とりあえずGithubを
背景
低気圧もしくは気圧が急降下する際には、以下の症状があらわれる人が多そうです。
- 身体的:だるさや眠気、頭痛
- 精神的:落ち込みやネガティブ
私のタイムラインを見ていると、気圧が下がってきたときアラートを出してくれる方もいます。
記事もけっこうあります。
科学的根拠があるのかはしりません
とりあえず私の体調と気圧が関係するのか調べたくなりました。
目的
- 気圧の変化のグラフや通知を見ることで自分の体調と主観的に把握すること
- 気分の変化の記録と比較することで相関があるのかを数学的?に確かめること
解決手法・今回やること
- 直近の気圧を取得 <= 今回の記事
- 気圧をSlack通知 <= 次回の記事
- Google Spread Sheetに保存 <= さらに次
( tree コマンドってwinでも使えるのですね)
root/
│ .env
│ .env.sample
│ .gitignore
│ app.py
│ ---.json
│ README.md
│ requirements.txt
│
├─api_packages/
│ │ googleItem.py
│ │ slackItem.py
│ │ __init__.py
│
├─data_packages/
│ │ fetchHtml.py
│ │ generateGraph.py
│ │ __init__.py
│
├─imgs/
python=3.8
pip install beautifulsoup4
pip install requests
pip install numpy
pip install matplotlib
pip install python-dotenv
pip install gspread
pip install oauth2client
気圧を取得
APIで取得することも考えましたが、気象庁が公開している東京のデータを使わせていただくことにしました。
https://www.jma.go.jp/jp/amedas_h/today-44132.html
ちょうど BeautifulSoup の勉強もしたかったので、それも兼ねています。
import requests
from bs4 import BeautifulSoup
import datetime
import re
class HtmlFetcher:
url = None
def __init__(self, url):
self.url = url # 可変にしようとしたが、止めた…
def fetch_pressure_from_jma(self, search_time = datetime.datetime.now()): # デフォルト引数を取っていますがこれやるとだめ
url = "調べたいURL"
try:
res = requests.get(url)
soup = BeautifulSoup(res.text, 'html.parser')
trs = soup.select("div#div_table > table > tr")
list_time_pressure = []
for tr in trs:
tds = tr.select("td")
if tds[0].get_text().isdigit() and tds[8].get_text().replace('\xa0', ''):
list_time_pressure.append(
{
'time': int(tds[0].get_text()),
'pressure': tds[8].get_text()
}
)
if len(list_time_pressure) == 0:
return None
else:
date_place_title = soup.select("table#tbl_title td.td_title")[0].get_text()
year = re.search(r'\d{4}年', date_place_title).group()[0:4]
month = re.search(r'\d{2}月', date_place_title).group()[0:2]
day = re.search(r'\d{2}日', date_place_title).group()[0:2]
place = re.search(r'\s+\D+\Z', date_place_title).group()[1:]
result = {}
# if search_time:
# 指定した時刻に最も近いデータを取得したかった…
# sorted_time_pressures = sorted(list_time_pressure, key=lambda x: abs(int(search_time.hour - x['time'])))
# もっとも時間が最近のものを取得
sorted_time_pressures = sorted(list_time_pressure, key=lambda x:-x['time'])
result = {
'data': sorted_time_pressures,
'info': {'day': day, 'month': month, 'year': year, 'place': place}
}
return result
except Exception as e:
print(e)
return False
なんとなく雰囲気で読めるかと思いますが
trs = soup.select("div#div_table > table > tr")
jQuery や SCSS を慣れ親しんだ人ならわりと直感的な記法だと思います。
上記ページは単純な構成でしたが、逆に Class があまりなかったりして深い取得の仕方をしなければなりませんでした。
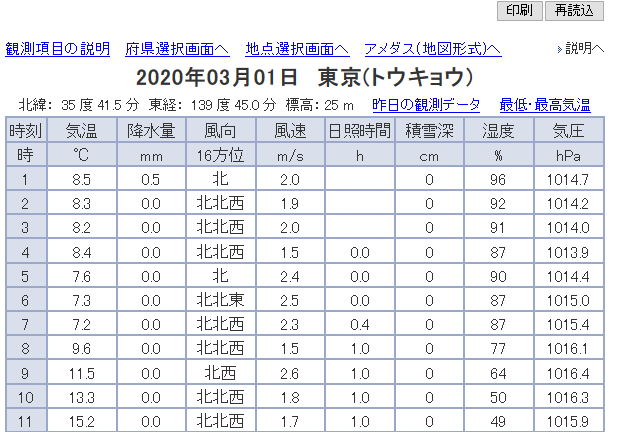
該当ページより2020年03月01日で引用
if tds[0].get_text().isdigit() and tds[8].get_text().replace('\xa0', ''):
ここでその行が気圧を表示しているかを判定しています。
| 時刻 | 気温 | 降水量 | ... |
|---|---|---|---|
| 時 | ℃ | mm | ... |
| 1 | 8.5 | 0.5 | ... |
「時刻」の行と「時」の行は気圧データはありません。
なので整数に変換できるデータなら気圧が9番目は列には気圧が入っていそうです。
また気圧が未記入だったら取得しても仕方ないのであとの条件を入れています。
謎の文字が入っているのでそれは置換しました。
ここちゃんと動いているか記事書いていたら不安になってきました。
list_time_pressure = []
例えば午前1時に取得したら、このリストは長さ1という感じになります。
date_place_title = soup.select("table#tbl_title td.td_title")[0].get_text()
最初の地名と日付が入っているとのころの情報を取得しています。
td_title ってClass名の付け方らしいです。
これを正規表現を使って分割していきます。
# 最初の整数4桁は年
# 大化の改新があった645年や未来20000年のデータを取得できないんですが、まあ…
year = re.search(r'\d{4}年', date_place_title).group()[0:4]
month = re.search(r'\d{2}月', date_place_title).group()[0:2]
day = re.search(r'\d{2}日', date_place_title).group()[0:2]
# 一番最後は土地名のようです
place = re.search(r'\s+\D+\Z', date_place_title).group()[1:]
sorted(list_time_pressure, key=lambda x:-x['time'])
もっとも時間が近い順に並べ替えています。
日付変わったら対応できないかな~と思ったら、前日のデータは日付が変わったタイミングでリセットされるわけではないらしかったので、これでいっています。
余談
ここで疲れたので記事を分割することにしました。