Appleが最近MLXという機械学習用のフレームレートリリースしたので、
MLXフレームワークMistral 7B変換してM1 ultra メモリ64Gで検証したいと思います。
MLXとは
MLXは、Apple Silicon向けに設計された効率的かつ柔軟な機械学習用の配列フレームワークです。Appleの機械学習研究チームによって開発されました。Python APIはNumPyに非常に似ており、いくつかの例外を除いて、直感的に使用できます。また、Python APIに似たフル機能のC++ APIも提供しています。
今回はmlx使ってMistral 7BのモデルをApple Silicon最適化のモデルに変換して使います。
Mistral 7B
Mistral 7BはフランスのAIスタートアップMistral AI社が開発した大規模言語モデルで、Sliding Window Attention(SWA)やGrouped-query attention(GQA)といった新しい注意メカニズムを採用することで、Llama 2などよりも小さいモデルサイズで高い性能が得られているとされています。8Gメモリーでも動くことができます。
変換して使う
mlx-examples
# mlx-examplesをダウンロード
git clone https://github.com/ml-explore/mlx-examples.git
cd mlx-examples/mistral
pip install -r requirements.txt
Mistral 7Bモデルダウンロード
# 13.4Gあるので、時間かかります
curl -O https://files.mistral-7b-v0-1.mistral.ai/mistral-7B-v0.1.tar
tar -xf mistral-7B-v0.1.tar
mlx使ってApple Silicon最適化のモデルに変換
# モデル変換
python convert.py
Mistral 7B使う
# prompt入れる。tokenはデフォルト100なので、-mで変更できます
python mistral.py --prompt "It is a truth universally acknowledged," --temp 0 -m 200
結果
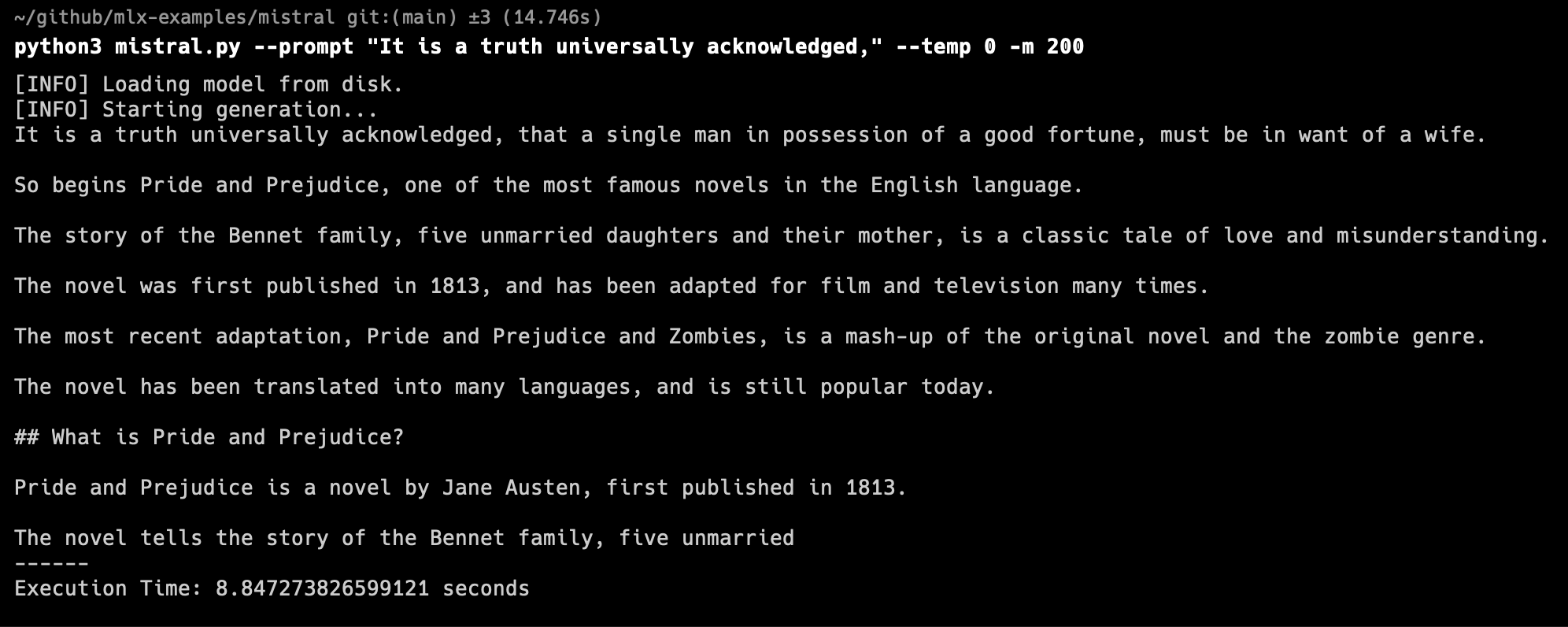
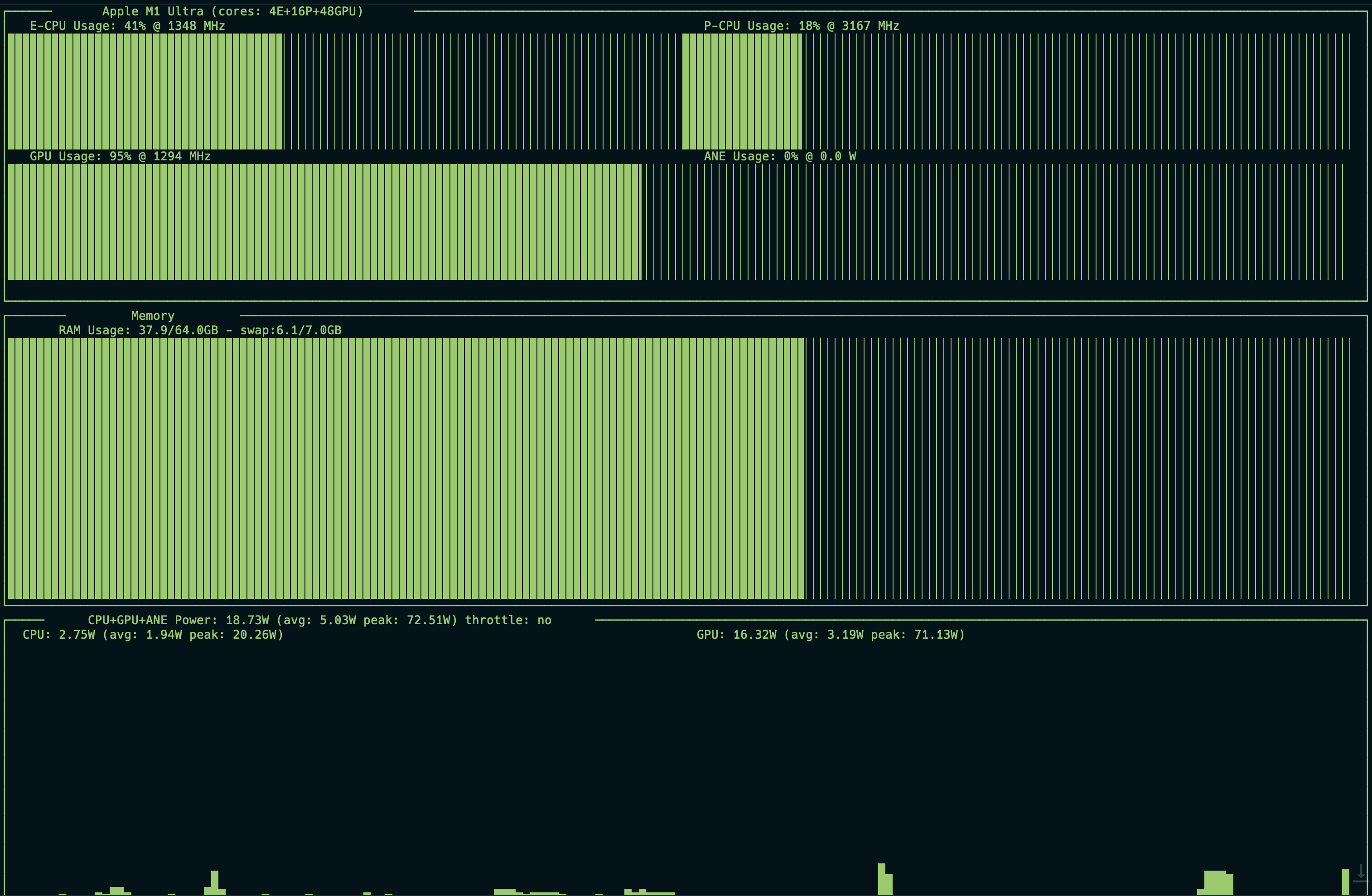
m1 ultraは余裕で動くことができました。
図の通りGPUとメモリーがつかわれてることがわかります。
強いGPUもってるwindows PCがもってないので、比べることはできませんでしたが、
Mistral実行時に16wぐらいしか電力消費してるのを驚きました.
ほか
mlx-examples内にもLLaMA2、Mixtral 8x7BとWhisperの変換例も書いてるのでそれも試せます。
LLaMA2:7bは8Gでも動きますが、Mixtral 8x7Bメモりだと100G以上メモリが必要です。
参考
https://github.com/ml-explore/mlx
https://github.com/ml-explore/mlx-examples
https://huggingface.co/mistralai/Mistral-7B-v0.1