HyDEとは?
HyDEは簡単にいうと、質問を一回LLMに回答させて、その内容でベクトル検索し、結果をコンテキストとして再度LLMに回答させる手法である。
元論文の図だとこんな感じ。

https://arxiv.org/pdf/2212.10496
- まずは一番左の黄色と緑のボックスの内容でGPTに問い合わせます
- 次にGPTの回答であるオレンジのボックスの内容をContrieverでベクトルにエンコードし、その内容で検索する。そうすることで青色ボックスの中身であるドキュメントを取得する
- それを用いて回答する
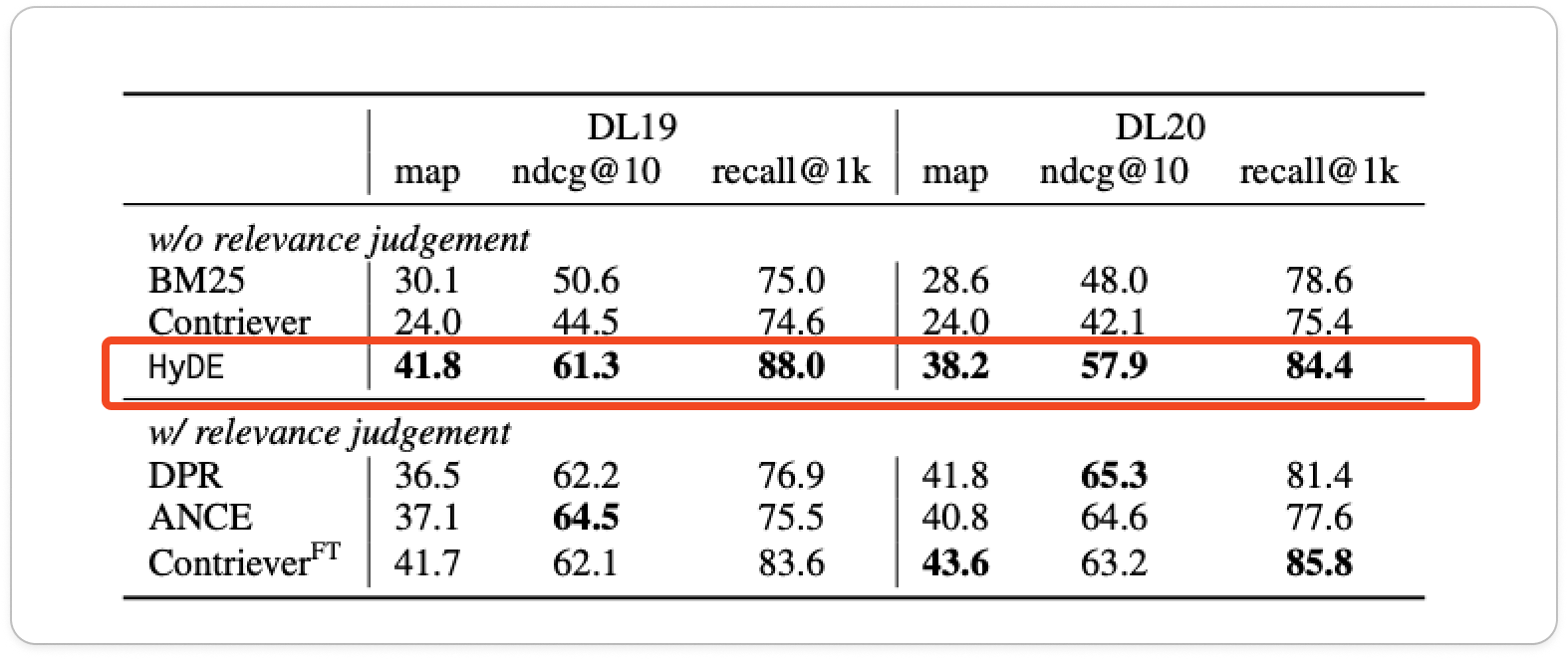
HyDEの精度
赤枠部分だけ解説すると、HyDEの方がBM25や生のContrieverだけより精度高いですね。
https://arxiv.org/pdf/2212.10496
HyDEを使う上で気をつけること
これだけ見るとすごいのですが、気をつけるべき時もあります。
以下の表を見てください。
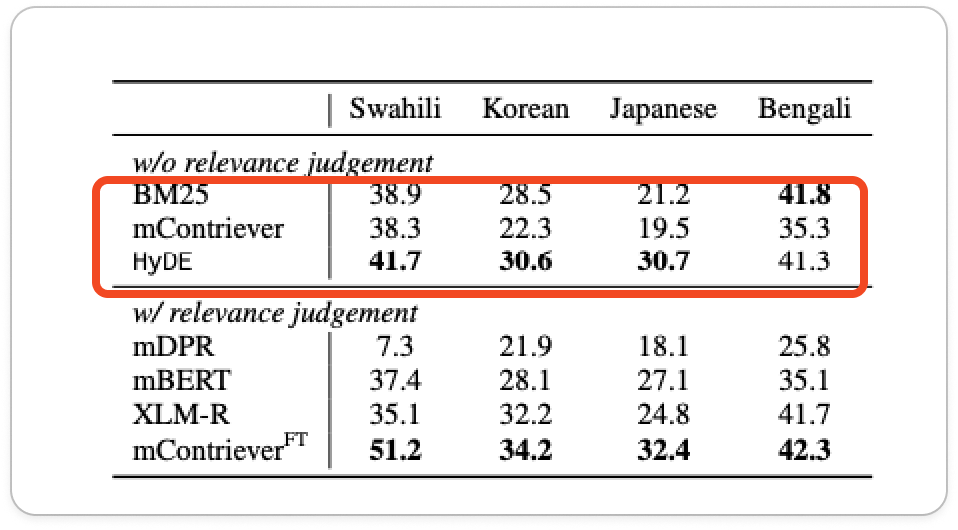
https://arxiv.org/pdf/2212.10496
気づきましたか? 実はベンガル語ではHyDEで大きく精度が変わってないのです。
論文中にも書かれていますが、
LLMがベンガル語自体の学習があまりできてなく仮想回答の精度が悪いことで、ドキュメント検索がうまくいかないことで精度があがらないのです。
つまり、ある程度の学習がうまく行っているパターンではHyDEは有効ですが、そうでないときはあまり有効でないのだと思います。
有効でない場合にHyDEを使ってしまうとただ単に回答が遅くなったり、最悪精度が悪くなる可能性があります。
使うときは慎重に使いましょう!
Difyで構築
全体像
全体像はこんな感じです。

流れは簡単です。
- まずは質問を仮想回答用LLMに問い合わせます
- 1の結果を使ってベクトル検索し知識を集めます。
- それを用いて回答します。
仮想回答 & 知識取得
仮想回答プロンプト:
Please write a passage to answer the question
Answer in English.
検索ドキュメントに英語が多い場合はここは英語で出力してた方がいい感じになります。

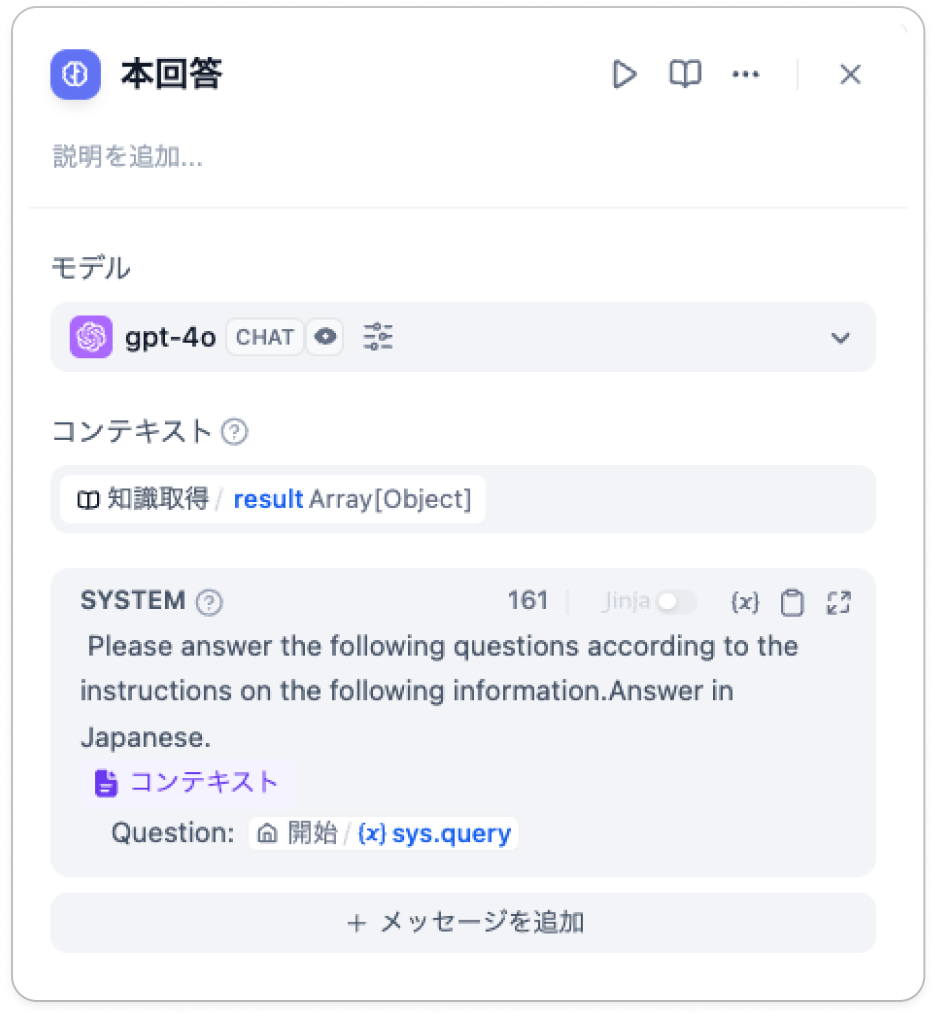
本回答
本回答プロンプト:
Please answer the following questions according to the instructions on the following information.Answer in Japanese.
{{#context#}}
Question: {{#sys.query#}}
最後に
Xやってるので気になる方はフォローお願いします。
https://x.com/hudebakonosoto