はじめに
弊社で機械学習を扱う話が出てきたので、せっかくなので記事を書いてみることにしました。
今回は、クラウド上のリソースを使って機械学習を分散処理で動かせるサービスを紹介します。
MicrosoftAzureのクラウドサービス「Databricks」のサービス概要と、実際どんなふうに使えるのかといった点を、チュートリアル含めて紹介していこうと思います。
Azure Databricksとは?
データ分析のためのクラウドプラットフォームで、おおむね以下のような仕組みになっています。
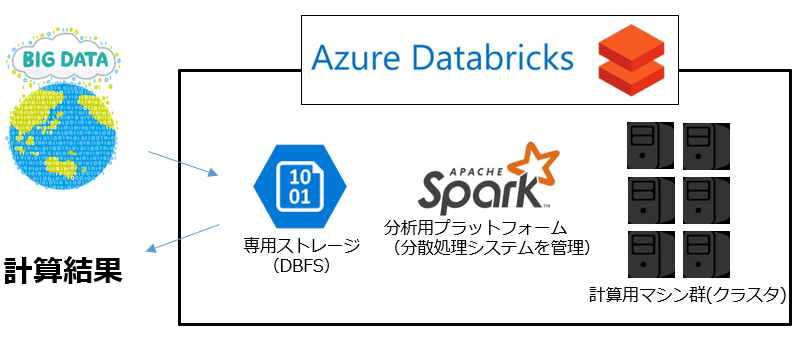
Databricksの裏には複数の計算用マシンが用意されます。
自分で任意に決定した性能・台数のマシンを、Apache Sparkを用いて分析して、素早く計算結果を得ることができます。
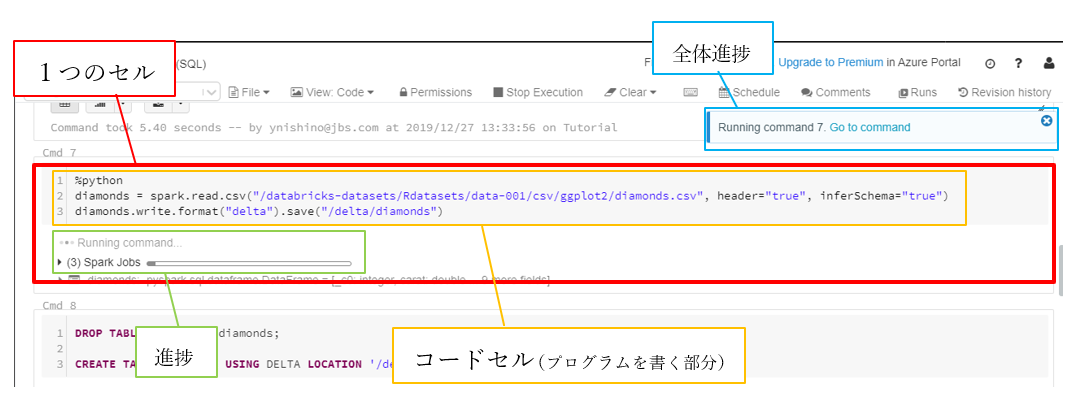
コーディングはJupyter Notebookのようなセル形式で行います。
サービスの特徴
-
PaaSの分散処理サービス
- Spaek環境が一瞬でデプロイできる
- 必要に応じて台数や性能を簡単に変更できる
-
Notebook形式でコーディング
- Python,Scala,R,SQL
- 同ノートブック内に複数言語を混在させることが可能
- Jupyterで慣れ親しんだ人にとっては使いやすいかも
- データの可視化が簡単
-
Azureの他サービスとの連携に強い
- BLOBストレージやデータベースに接続して、簡単にデータを持ってこれる
- DataFactoryと連携すれば、大規模データを定期的に処理することも可能
料金
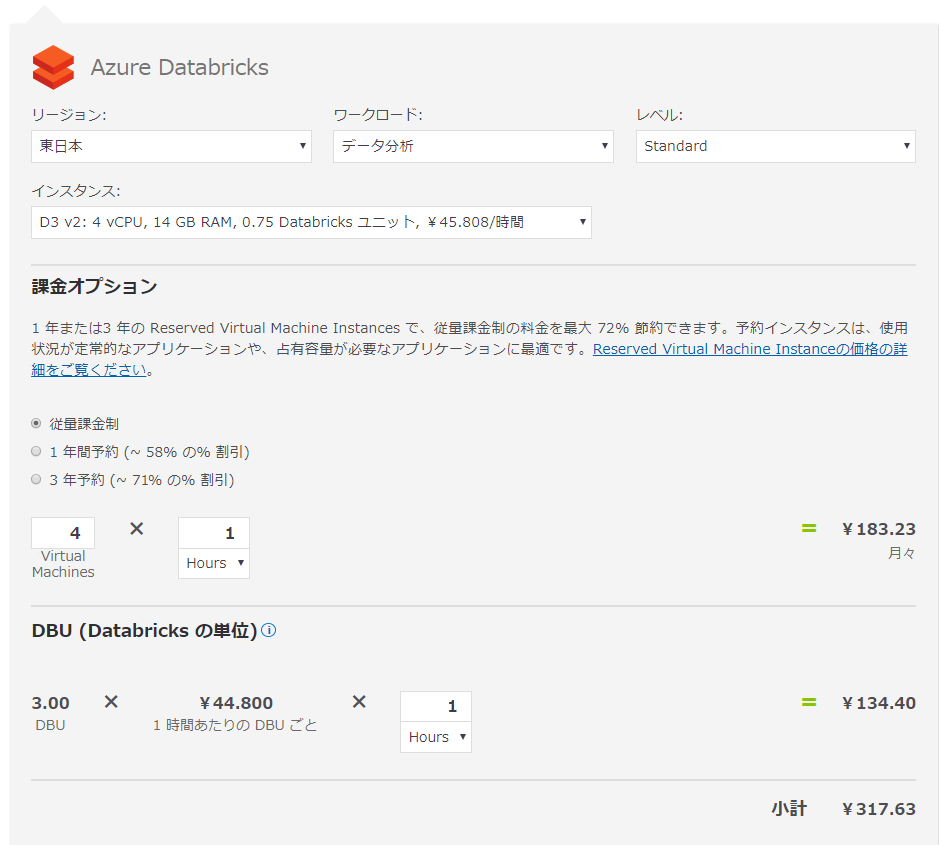
料金は、デプロイした仮想マシンの稼働時間と、Databricks側の定義する処理能力の単位(DBU)で決定されます。
仮に、最低スペックの4台の仮想マシンを1時間稼働させた場合のお値段想定が以下の通りでした。複数台デプロイしているので、そこそこの値段になっています。
実際にデプロイしてみた
AzureポータルでDatabricksをデプロイしていきます。
今回はリージョンを西日本としました。リソース詳細の中に「ワークスペースの起動」があるので、それをクリックします。
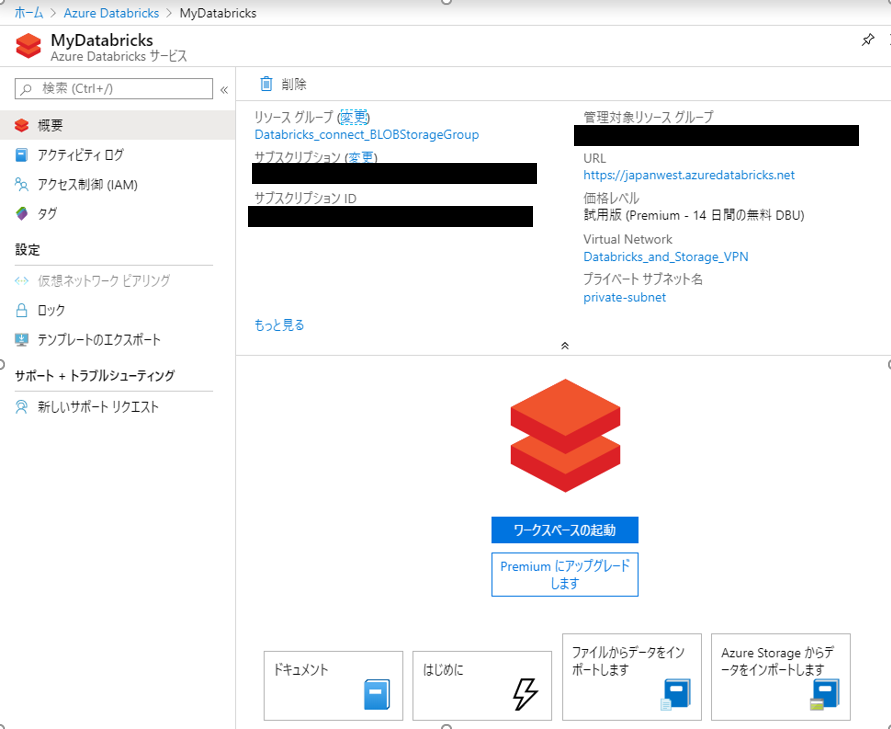
Databricksのダッシュボードが開きます。
今回はまず、左の一覧から「Clusters」で仮想マシンを作成します。
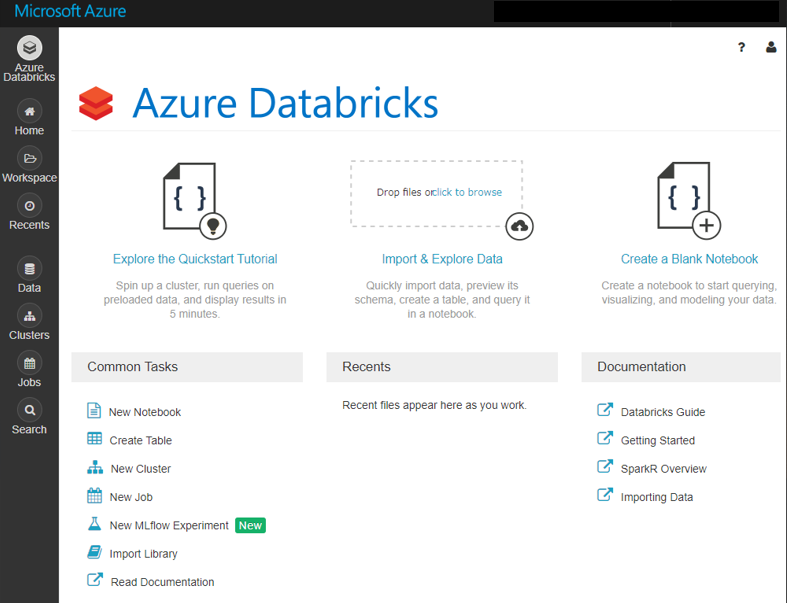
Create Clusterで新規に、プログラムを実行するためのクラスターを作成します。
WorkerTypeで仮想マシンの性能と台数を、DriverTypeでマスター(処理を管理するマシン)の性能を、それぞれ決定します。2台以上のワーカーと、1台のマスターが必要なので、最低でも合計3台の仮想マシンがデプロイされることになります。
GPU対応のワーカーも選択することができるようですが、2020年2月現在では、西日本リージョンでは利用できないようです。(米国リージョンの場合はデプロイできました)
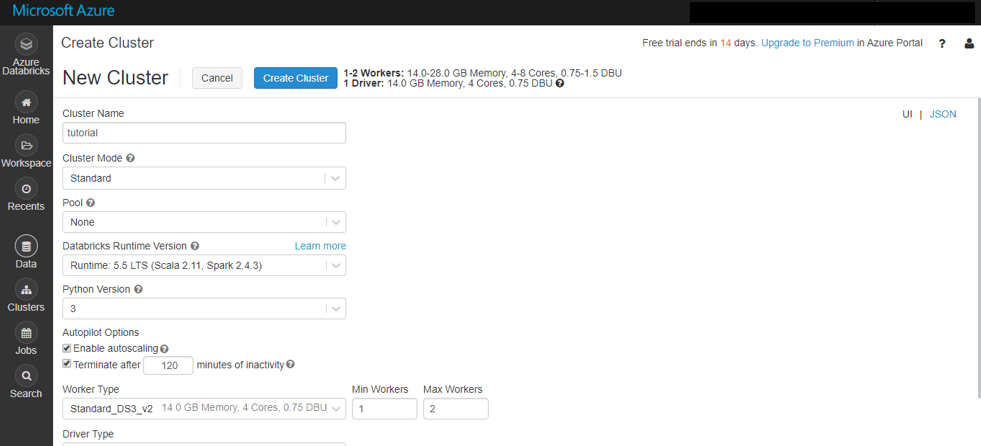
Pythonの場合、機械学習ライブラリ等を使いたい場合はPyPlを用いて、作成したクラスターにライブラリをインストールする必要があります。
色々試していたため、たくさんライブラリが入っていますが、今回はTensorFlowを使うのでクラスタを起動させた後に左上の「Install New」を行います。PyPlタブで「tensorflow」と入力して、インストールを済ませておいてください。
「Workspace」でコーディングを行い、機械学習のサンプルプログラムを走らせていくことにします。
ダッシュボードからNew Notebookを選択して、新しいノートブックを作成します。
### セル1###
# TensorFlowのインポート
import tensorflow as tf
# mnist(手書き数字のサンプルデータセット群)のロード
mnist = tf.keras.datasets.mnist
# mnistをロード後、深層学習が読み出せるように正規化
(x_train, y_train),(x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
# 分類問題を解くディープ・ニューラル・ネットワークの構造を定義
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512, activation=tf.nn.relu),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)
])
### セル2###
# ネットワークの最適化方法(学習アルゴリズム)を定義
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# モデルについて表示
# print(model.summary())
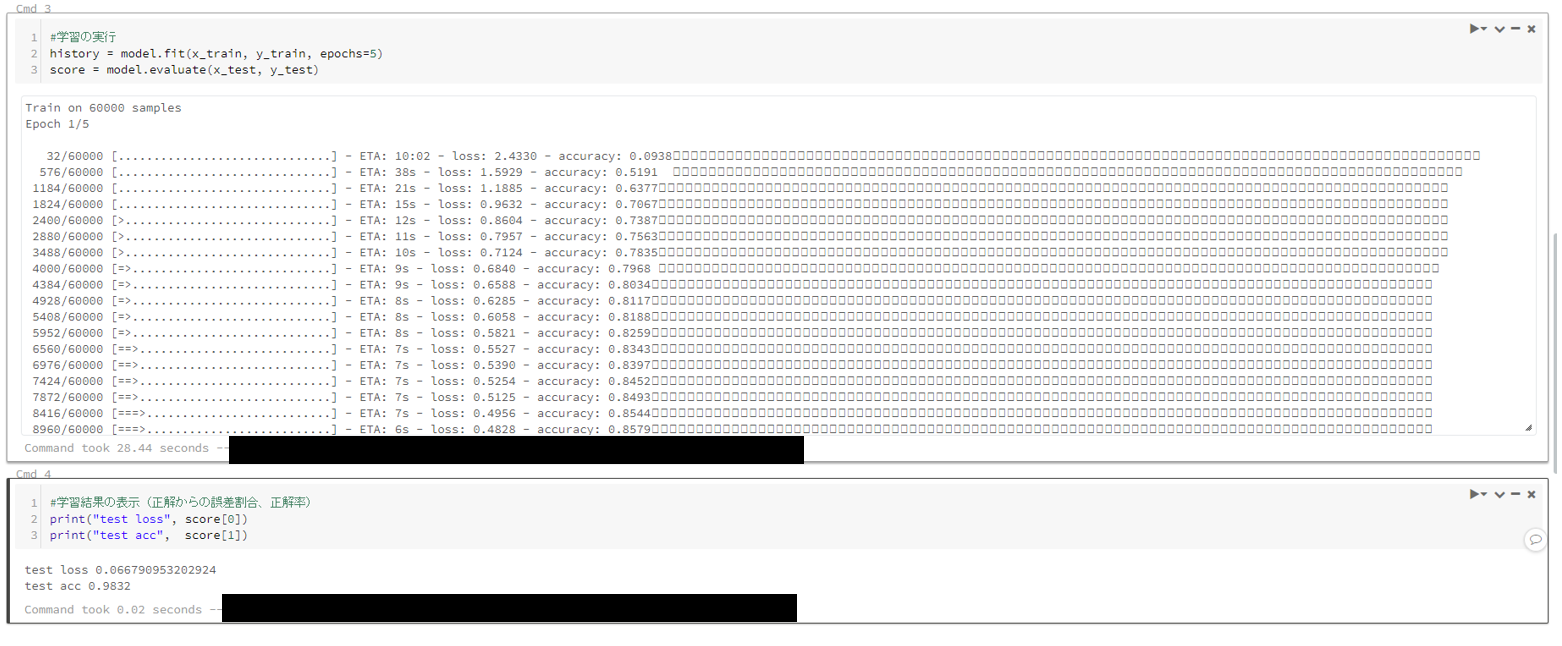
### セル3###
# 学習の実行
history = model.fit(x_train, y_train, epochs=5)
score = model.evaluate(x_test, y_test)
### セル4###
# 学習結果の表示(正解からの誤差割合、正解率)
print("test loss", score[0])
print("test acc", score[1])
学習結果はこの通りで、トレーニングの様子や実行時間が後から確認できます。
おわりに
簡単ですが、分析プラットフォームAzureDatabricksを触ってみたので、記事にしてみました。
他にもAzure NotebooksやDSVMなどの機械学習系サービスがあるようなので、そちらについても今後勉強していきたいと考えています。