はじめに
Elasticsearchでクラスタ設計する際にData NodeにどのくらいMemoryとSSDを搭載するのが正しいのか
調べてみましたので、備忘録として本記事を書いてみました。
【参考】
・Elastic Stack実践ガイド[Logstash/Beats編]
利用バージョン
Elasticsearch 6.6.1
概要図
こんなイメージになるのかなと思っています。
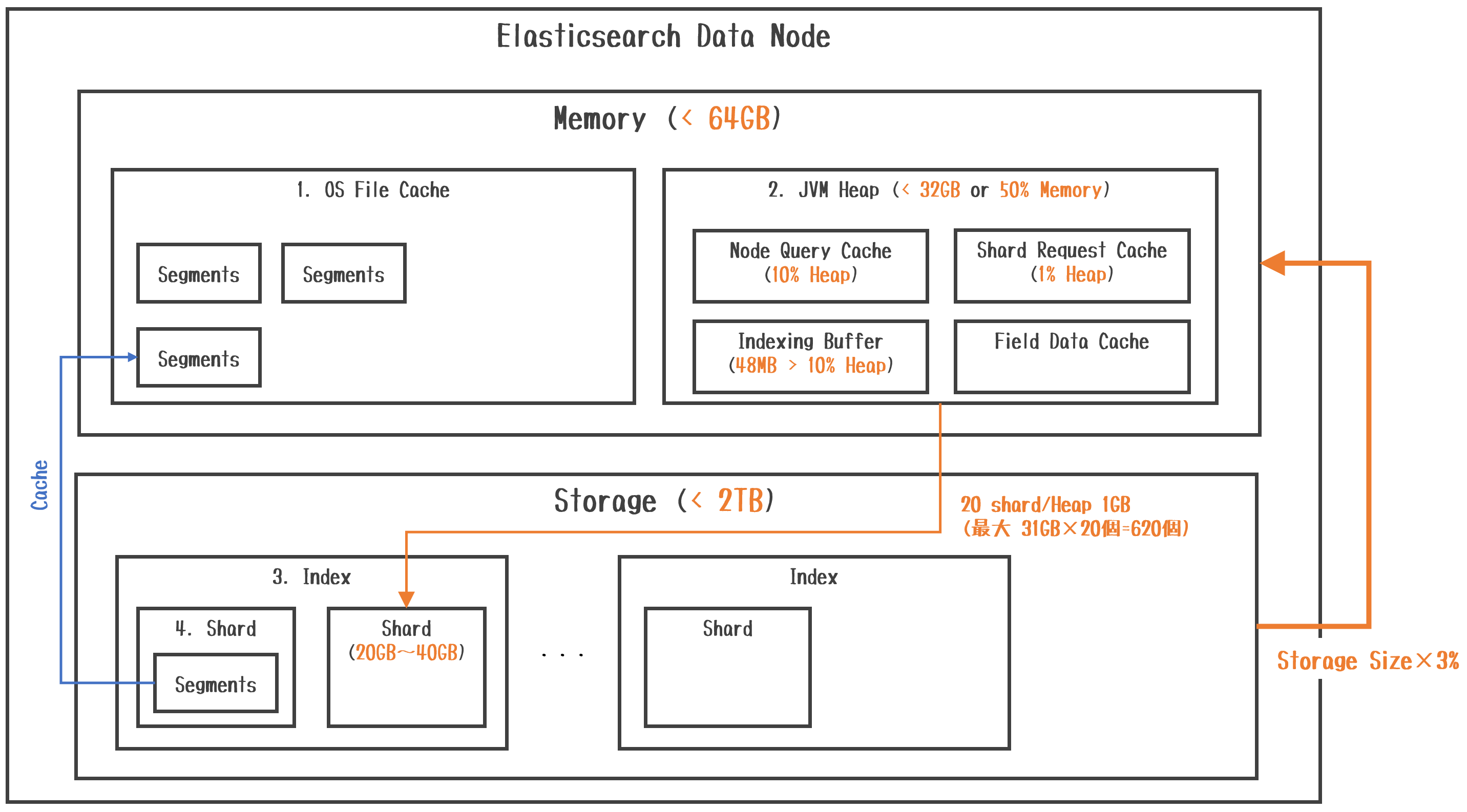
各コンポーネントの説明
Memoryについて
- Memoryは、OS File CacheとJVM Heapで構成されます。
- JVM Heapは、Node Query Cache、Shard Request Cache、Indexing Buffer、Field Data Cacheで構成されます。
- OS File Cacheは、クエリ結果の対象となったStorage上にあるSegmentをキャッシュする領域になります。
- Node Query Cacheは、Node内の全Shardで共有されるクエリ結果をキャッシュする領域になります。
- Shard Request Cacheは、Node内の各Shardのローカル検索結果をキャッシュする領域になります。
- Indexing Bufferは、IndexingされるDocumentを保持するバッファ領域で一杯になるとStorage上のSegmentに書き込まれます。
- Field Data Cacheは、Fieldデータの集計をソートしたり計算する時に使用するキャッシュ領域になります。
【参考】
・Node Query Cache
・Indexing Buffer
・Shard request cache
・Field data cache
Storageについて
- Indexは、RDBで言うところのTableです。スキーマを定義(Index Setting)してDocumentを格納していきます。
- Shardは、Index内のDocumentを複数Nodeに分散させてスケールアウトさせるための論理的な単位です。
- Segmentは、Index内のDocumentを保持する物理的な単位です。
サイジングの考え方
-
JVM Heapは、Memoryの
半分(50%)もしくは32GB未満にします。※32GB以上割り当てると性能が劣化します。 -
JVM Heapの1GBに対して、Storage内のShardを
20個以下にします。※31GB×20個=620個なので、600個/ノードに抑えます。 -
Shardの大きさは格納するDocument次第ですが、
20~40GBに収めます。 - Shardで悩ましいのは、Primary Shard数を2個以上に増やすとAggregationでの集計結果が正しく無くなる可能性があるということです。
- MemoryサイズはIndexを格納するStorage容量の
3%以上を確保します。※Storageが2TBの場合、2,048GB×0.03=61.44GBになります。 - Data NodeのStorageはIO重視なので、推奨はDAS(Direct Attached Storage)で
NVMe形式のSSDになります。※AWS EC2だとi3インスタンスです。
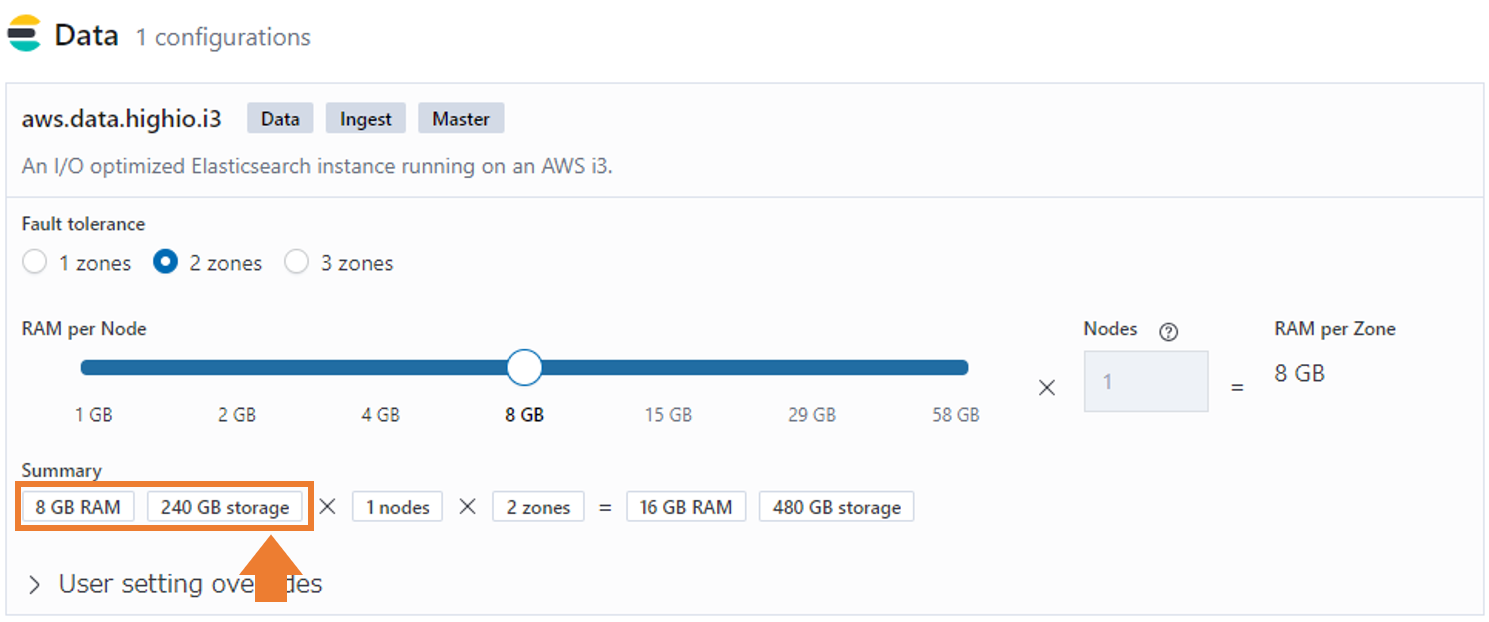
以下はElastic CloudのHighIOのData Nodeのデフォルト値です。Storage240GBに対して、Memory8GBなので、3%ルールに乗っ取っています。
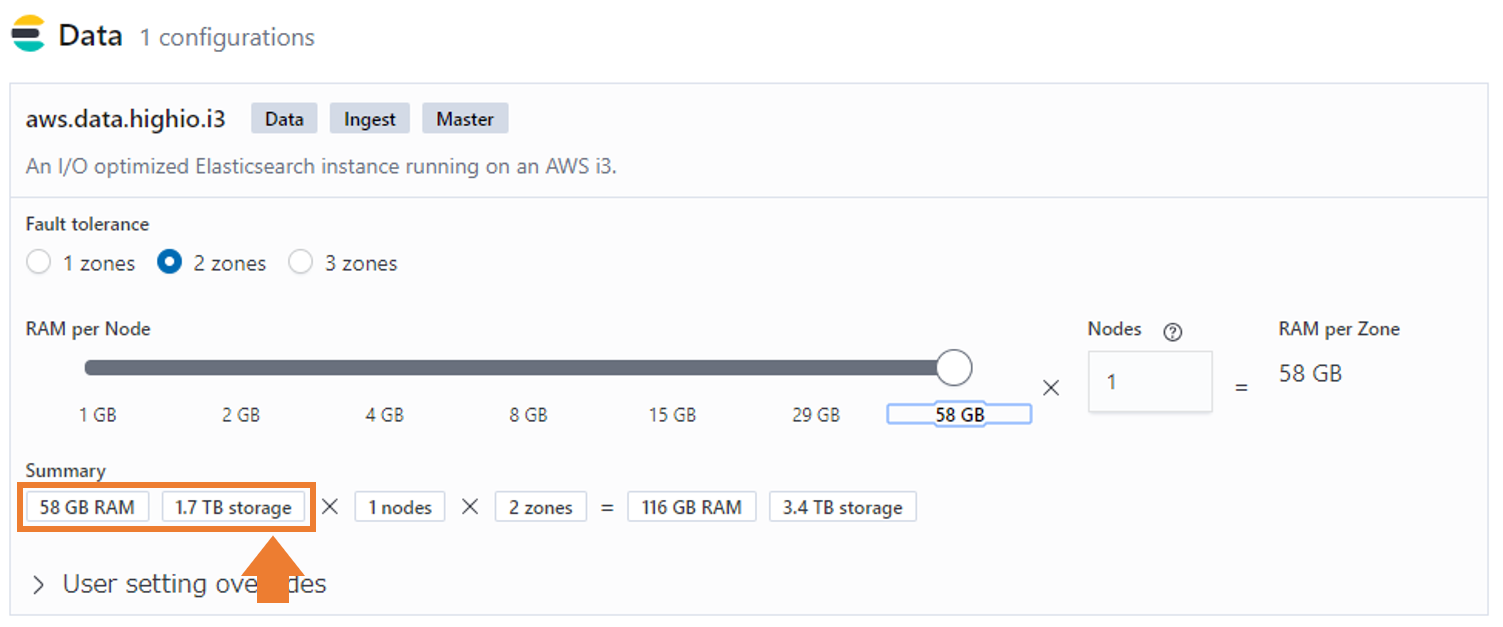
また1台のData Nodeの最大Memory容量は58GB(Storageが1.7TB)となっていて、さらにスケールさせる場合はNode数を増やすしかないようです。
- 上記よりMemoryの推奨サイズは
2TBのStorageに対して64GB、その半分以下の31GBをJVM Heapに割り当てるのが良さそうです。
【参考】
・Why 35GB Heap is Less Than 32GB – Java JVM Memory Oddities
・How many shards should I have in my Elasticsearch cluster?
2020/06/10追記
Elasticsearch 7.7からJVMヒープの使われ方が変わったようです。
より効率的にヒープ領域が利用でき、多くのデータを抱えられるようになりました。
【参考】
・Elasticsearchヒープのメモリ使用量を大幅に削減する
まとめ
色々と考えてみたんですが、JVM Heapは最大31GBですが、OS File Cacheを32GB以上にして
Segmentのキャッシュを増やすことでStorageも大きく出来ると考えていたんですが、やめた方が良いのでしょうか。
書き込みが終了したIndexに対して、Force mergeを定期的に実行することでSegment数が減り
JVM HeapのMemory節約になって、より多くのMemoryとStorageが詰めるのではないかと思った次第でした。
また、1個のShardを20GBで計算すると、1台のData Nodeは最大で600個×20GBで12TBのSSDを積んでも良いことになります。
ですが、恐らくそれだとMemoryのOS File Cacheを増やさないとMemory溢れを起こすと思いますが
64GBを超えて大量にMemoryを積んでもちゃんと性能を落とさずにキャッシュでSearch出来るのか?、、、というのが分かりませんでした。
特にField Data Cacheが足りなくなるのではないかという気がしているのですが、認識は合っているのか。
NodeあたりのCPU性能やIO分散を考えるとNodeをクラスタに追加してクラスタを大きくするのが良いと思いますが
Nodeが増えると購入するElasticサブスクリプションが増えるので、なかなか悩ましい問題ですね。