はじめに
Difyで作成したRAGを評価する方法が、今のところ見つけられなかったのでここに残しておきます。
評価するための連携方法を書くだけで、評価自体のことはほとんど書いていません。
Ragasについて
Ragasに関しては別ブログで記載しているのでそちらをご覧いただければと思います。
ここでも少し記載しておこうと思います。
Ragasで使用できる指標はいくつかあります。
- Faithfulness
- Answer relevancy
- Context recall
- Context precision
- Context relevancy
- Answer semantic similarity
- Answer correctness
etc …
Ragasではこの中でもRAGを評価する時に重要だとされる4つの指標を使います。
RAGはRetrievalとGenerationの二つのプロセスに分かれます。
Ragasの評価指標はそれぞれのプロセスを評価することができます。
Generation → faithfulness, answer relevancy
Retrieval → context precision, context recall
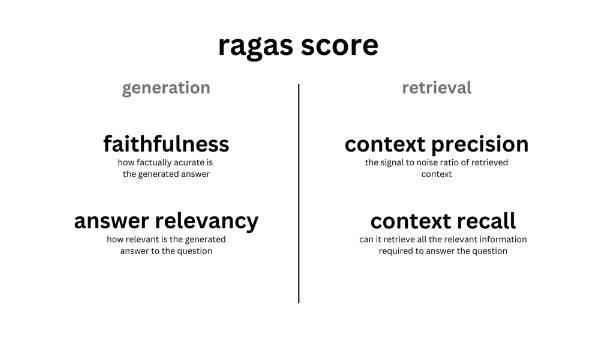
(https://docs.ragas.io/en/stable/concepts/metrics/index.html)
これらの評価指標は以下のデータに基づいて評価されます。
- Question : LLMに投げる質問
- Answer : LLMが生成する回答
- Context : Retrieverが取得してきた文献情報など
- Ground Truth : 参考となる正確な回答
これらのデータと評価指標の全体像は図のような形になっています。

Ragasの説明に関してはここまでにして、実際にDifyの評価でRagasを使うためにDifyとLangfuseとRagasをどのように連携させるかを書いていきます。
Difyのワークフロー
今回はこちらのワークフローの評価をRagasで行いたいと思います。
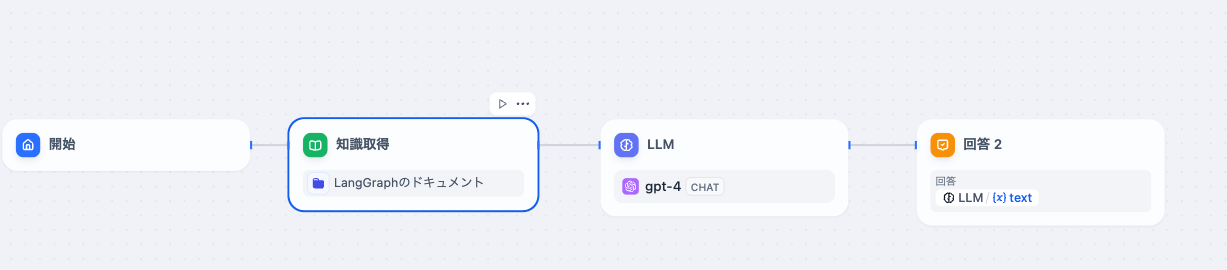
かなり単純なものにしています。
LangGraphについてRAGを構築し、それを評価するような形を取りたいと思います。
DifyとLangfuseの連携について
ローカルDifyとローカルLangfuseでの連携に関しては以下で書いているので、ローカルでやる方は以下をお読みください。
ここまでできたら質問をいくつかしてデータをLangfuseに送っておいてください。
LangfuseとRagas連携のコード
では実際にDifyから送信されたLangfuseのデータをRagasで検証していきましょう。こちらを参考に構築していきます。
まずは環境変数を設定してください。
import os
os.environ["LANGFUSE_SECRET_KEY"] = "LANGFUSE_SECRET_KEY"
os.environ["LANGFUSE_PUBLIC_KEY"] = "LANGFUSE_PUBLIC_KEY"
os.environ["LANGFUSE_HOST"] ="LANGFUSE_HOST"
os.environ["OPENAI_API_KEY"] = "OPENAI_API_KEY"
次にLangfuseのクライアントを用意します。
from langfuse import Langfuse
langfuse = Langfuse()
そしてDifyがLangfuseに送信したトレースを取得するメソッドを用意します。
def get_generations(name=None, limit=None, user_id=None):
all_data = []
page = 1
while True:
response = langfuse.get_generations(
name=name, page=page, user_id=user_id
)
if not response.data:
break
page += 1
all_data.extend(response.data)
if len(all_data) > limit: # type: ignore
break
return all_data[:limit]
Cookbookではtraceを取得指定しましたが、Traceの中身からContextを取得できないのでTraceではなくGenerationを取得してきました。Generationだとちゃんと以下のようにContextも質問も入っています。
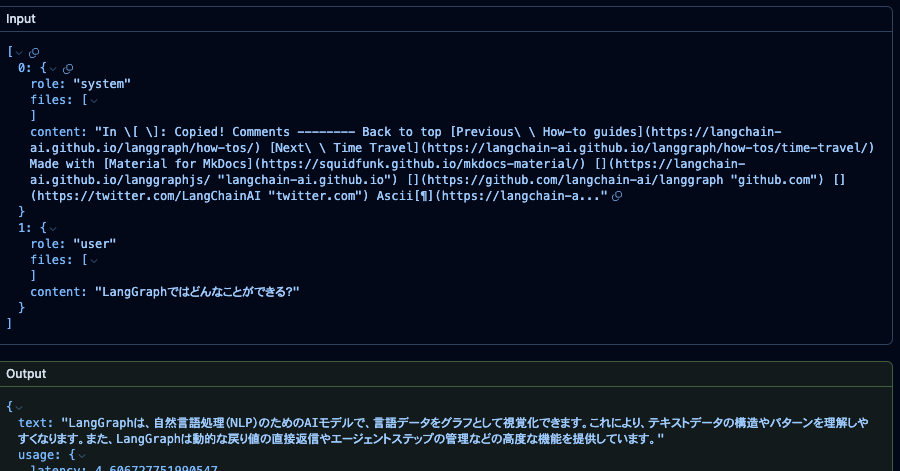
そしてサンプルをランダムに取得します。
from random import sample
NUM_TRACES_TO_SAMPLE = 3
traces = get_generations(limit=5)
traces_sample = sample(traces, NUM_TRACES_TO_SAMPLE)
len(traces_sample)
traces_sample
以下のコードでquestion、context、answerに分けます。
trace_idとobservation_idの両方を入れておかないとGenerationとの紐付けができないので注意です。
evaluation_batch = {
"question": [],
"contexts": [],
"answer": [],
"trace_id": [],
"observation_id": []
}
for t in traces_sample:
observations = t
d = dict(observations)
question = ""
context = []
for item in d["input"]:
if item["role"] == "user":
question = item["content"]
elif item["role"] == "system":
context.append(item["content"])
evaluation_batch["question"].append(question)
evaluation_batch["contexts"].append(context)
if "output" in d and "text" in d["output"]:
evaluation_batch["answer"].append(d["output"]["text"])
evaluation_batch["trace_id"].append(t.trace_id)
evaluation_batch["observation_id"].append(t.id)
そして以下のコードでRagasを実行してください。
from datasets import Dataset
from ragas import evaluate
from ragas.metrics import faithfulness, answer_relevancy
ds = Dataset.from_dict(evaluation_batch)
r = evaluate(ds, metrics=[faithfulness, answer_relevancy])
最後にLangfuseに送りましょう。
df = r.to_pandas()
df["trace_id"] = ds["trace_id"]
df["observation_id"] = ds["observation_id"]
df.head()
for _, row in df.iterrows():
for metric_name in ["faithfulness", "answer_relevancy"]:
langfuse.score(
name=metric_name,
value=row[metric_name],
trace_id=row["trace_id"],
observation_id=row["observation_id"]
)
評価結果
Langfuseで以下のような評価結果が得られます。
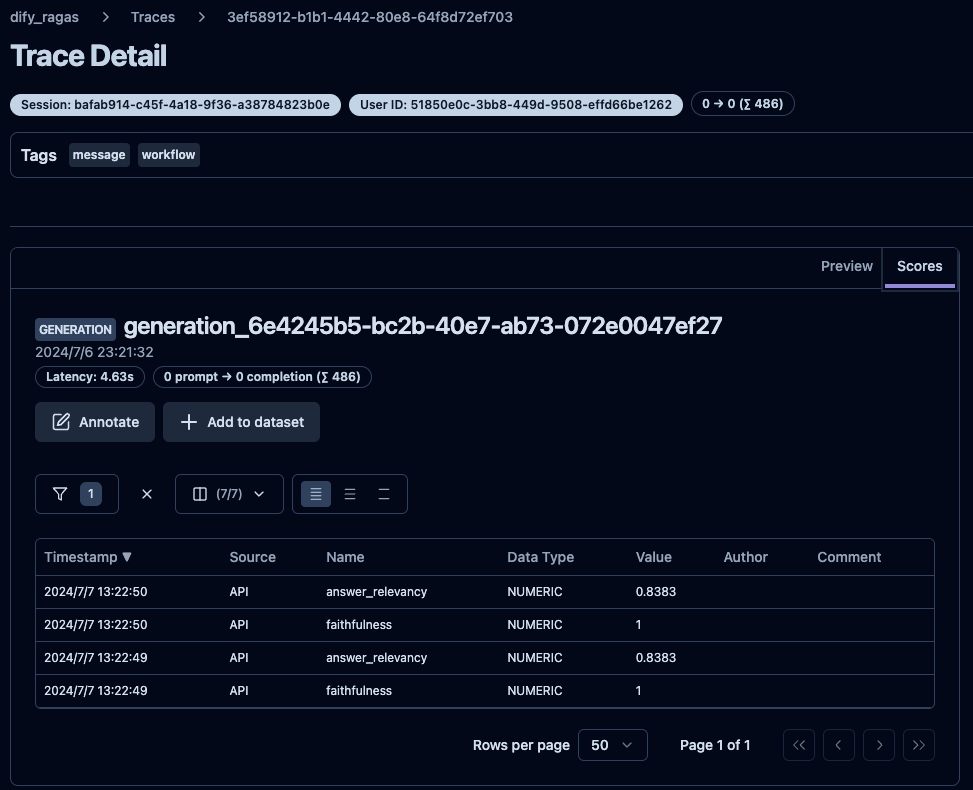
いい感じです。今後はこんな感じでDifyでは評価していこうと思います。
最後に
Difyで作成したRAGを評価する方法の記事が今のところなかったので書きました。
他にいい方法があれば教えてください!
Xをやっているので気になる方はフォローお願いします。
https://x.com/hudebakonosoto