はじめに
つい先日、久しぶりにAWSのVPCでフローログの作成をしました。
するとなんと、、CloudWatch Logsへの送信で**Custom format(カスタム形式)**にチェックを入れられるではないですか!!( ゚д゚)/
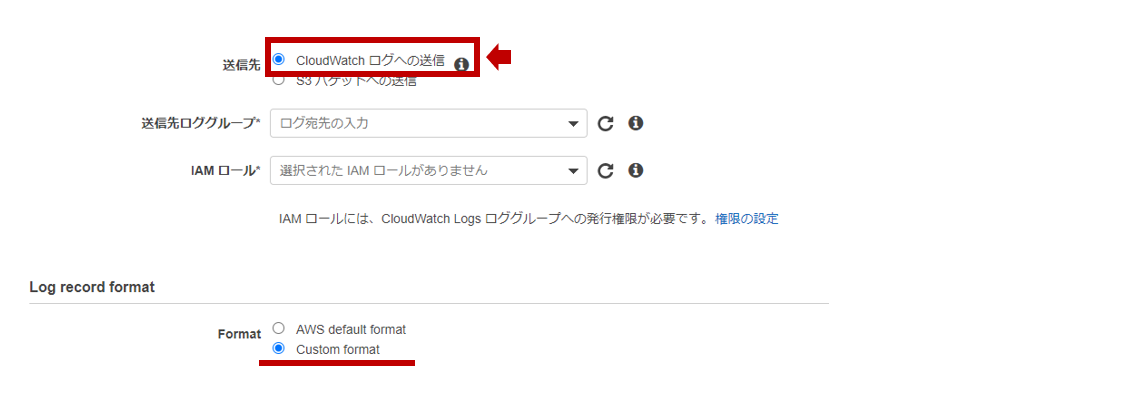
ということで、クラスメソッドさんのDevelopers.IOを検索してみると、GW中にアップデートされていました。
【参考】
・VPCフローログのカスタム形式でCloudwatch Logsがサポートされました
カスタム形式とは
2019年9月までは、**AWS default format(デフォルト形式)**と呼ばれる決まったログフォーマットを採用していました。
<version> <account-id> <interface-id> <srcaddr> <dstaddr> <srcport> <dstport> <protocol> <packets> <bytes> <start> <end> <action> <log-status>
2019年9月に以下の7個のフィールドをカスタム形式のログフォーマットとして、選択式で指定することができるようになりました。
この時点では、送信先にAmazon S3のバケットしか指定することができませんでした。
・vpc-id
・subnet-id
・instance-id
・tcp-flags
・type
・pkt-srcaddr
・pkt-dstaddr
2020年5月には、さらに4個のフィールドが追加され、CloudWatch Logsに対しても送信することができるようになりました。
・region
・az-id
・sublocation-type
・sublocation-id
<account-id> <action> <az-id> <bytes> <dstaddr> <dstport> <end> <instance-id> <interface-id> <log-status> <packets> <pkt-dstaddr> <pkt-srcaddr> <protocol> <region> <srcaddr> <srcport> <start> <sublocation-id> <sublocation-type> <subnet-id> <tcp-flags> <type> <version> <vpc-id>
※公式の日本語ドキュメントは古く、英語に切り替えないと新しい情報が表示されないという罠にやられて見逃しました(´;ω;`)
【参考】
・Amazon VPC フローログにメタデータを追加
・Flow log records(英語サイト)
・フローログレコード(日本語サイト)
CloudWatch Logs Insightでクエリしてみよう
トラブルシューティングで通信フローを見たく、VPCフローログをCloudWatch Logsに入れて
Insightからクエリをしようとしましたが、デフォル形式のログフォーマットでないと
フィールド抽出されないという罠にハマりました。
【カスタム形式の場合】

【デフォルト形式の場合】
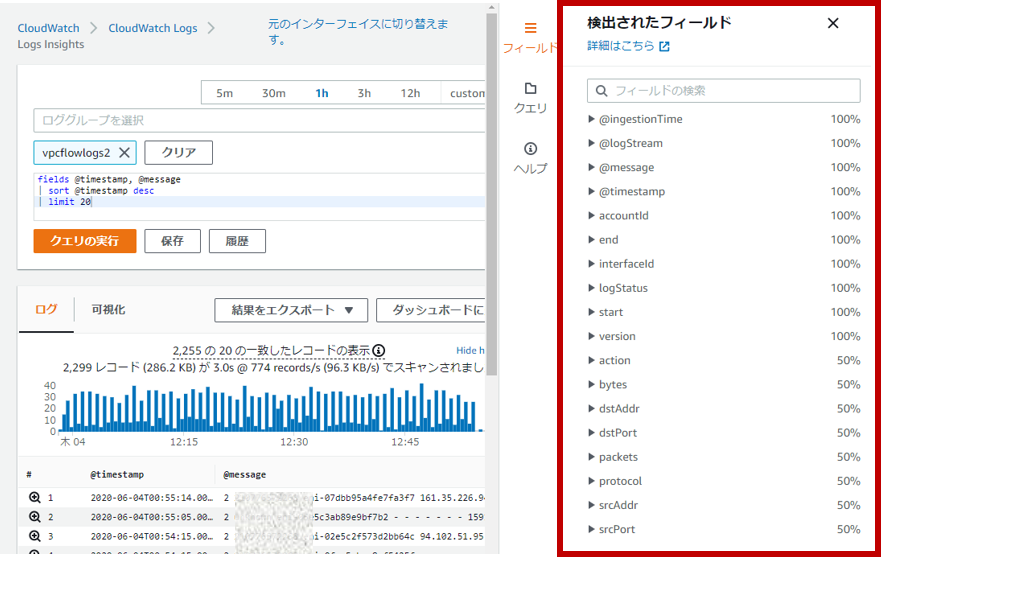
2020年6月時点において、自動検出されるフィールドは下記の参考URLの通りなっています。
ということでparseコマンドを用いて、@messageの内のフィールドをエフェメラルフィールドとして
抽出してクエリに利用することにしました。
【参考】
・サポートされるログと検出されるフィールド
parseコマンドでパースする
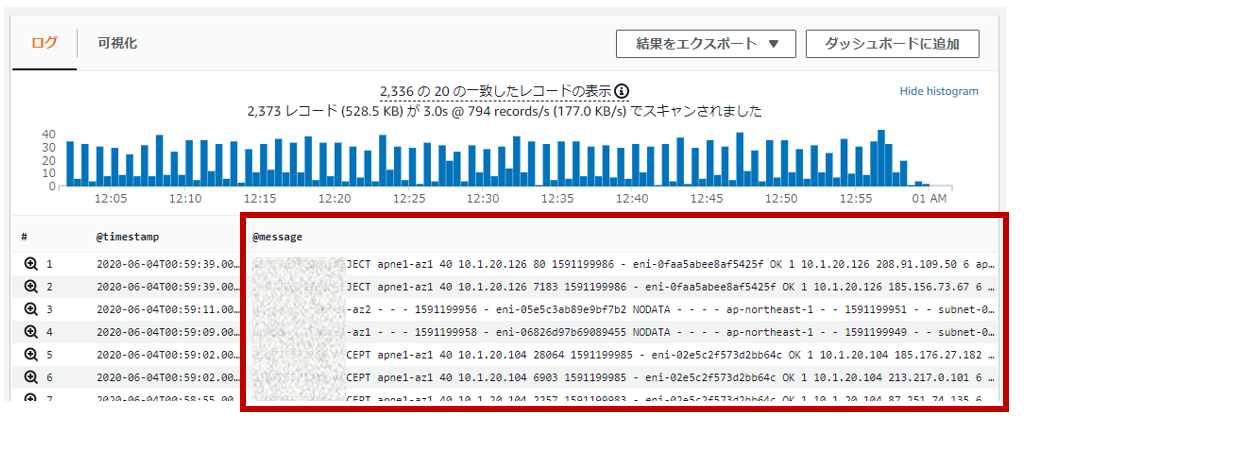
まず、なにも変更せずにデフォルトのままクエリすると@messageにゴリっとログが出力されてしまいます。
fields @timestamp, @message
| sort @timestamp desc
| limit 20
次にparseコマンドでフィールド抽出してみます。
fields @timestamp
| parse '* * * * * * * * * * * * * * * * * * * * * * * * *' as `account-id`, action, `az-id`, bytes, dstaddr, dstport, end, `instance-id`, `interface-id`, logstatus, packets, pktdstaddr, pktsrcaddr, protocol, region, srcaddr, srcport, start, sublocationid, sublocationtype, `subnet-id`, tcpflags, type, version, `vpc-id`
| sort @timestamp desc
parseコマンドは、glob式を使用する方式と正規表現を使用する方式の2通りの記述が可能です。
今回は、前者のglob式でのフィールド抽出を行いました。フィールド数は25個ありますので
*(アスタリスク)を25個、半角スペースを空けて記述し、as以降、フィールド名を指定しています。
※エフェメラルフィールド名に英数字以外が含まれる場合は、`(アクサングラーブ)で囲わないとエラーになります。
いい感じにフィールド抽出されましたね。

これでIPアドレスやポート番号などの抽出されたフィールドを条件にクエリを作成することができます。
以下では、元パケットの送信元IPアドレスが10.1.1.199となっているフローだけを検索することができます。
fields @timestamp
| parse '* * * * * * * * * * * * * * * * * * * * * * * * *' as `account-id`, action, `az-id`, bytes, dstaddr, dstport, end, `instance-id`, `interface-id`, logstatus, packets, pktdstaddr, pktsrcaddr, protocol, region, srcaddr, srcport, start, sublocationid, sublocationtype, `subnet-id`, tcpflags, type, version, `vpc-id`
| filter pktsrcaddr = '10.1.1.199'
| sort @timestamp desc
※filter条件に利用する値は、数値以外は'(シングルクォーテーション)で囲わないとエラーになります。
以下では、宛先IPアドレスに10.1.10.127と10.1.20.126と10.1.30.186、宛先ポート443のHTTPS通信に絞り
元パケットの送信元IPごと(Group By)のフロー数を多い順(desc)で表示することができます。
fields @timestamp
| parse '* * * * * * * * * * * * * * * * * * * * * * * * *' as `account-id`, action, `az-id`, bytes, dstaddr, dstport, end, `instance-id`, `interface-id`, logstatus, packets, pktdstaddr, pktsrcaddr, protocol, region, srcaddr, srcport, start, sublocationid, sublocationtype, `subnet-id`, tcpflags, type, version, `vpc-id`
| filter dstport = '443'
| filter dstaddr in ['10.1.10.127','10.1.20.126','10.1.30.186']
| stats count(*) as FlowCount by pktsrcaddr
| sort pktsrcaddrCount desc
クエリ構文は、以下の公式ドキュメントも参考にしてみてください。
【参考】
・CloudWatch Logs Insights クエリ構文
おまけ (2020/6/10追記)
CloudWatch Logsからサブスクリプションフィルタを使って、「Amazon Elasticsearch Serviceへのストリーム」を行う場合も同じでした。
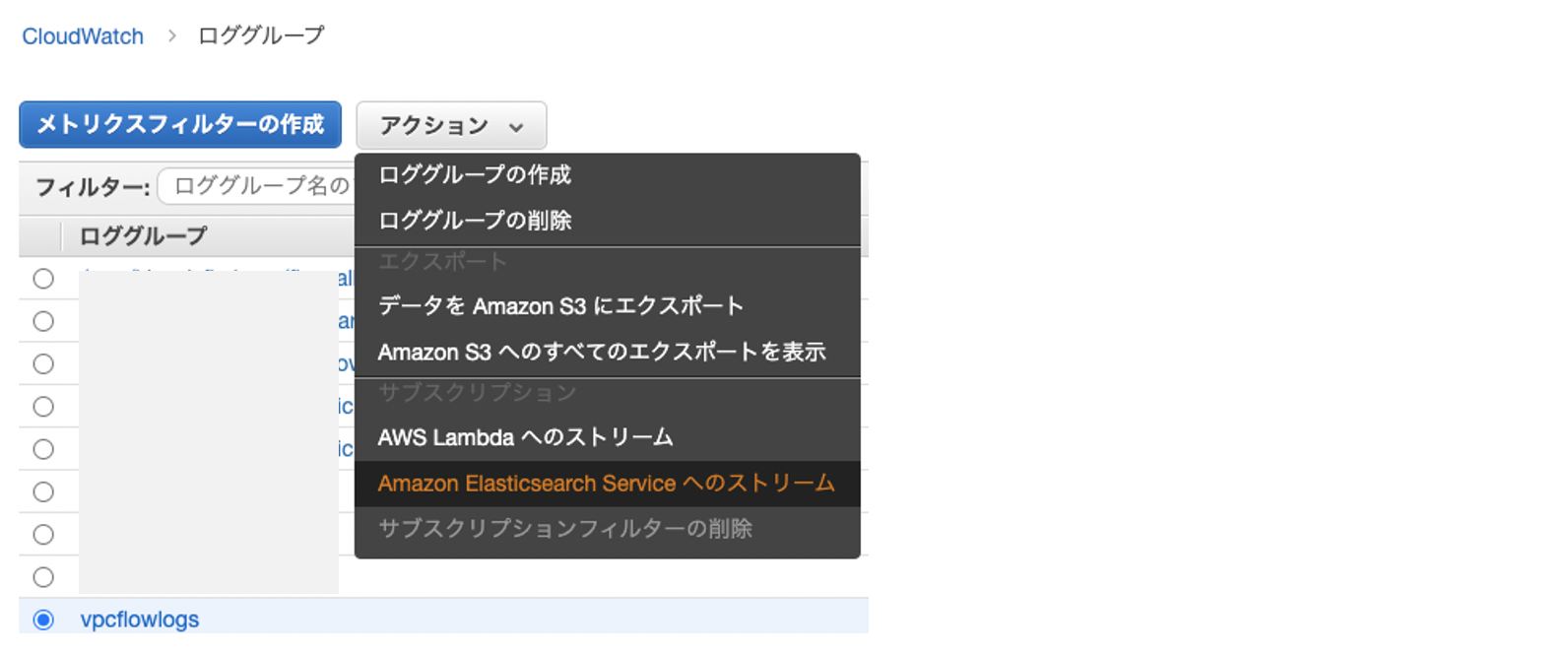
[Amazon VPC フローログ]を選択したときのサブスクリプションフィルターのパターンは、デフォルト形式のままです。
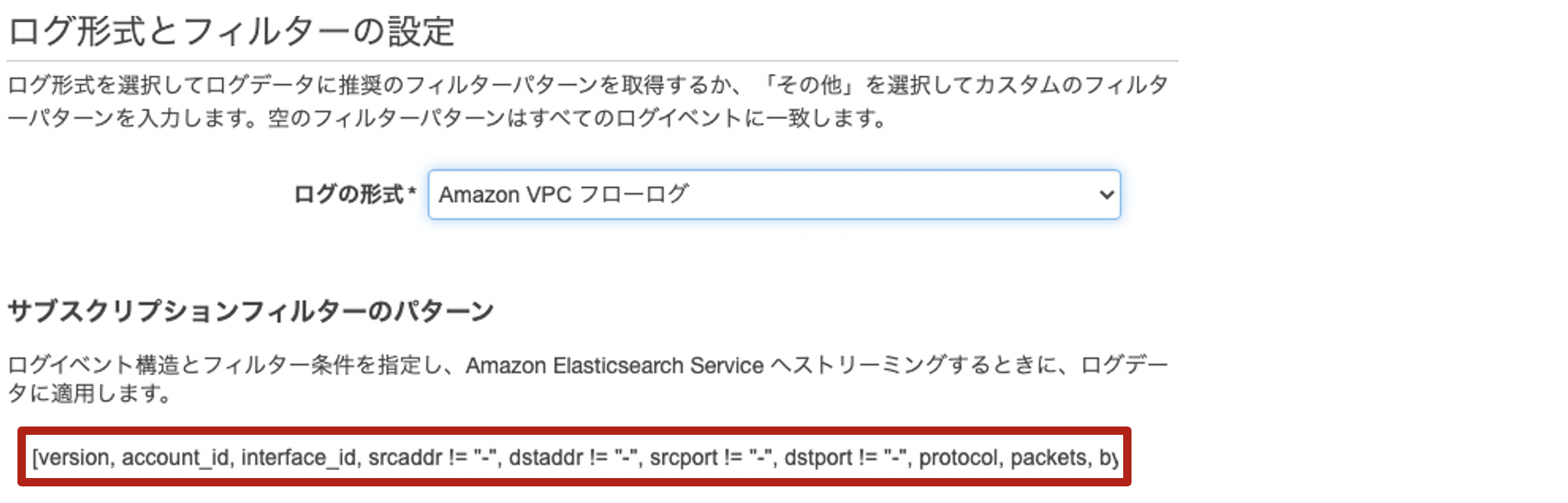
以下のように書き換えてみます。
[account_id, action, az_id, bytes, dstaddr != "-", dstport != "-", end, instance_id, interface_id, logstatus, packets, pktdstaddr != "-", pktsrcaddr != "-", protocol, region, srcaddr != "-", srcport != "-", start, sublocationid, sublocationtype, subnet_id, tcpflags, type, version, vpc_id]
テスト結果もキレイにパースされていますね。

※フィールド名に**ハイフン(-)**が含まれているとパースエラーになってしまうため、**アンダースコア(_)**に置換しています。
【参考】
・フィルターとパターンの構文
まとめ
いかがでしたでしょうか。
そのうち、CloudWatch Logs Insightの機能として、カスタム形式のログフォーマットも
自動検出フィールドでもっと便利にできるようになると思いましたが、小ネタとして記事にしてみました^^