PoseNetモデルを使用して、画像内の誰かの肘、肩、足など、画像やビデオから人間のポーズを検出する方法を示す例。
Coral PoseNet
姿勢推定とは、画像やビデオで人物を検出するコンピュータービジョン技術のことで、たとえば、誰かの肘、肩、または足が画像のどこに現れるかを判断できます。 PoseNetは画像内のだれを認識せず、単に主要な関節がどこにあるかを推定しています。
このレポには、CoralのEdge TPUで使用するために量子化および最適化されたPoseNetモデルのセットと、カメラストリームで実行する方法を示すサンプルコードが含まれています。
PoseNetを選ぶ理由
姿勢推定には、身体に反応するインタラクティブなインスタレーションから、拡張現実、アニメーション、フィットネスの使用など、多くの用途があります。 このモデルのアクセシビリティにより、より多くの開発者やメーカーが実験を行い、独自のプロジェクトに姿勢検出を適用して、匿名でプライベートな方法で機械学習を展開する方法を実証できることを願っています。
どのように機能しますか?
高レベルのポーズ推定は、2つのフェーズで行われます。
-
入力RGB画像は、畳み込みニューラルネットワークを介して供給されます。私たちの場合、これは
MobileNet V1アーキテクチャです。ただし、分類ヘッドの代わりに、一連のヒートマップ(キーポイントの種類ごとに1つ)といくつかのオフセットマップを生成する特殊なヘッドがあります。このステップはEdgeTPUで実行されます。結果はステップ2)に送られます -
特別なマルチポーズデコードアルゴリズムを使用して、ポーズ、ポーズ信頼スコア、キーポイント位置、キーポイント信頼スコアをデコードします。
TensorflowJSバージョンとは異なり、Tensorflow LiteでカスタムOPを作成し、ネットワークグラフ自体に追加したことに注意してください。このCustomOPは、後処理ステップとして(CPU上で)デコードを行います。利点は、ヒートマップを直接処理する必要がないことです。その後、Coral Python APIを介してこのネットワークを呼び出すと、ネットワークから一連のキーポイントを取得するだけです。
デコードアルゴリズムの詳細とPoseNetが内部でどのように機能するかに興味がある場合は、元の研究論文または畳み込みモデルによって生成された生のヒートマップについて説明しているこの中記事をご覧になることをお勧めします。
重要な概念
ポーズ:最高レベルでは、PoseNetは、検出された各人物のキーポイントのリストとインスタンスレベルの信頼スコアを含むポーズオブジェクトを返します。
キーポイント:鼻、右耳、左膝、右足など、推定される人物のポーズの一部。位置とキーポイント信頼スコアの両方が含まれます。 PoseNetは現在、次の図に示す17個のキーポイントを検出します:
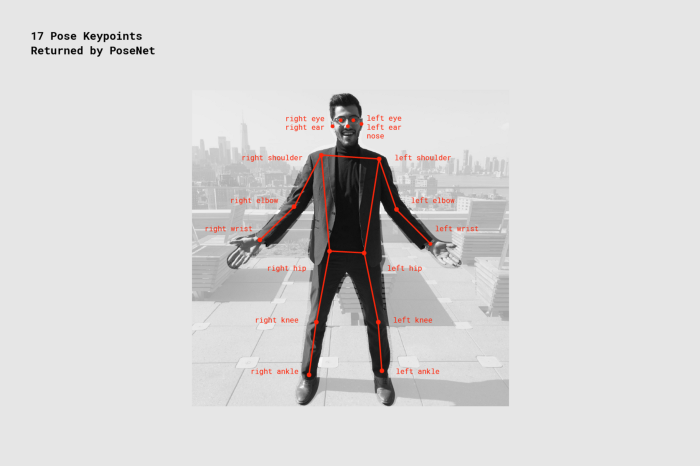
キーポイント信頼スコア:これは、推定キーポイント位置が正確であるという信頼を決定します。 範囲は0.0〜1.0です。 十分に強いとはいえないキーポイントを隠すために使用できます。
キーポイントの位置:キーポイントが検出された元の入力画像の2D xおよびy座標。
このレポの例
注:PoseNetは最新のCoral API(2.11.1)に依存しています。これらの例を実行する前にシステムを更新してください。すべての要件をインストールするには、単に実行します:
sh install_requirements.sh
simple_pose.py
単純に画像をダウンロードし、ポーズキーポイントを印刷する最小限の例。
python3 simple_pose.py
pose_camera.py
カメラ画像をポーズネットを介してストリーミングし、ポーズをオーバーレイとして上に描画するカメラの例。 これは、ネットワークとその出力に慣れるために実行する最初の素晴らしい例です。
次のような簡単なデモを実行します:
python3 pose_camera.py
カメラとモニターの両方が正面を向いている場合は、-mirrorフラグを追加することを検討してください:
python3 pose_camera.py --mirror
このレポには、differnet入力解像度用の3つのポーズネットモデルファイルが含まれています。 もちろん、解像度を大きくすると速度は遅くなりますが、視野を広くしたり、遠くのポーズを正しく処理したりできます。
posenet_mobilenet_v1_075_721_1281_quant_decoder_edgetpu.tflite
posenet_mobilenet_v1_075_481_641_quant_decoder_edgetpu.tflite
posenet_mobilenet_v1_075_353_481_quant_decoder_edgetpu.tflite
--resパラメーターを使用して、カメラの解像度を変更できます:
python3 pose_camera.py --res 480x360 # fast but low res
python3 pose_camera.py --res 640x480 # default
python3 pose_camera.py --res 1280x720 # slower but high res
anonymizer.py
CoralとPoseNetを使用して匿名でプライバシーを保護する方法で人間の行動を分析する方法を示す楽しい小さなアプリ。
Posenetは、人間の画像を単なるスケルトンに変換します。このスケルトンは、時間の経過とともにその位置と動きをキャプチャしますが、正確に識別する機能と元のカメラ画像は破棄します。 Coralデバイスはすべての画像分析をローカルで実行するため、実際の画像はどこにもストリーミングされず、すぐに破棄されます。ポーズは安全に保存または分析できます。
たとえば、店舗のオーナーは、フローを最適化して商品の配置を改善するために、店舗を移動する顧客の行動を調査することができます。博物館は、どのエリアで最も混雑しているのかを追跡したい場合があります。たとえば、どの展示が現在待ち時間が最も短いかを示すためです。
Coralを使用すると、誰の画像も直接記録したり、クラウドサービスにデータをストリーミングしたりすることなく可能です。代わりに、画像はすぐに破棄されます。
anaonymizerは、これが楽しい方法であることを示す小さなアプリです。アノニマイザーを使用するには、カメラを頑丈な位置にセットアップします。アプリを起動し、画像から出ます。このデモは、フレームに誰もいなくなるまで待機し、「背景」画像を保存します。さあ、一歩下がってください。現在のポーズが背景の静止画像の上に重ねて表示されます。
python3 anonymizer.py
(カメラとモニターの両方が手前にある場合は、-mirrorフラグを追加することを検討してください。)

synthesizer.py
このデモでは、音楽シンセサイザーを腕で制御できます。 最大3人がそれぞれ異なる楽器とオクターブを割り当てられ、右手首でピッチを、左手首で音量を制御します。
FluidSynthとGeneral Midi SoundFontをインストールする必要があります:
apt install fluidsynth fluid-soundfont-gm
pip3 install pyfluidsynth
これで、次のようにデモを実行できます:
python3 synthesizer.py
The PoseEngine class
PoseEngineクラス(pose_engine.pyで定義)を使用すると、EdgeTPU APIを使用して、PythonからPoseNetネットワークに簡単にアクセスできます。
モデルの.tfliteファイルの場所でクラスを初期化し、DetectPosesInImageを呼び出して、イメージを含むnumpyオブジェクトを渡すだけです。 numpyオブジェクトはint8、[Y、X、RGB]形式である必要があります。
最小限の例は次のとおりです:
import numpy as np
from PIL import Image
from pose_engine import PoseEngine
pil_image = Image.open('couple.jpg')
pil_image.resize((641, 481), Image.NEAREST)
engine = PoseEngine('models/posenet_mobilenet_v1_075_481_641_quant_decoder_edgetpu.tflite')
poses, inference_time = engine.DetectPosesInImage(np.uint8(pil_image))
print('Inference time: %.fms'%inference_time)
for pose in poses:
if pose.score < 0.4: continue
print('\nPose Score: ', pose.score)
for label, keypoint in pose.keypoints.items():
print(' %-20s x=%-4d y=%-4d score=%.1f'%
(label, keypoint.yx[1], keypoint.yx[0], keypoint.score))
これを試すには、実行してください:
python3 simple_pose.py
そして、次のような出力が表示されるはずです:
Pose Score: 0.61885977
nose x=210 y=152 score=1.0
left eye x=224 y=138 score=1.0
right eye x=199 y=136 score=1.0
left ear x=245 y=135 score=1.0
right ear x=183 y=129 score=0.8
left shoulder x=268 y=168 score=0.8
right shoulder x=161 y=172 score=1.0
left elbow x=282 y=255 score=0.6
right elbow x=154 y=254 score=0.9
left wrist x=236 y=333 score=0.7
right wrist x=163 y=301 score=0.6
left hip x=323 y=181 score=0.2
right hip x=191 y=251 score=0.0
left knee x=343 y=84 score=0.8
right knee x=162 y=295 score=0.0
left ankle x=318 y=174 score=0.1
right ankle x=167 y=309 score=0.0
- Google Coral Edge TPU 官方海外代理店: https://store.gravitylink.com/global