elasticsearchです)に送信します。
https://www.elastic.co/jp/products/logstash
Persistent queues (永続キュー)
logstashの弱点としてバッファがないと言われていました。そのため、大量のログを取り扱う場合はよくバッファ役としてMQツール(kafkaなど)と組み合わせることが多いようです。
そこで、こちらを改善するために5.xからpersistent queues (永続キュー)機能ができました。
話が戻りますが、logstashのデフォルト設定では確かにログのバッファはin-memoryとなっており、変更することができません。この場合では、データの流れが以下の通りであり、プロセスの消滅によるログ損失の可能性が高いと考えられます。
input -> pipeline -> workers
persistent queues (永続キュー)機能は変更可能なin-diskバッファです。また、プロセスが消滅して再開される時は処理中だったところからスタートされるので、ログの損失を防止することができます。この時のデータの流れは以下の通りです。
input → queue → filter + output
設定方法
こちらの記事に設定方法とin-memoryとin-diskの比較があるので参照していただければと思います
https://dev.classmethod.jp/server-side/elasticsearch/logstash-queue-persisted/
仕組み
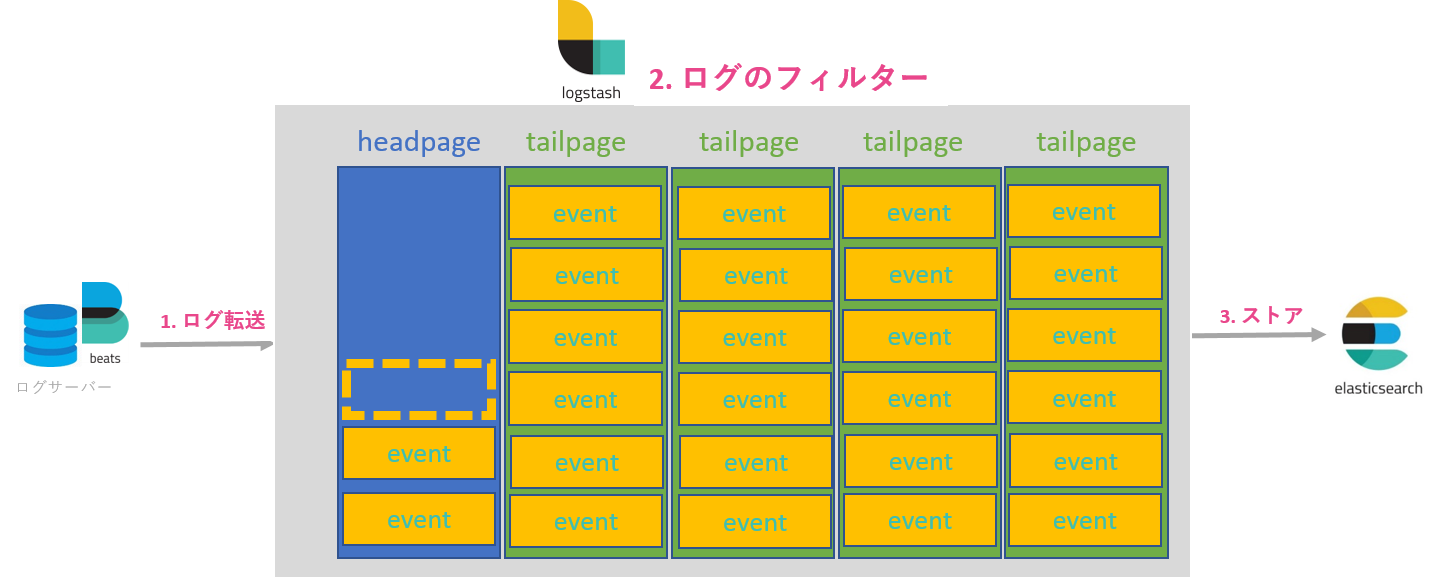
データ管理構成
Persistent queuesはデータをpage単位で管理します。1 pageはqueue.page_capacityで設定したbytesだけの容量を持った、1 fileに相当します。また、pageはhead pageとtail page2種類あります。Head pageはデータを書き込むところで、そして拡張することしかできません。Head pageは自分のサイズが最大となる次第tail pageになり、新しいhead pageが作成されます。Tail pageのデータはこの後、ログのfilterとoutputフェーズに渡され、全ての処理が正常に終了したらoutputモジュールからACKが返ってきてtail pageが削除されます。
Pageは複数のeventという論理的な単位から構成されます。queue.max_eventsで1 pageのeventの数を指定することができます。logstashはevent単位で処理します。例えば、pageの削除(ゴミ回収)は属する全てのeventがACKをもらえた状態でしか行われません。また、logstashプロセスの異常停止し、再開した場合ではACKをもらっていないeventから損失なく処理が行われます。
Back pressure
logstashは、キューがqueue.max_bytesで設定した最大サイズに達成した時に、データを送っている先(beatsなど)に、データの送信を一旦停止するように要求することが、back pressureと言います。こうすることで、logstashプロセス自体の負荷を一定以下制限することができるとともに、elasticsearchに無理なoutputをすることが避けられます。因みに「キューがいっぱい」というのは、ACKをもらっていないeventで埋まっている状態です。Back pressureが頻繁に発生したら、logstashがシステムのデータの量を処理し切れないことなので、キューサイズの増設やサーバーのスペックをあげることが必要でしょう。
書き込みの管理
inputが一旦停止して再開する時はどこから始めるかをどうやって分かるんでしょう? logstashは自分自身のデータ書き込み状態を監視するためにcheckpointファイルを生成し、書き込み先であるhead pageの状態を管理します。具体的には、head pageのfsyncの状態をmemoryからdiskに保存するようになっています。一回の書き込みは1 eventとなっています。queue.checkpoint.writesでmemory上の何回の書き込みならdiskに書き写すのかを指定できます。1 と指定すればデータの健全性を最大に保てるが、パフォーマンスに影響があるかもしれません。逆にこちらをあげることでlogstashの処理速度を向上させることができます。もっと詳細に関してはcheckpointのソースコードはこちらだと思われます。
最後に
logstashのPersistent queues機能は、メッセージキューのようなツールを作成する時に参考にできるアーキテクチャだと思いました。もちろん、in-diskにするのがパフォーマンスに悪い影響を与える場合もあると思いますが、こちらの記事で検証した結果では、
10万件でin-diskがin-memoryより17秒差なのでそこまで大きな差ではないかな、システムによっては許容できないかもしれませんね。
明日は@riowさんの勘違いして定時前に帰った話とその再発防止策です。
きっととても面白いものが期待できますよ!