sklearn.datasets.make_blobsのfeatureとcenterについて
featureについて
from sklearn.datasets.samples_generator import make_blobs
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
X, y = make_blobs(n_features=2, centers=3)
X_train, X_test, y_train, y_test = train_test_split(X, y)
model = KNeighborsClassifier()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
acc = accuracy_score(y_test, y_pred) * 100
print('accuracy: {}%'.format(acc))
n_featuresはどれだけのカラムまたは特徴量をデータセットに定義するかを決定する。
centerについて
center : intまたは形状の配列[n_centers、n_features]、オプション
(デフォルト=なし)生成する中心の数、または固定中心位置。n_samplesがintで、
centerがNoneの場合、3つの中心が生成されます。n_samplesが配列に似ている場合、centerは>Noneまたはn_samplesの長さに等しい長さの配列のいずれかでなければなりません。
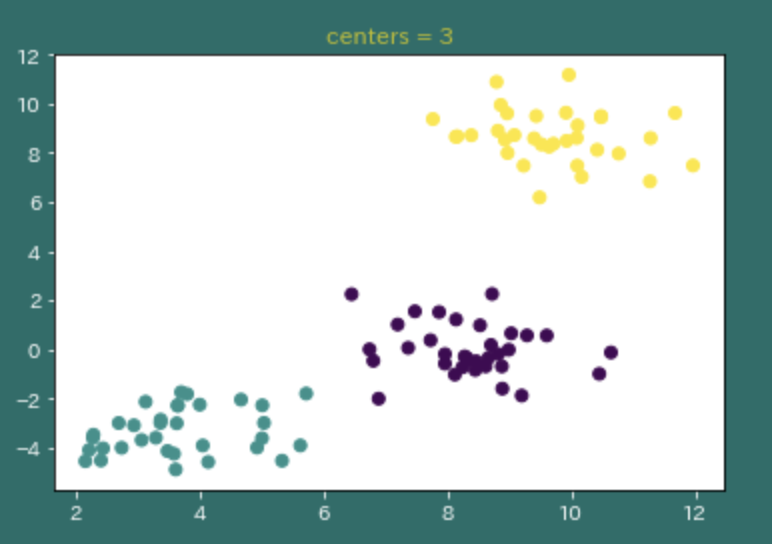
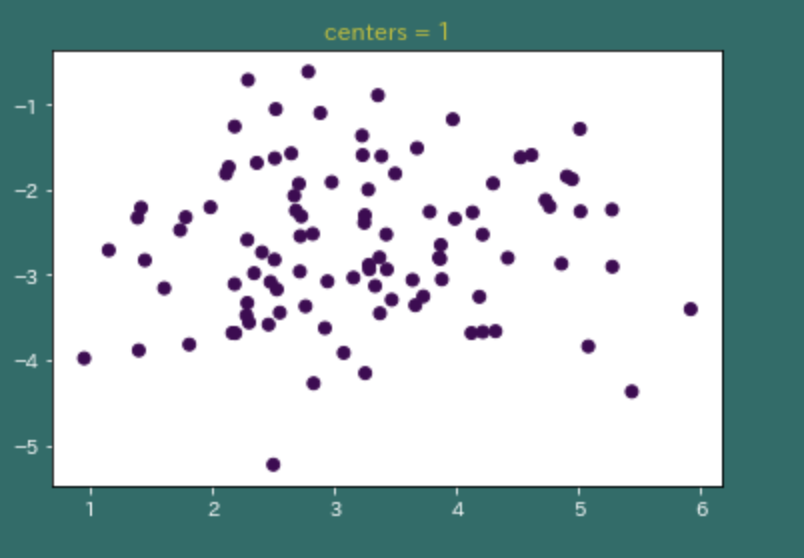
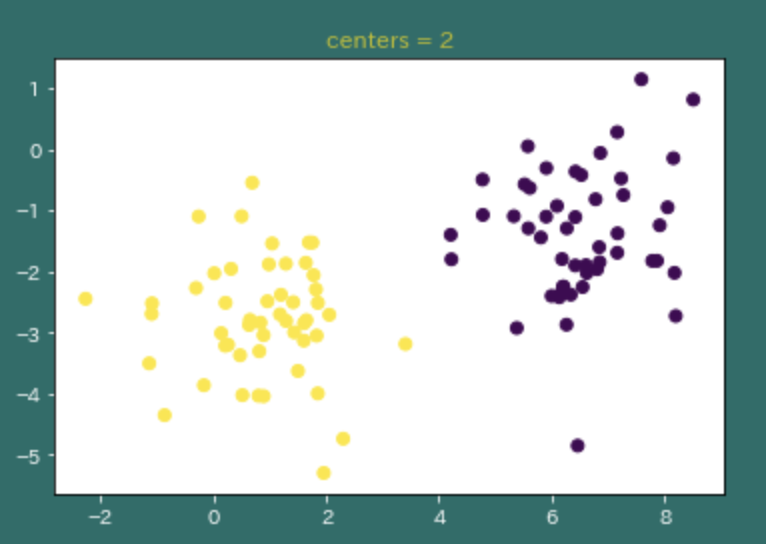
よくわからないので、プロットしてみた。
# plot 1 (centers=1)
X, y = make_blobs(n_features=2, centers=1)
plt.figure()
plt.scatter(X[:, 0], X[:, 1], c=y)
plt.savefig('centers_1.png')
plt.title('centers = 1')
# plot 2 ('centers = 2')
X, y = make_blobs(n_features=2, centers=2)
plt.figure()
plt.scatter(X[:, 0], X[:, 1], c=y)
plt.title('centers = 2')
# plot 3 ('centers = 3')
X, y = make_blobs(n_features=2, centers=3)
plt.figure()
plt.scatter(X[:, 0], X[:, 1], c=y)
plt.title('centers = 3')