はじめに
Azureで提供されているHortonworks Sandbox上でSparkling Waterをセットアップし、H2O Flow上でDeep LearningによるMNISTのモデル構築をしてみます。
なお、手元の環境は MacBook Air(Mac OS X El Capitan)です。
AzureでのHortonworks Sandboxのセットアップ
まずこちらのkkitaseさんの記事を参考に、AzureでHortonwork Sandboxをセットアップします。
仮想マシンのサイズは小さすぎるとアプリケーションを実行することができませんのでご注意を。今回はDS3_V2でプロビジョニングしました。
仮想マシンの起動が完了したらまずhttp://<sandbox-public-ip>:8888/へアクセスし、必要事項を記入してTerms of Useへの同意にチェックをしてSubmitします。
次に、sshでサーバへアクセスしてAmbariの管理者パスワードを設定します。以下は.ssh/configの設定例です。
Host *.azure
User hssh
UserKnownHostsFile /dev/null
StrictHostKeyChecking no
PasswordAuthentication no
IdentitiesOnly yes
LogLevel ERROR
IdentityFile ~/.ssh/id_rsa
ProxyCommand nohup ssh localhost -W $(echo %h | sed s/\\.azure//):%p
Azureのsandbox環境にログインし、ambari-admin-password-resetコマンドを実行してAmbari管理者のパスワードを設定します。
local$ ssh <sandbox-public-ip>.azure
sandbox$ sudo ambari-admin-password-reset
Please set the password for admin:
Please retype the password for admin:
中略
Waiting for server start....................
Ambari Server 'start' completed successfully.
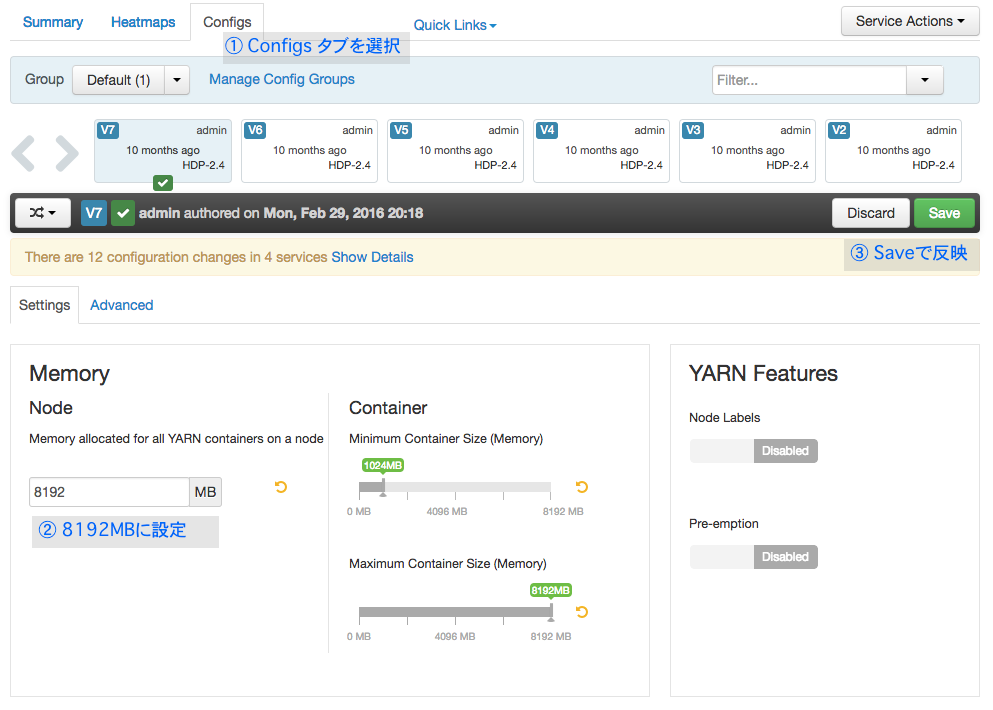
パスワードが設定できたらhttp://52.185.151.244:8080/へアクセスし、adminユーザとして先ほど設定したパスワードでログインします。左のメニューからYARNを選択し、ConfigsタブでNodeに割り当てるメモリ(yarn.nodemanager.resource.memory-mb)を8GBに設定しSaveボタンをクリックして反映します。反映時に依存する設定項目の推奨値が提示されるのでそのままOKをクリックします。
反映後、再起動の必要なサービスのメニュー横にアイコンが表示されるので、各サービスを再起動します。
Sparkling Waterのインストール
Sandbox環境にsshでログインし、wgetでSparkling Waterのzipアーカイブをダウンロード・展開します。
local$ ssh <sandbox-public-ip>.azure
sandbox$ wget http://h2o-release.s3.amazonaws.com/sparkling-water/rel-1.6/8/sparkling-water-1.6.8.zip
sandbox$ unzip sparkling-water-1.6.8.zip
HADOOP_CONFを設定し、spark-submitでSparkling Waterをデプロイします。
sandbox$ export HADOOP_CONF_DIR=/etc/hadoop/conf
sandbox$ spark-submit --class water.SparklingWaterDriver --master yarn-client --num-executors 3 --driver-memory 1g --executor-memory 1g --executor-cores 1 sparkling-water-1.6.8/assembly/build/libs/*.jar
16/12/18 18:51:10 INFO REPLClassServer: Directory to save .class files to = /tmp/spark-c4c1570e-c560-411a-97b5-bb762a880d5b
16/12/18 18:51:11 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
中略
Sparkling Water Context:
* H2O name: sparkling-water-hssh_-1726962807
* cluster size: 3
* list of used nodes:
(executorId, host, port)
------------------------
(2,sandbox.hortonworks.com,54323)
(3,sandbox.hortonworks.com,54321)
(1,sandbox.hortonworks.com,54325)
------------------------
Open H2O Flow in browser: http://<sandbox-local-ip>:<port> (CMD + click in Mac OSX)
これでSparklink Waterが起動し、http://<sandbox-local-ip>:<port>へアクセスすることでブラウザからWeb UIを利用することができるようになりました。なお、起動中に下記のようなエラーが表示された場合は、前述したYARNでのNodeへの割り当てメモリ設定がうまくいっていない可能性があります。
Initial has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient memory
Sparkling Waterのログに出力されたURLはローカルIPになっているため、sshのPortForwardingなどを利用するか、もしくはsshuttleというssh proxyなどを利用してアクセスする必要があります。sshuttleを利用する場合は下記のように実行します。
local$ sshuttle --dns -r <sandbox-public-ip>.azure <sandbox-local-ip>
これで先ほどのspark-submitのログに表示されていたURLhttp://<sandbox-local-ip>:<port>/にアクセスすると、H2O Flowの画面が表示されます。
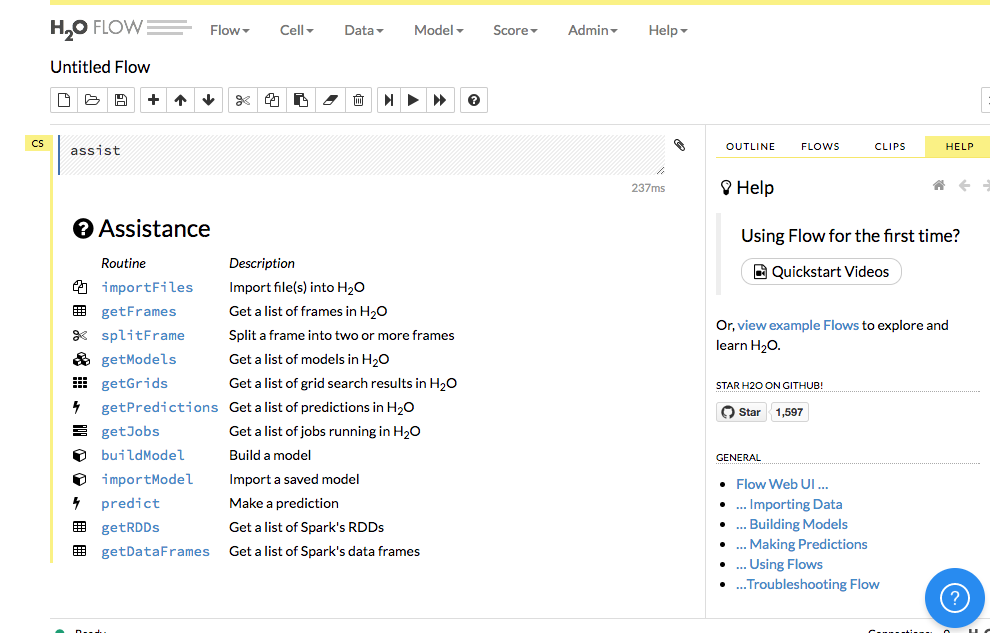
H2O FlowによるMNIST
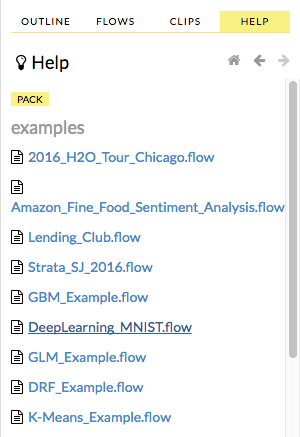
起動したH2O Flowを使ってMNISTのサンプルを実行してみます。Web UIの右カラムにあるview example FlowsをクリックしてDeepLearning_MNIST.flowを選択し、Notebookをロードします。
メニューのRun AllボタンをクリックするとNotebookの内容が一通り実行されます。このあたりの操作はSandboxに含まれるZeppelinとほぼ同様です。

実行が完了すると、Resultsセクション以下に実行結果のグラフ及びメトリクスをまとめた表が出力され、学習したモデルの詳細について確認することができます。
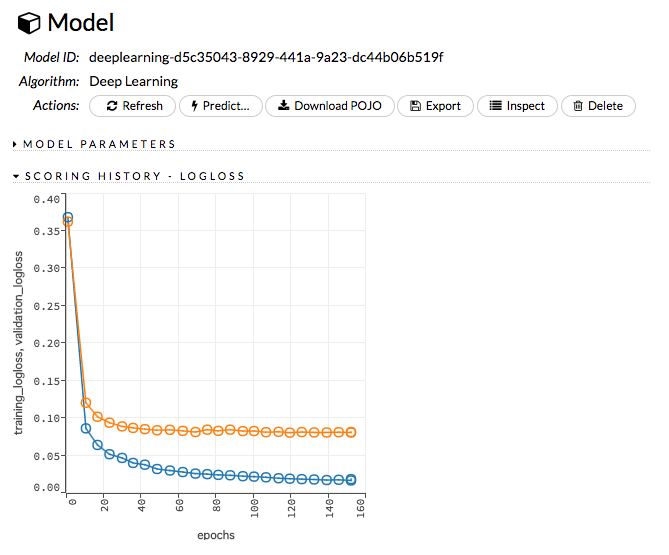
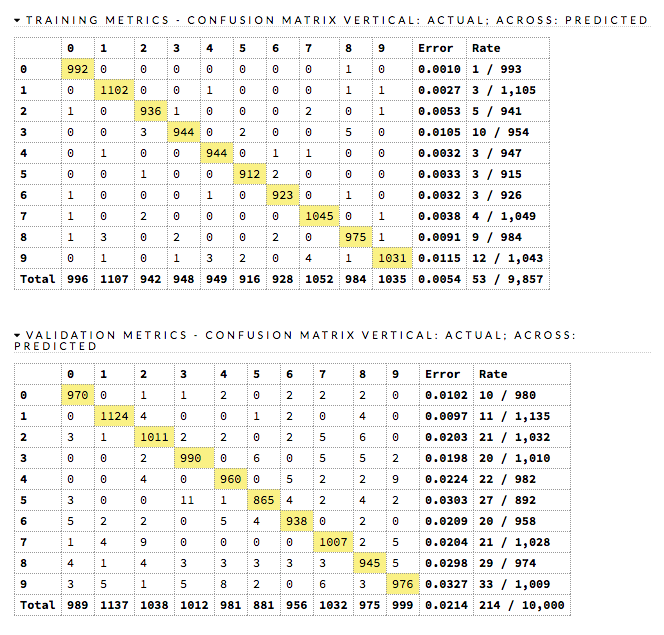
まとめ
Hortonworks Sandbox上にSparkling Waterをセットアップし、Web UI上からMNISTのサンプルを実行できるところまでを確認しました。Sparkで利用できるDeep Learning Frameworkとしては、他にもCaffe on SparkやTensorflow on Spark、DeepLearning4Jなどがありますが、最もセットアップの敷居が低く、開発も継続的に進められているのがこのSparkling Waterという印象でした。