結構前
上司「humum君、うちの分析環境(オンプレ)の課題もろもろ解決しといて~。予算はまあまあとっといたから!」
ぼく「!?!?」
なんだかんだなんとかした
冒頭の無茶ぶりの結果、もろもろの検討や折衝、めんどうな社内稟議を経て
ビジネスサイドの社員が売上などのデータ分析をするためにAWS Redshift × BIツールの環境を提供しています。
その過程でRedshift君とだいぶ仲良くなれました。
結構いいやつなのでみんなにも知ってほしいのですが、彼は自分でしゃべれないので代わってこの記事で紹介させてもらいますね。
対象読者
・業務でRedshiftを触るけれどまだあまり仲良くない人
・分析基盤の調査や検討をしている人
・カジュアルにRedshiftを知れればいいやの人
それではレッツゴー
Redshift君のプロフィール
・フルマネージドのDWH(データウェアハウス)サービス
・postgreSQLを元にした列指向型DB
・「ノードスライス」「分散キー」による分散処理
だいたいこんなやつです
もうちょっと詳しく紹介しますね
フルマネージドのDWHサービス
インスタンス管理が楽。S3を介してデータロードで使います
updateやdeleteは滅多に使いません。COPYが爆速なので差分更新より洗い替えが推奨です
もちろんスケーラビリティが高いです。格納データ量にもよりますが、お願いすると数分~1日程度でスケールアウトしてくれます
(残念ながらサービス停止時間はゼロではない。。。がリサイズ中ずっとでもない)
postgreSQLを元にした列指向型DB
DWHといえば列指向ですよね
列のベクトルにデータを圧縮して保持するので、
・比較的データ圧縮が効く
・集計系のSQLが早い
という特徴を持っています。ちなみにトランザクションは張れます
集計の速さとは反対に一件のデータを取り出すようなクエリプランは遅いので、間違っても業務用RDBと一緒にしてはいけません
圧縮率はどんぶりで60%~80%くらい
RedshiftはpostgreSQLを元に開発されており、ほとんどのSQLは流用できます
が、関数で一部違うところもあるので気を付けて問い合わせてあげてください
また、postgreSQL同様にデッドタプルの考慮が必要です
データ量に比例してVACUUMコストが増大するので、なるべくVACUUMしなくて済む設計がベターです
サイズの大きいテーブルではディープコピーしてあげてください
「ノードスライス」「分散キー」による分散処理
やっと本題、これが一番の特徴です
DWHといっても色々ありますが、それぞれ分散処理や高速化のアプローチの仕組みが違います
Redshiftのスペックを引き出すには、「ノードスライス」「分散キー」を理解する必要があります
まず、
ノードスライス = ノード数×CPU数
各スライスにデータを分散して格納。各CPUにそれぞれ並列で分散処理をさせることで、高速化しています

また1テーブルに一つだけ、分散キーを指定できます
テーブルにデータをロードする際、この分散キーのカラム値のハッシュ値ごとにスライスに格納します

なお、他テーブルとJOINするクエリプランでは結合キーが別スライスに存在する場合のクエリプランはとても高コストです
え?
他テーブルとJOINするクエリプランでは結合キーが別スライスに存在する場合のクエリプランはとても高コストです
どういうこと?
次の場合のSQLで説明しますね
SELECT --salesテーブルにidsから名前をJOIN
SUM(売上)
, 名前
FROM
sales
INNER JOIN
ids
ON sales.id = ids.id
GROUP BY
名前
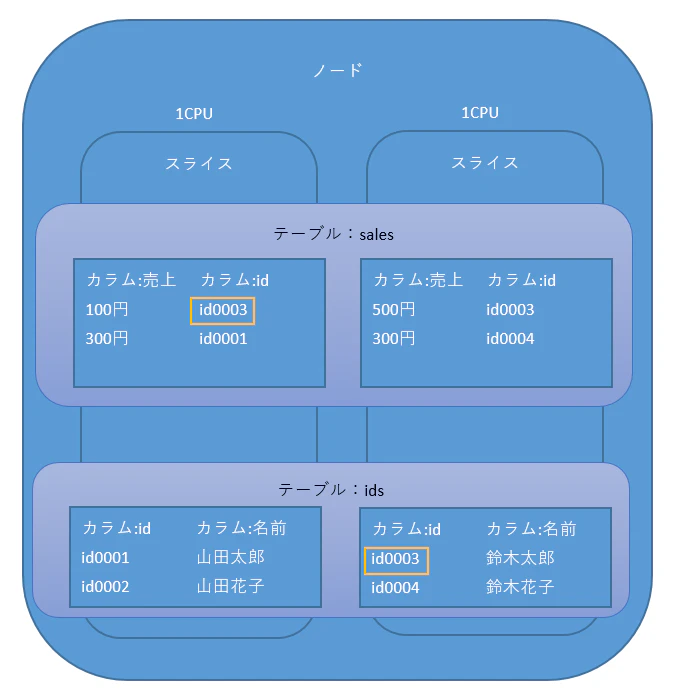
この時、左のスライスのsales.idの「id0003」は、別スライスである右側スライスのids.id「id0003」とそのままでは結合できません
上記の状態でクエリを実行すると、**闇の魔術「DS_BCAST_INNER」**が発動します
DS_BCAST_INNERとは、スライス内のデータを別スライスに再分散する実行計画です
発動するとSQLを実行してからスライス間でデータの再分散が始まります
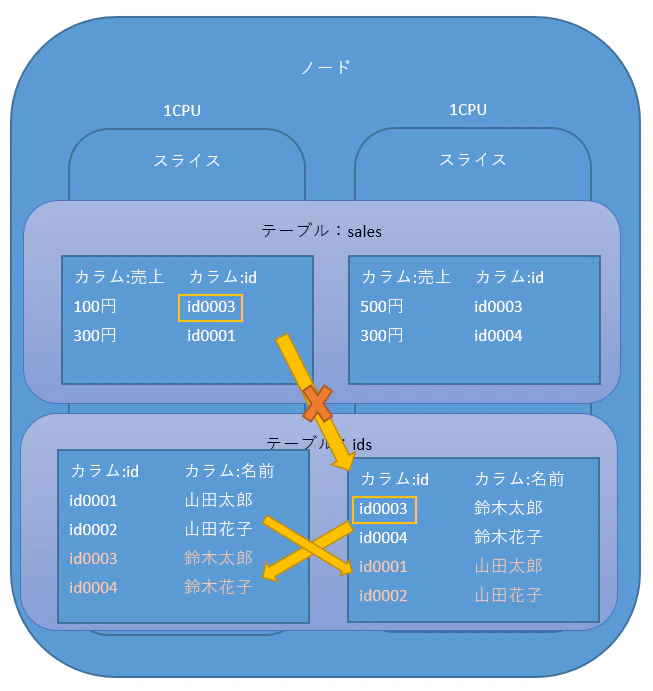
当然、高コストです
分散処理とか言ってる場合じゃありません
何も考えないで設計すると、たいていDS_BCAST_INNERの洗礼を頂きます
Redshift君気難しい。。。
回避策として、分散キーを指定せずデータ格納時に全てのスライスにテーブル全量のコピーを持たせる方法があります
当然的確な分散キーを指定した場合と比較して、スライス数分ディスク容量を使用するのでメタ情報などのテーブルでこの分散方法を選択します
今回の場合だと、データロード時にデータ容量が少なくなりそうなテーブル:idsのテーブルコピーを各スライスに全量格納するように分散方法を指定するのがベターです
テーブル設計時に、分散方式を「ALL」に指定します
CREATE TABLE public.ids (
ids CHARACTER(6) encode lzo
, 名前 CHARACTER VARYING(256) encode lzo
)
DISTSTYLE ALL;
というわけで、仲良くなる前にちゃんと手順を踏んで徐々に距離を詰めてあげてください
Redshift君「嫌なやつみたいになっとるやん!ちゃんと、良いところももっと書いてーなっ!!!」
しゃべった!?!?
次回、『ぼくの友達、Redshift君を持ち上げます』