はじめに
いつも後輩から質問をされた場合は、面倒くさいので先人が丁寧な説明の記事を書いているので、いい感じのQiitaの記事とかを探して渡している。しかし、データベースのインデックスのはなしに関しては意外と上手く説明されている記事が無かったため、仕方がなく自分で書くことにした。
インデックスとは
インデックスとは探索木とかを使ってデータの取得を効率化しているやつのことである。
例えば以下のようなテーブル「player」があるとする。
| name(名前) | age(年齢) | height(身長) | birthday(誕生日) |
|---|---|---|---|
| Kurl | 31 | 193 | 1988-04-03 |
| Santon | 29 | 187 | 1991-01-02 |
| Taylor | 34 | 186 | 1986-01-23 |
| Tiote | 34 | 180 | 1986-06-21 |
| Anita | 30 | 168 | 1989-04-04 |
| Cabaye | 34 | 175 | 1986-01-14 |
| Obertan | 31 | 185 | 1989-02-06 |
ここで以下のような身長が180の選手を取得するSQLを流したとする。
SELECT name FROM player WHERE height = 180;
インデックスが無い場合は全てのレコード、ここでは7つのレコードを順番に参照してheightが180のものを探してくることになる。1つのレコードを参照してheightを比較するのに1秒かかるとすると、全部で7秒かかることになる。この方式の場合、例えばレコードが1023個あった場合は1023レコードを参照する必要があり1023秒かかり、n個あった場合はnレコードを参照するのでn秒かかる計算になる。
ここで、以下のような木を用意する。すべてのノードに対して、子が存在するとき、左の子は自ノードより値が小さく、右の子は値が大きいといった感じのものだ。
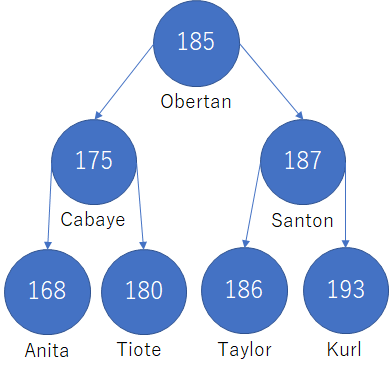
ここの木を次のような使いかたをする。ノード(初回は根)の値を参照して、対象の場合は探索完了。対象の値が参照したノードより小さい場合は左のノード、大きい場合は右を参照する。実際に「height=180」を探索する場合は以下のようになる
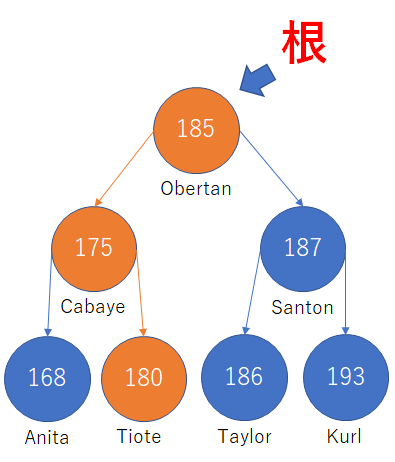
- 根の値は185で、探索している値の180は小さいので左のCabayeへ
- Cabayeの値は175で、探索している値の180は大きいので右のTioteへ
- Tioteの値は探索していた180なので終了
この方法だとどの値でも最大3回(木の深さ)の操作でレコードを取得することができ、1操作を1秒とすると3秒となる。この方法の場合だと1023レコードの場合は10秒、nレコードの場合は$log_2n$でレコードを取得することが出来る。以下のように、全探索とインデックスを利用した場合を比較すると、レコードが増えれば増えるほどインデックスを利用したほうが嬉しいことがわかる。
| レコード数(個) | 全探索 | インデックス |
|---|---|---|
| 1 | 1秒 | 1秒 |
| 3 | 3秒 | 2秒 |
| 7 | 7秒 | 3秒 |
| ︙ | ︙ | ︙ |
| $2^{10}-1=1023$ | 1023秒=約17分 | 10秒 |
| $2^{20}-1=1048575$ | 1048575秒=約291時間 | 20秒 |
| $2^{30}-1=1073741823$ | 1073741823秒=約12427日 | 30秒 |
複合インデックス
更にインデックスは複数のカラムを対象にして作成することが出来る。たとえば(age,height)でインデックスを作成した場合は以下のように、age,heightの順に優先して値の大小を決めた木になる。まずはageで大小を決めて、ageが同じならheightで大小を決めるといった感じだ。
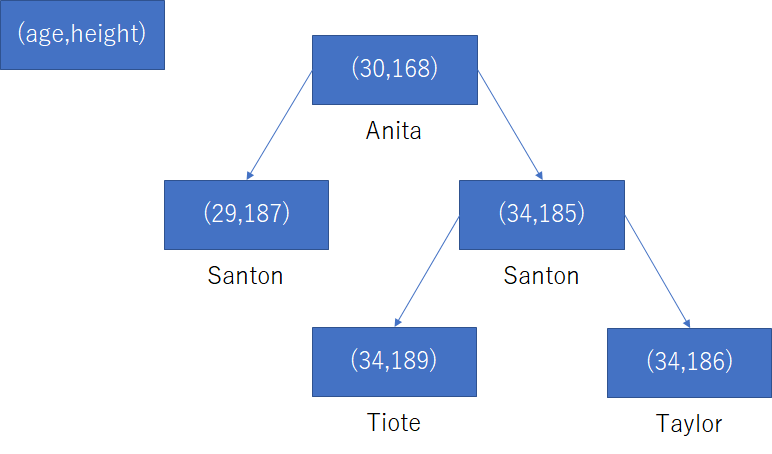
このような複合インデックスは例えば「age=34 AND height=180」といったレコードを探すときに有効で、まずは「age=34」で探索をした後に
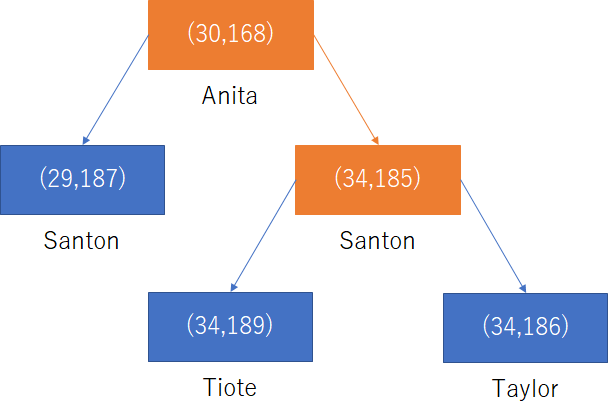
「height=180」を探すといった感じになる。
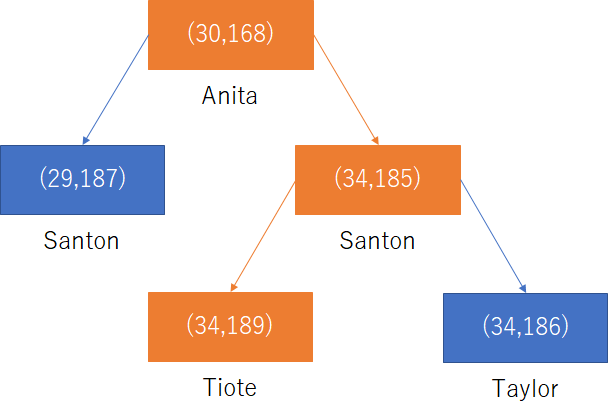
複合インデックスはどのカラムが上位かが重要である。上記のインデックスの場合、たとえば「height=180」だけといった探索は、上位のageが優先でノードが並んでいるためするころができない。しかし「age=34」みたいな探索はすることができる。一般化すると、(A,B,C,D…)の順番のインデックスがある場合に、インデックスを使うことが出来るカラムの指定はA,AB,ABC,ABCD,…といった上位から順番にカラムを指定した感じで、一方それ以外のB,CとかBDといった使い方はできない。
その他
主キーには必ずインデックスができる
主キーには必ずインデックスができるよ。
全部のカラムに対してインデックスを作成すれば最強じゃん
インデックスに使われているカラムに対しての更新、レコードの追加・削除があるたびにインデックスも更新をしなくてはいけないので、それらの処理が重くなるデメリットがある。あとインデックス自体もデータなので容量を食うことも忘れずに。
数値は比較できるからインデックスを作成できるけど、文字列の場合はできないの?
文字列に対しては辞書列順などの順序を入れることが出来る。辞書に先に乗っている単語を小さいとみなす感じ。たとえば「Cabaye<Tiote」がなりたつ。日付などでも、昔のほうが小さいといった感じで比較がされている。
インデックスを使っているつもりなのに早くならないよ。
だいたい以下が原因とかで、インデックスが使えていない。
LIKEは前方一致で
文字列の部分一致で使うLIKEだが、文字列の比較に使われている辞書順は文字列の文字を先頭から順に比較するため、前方一致ではインデックスが使われるが、それ以外の場合はインデックスが使われない。
条件にORを使っている
DBがSQLを解釈してデータの取得方法を考えるときに、インデックスを使うより全探索をしたほうが早いと思ったらインデックスを使わないことがある。たとえば前に使った以下の例で「身長が168 OR 180 OR 186」の選手を探すことになったとする。
この場合に実装方法にもよるが、毎回根から対象を探そうとしたのなら9回の操作が必要になり、全探索より遅くなってしまう。そんなこんなで、条件にORを使うとDBが気を使ってあえてインデックスを使わないことがある。しかし、インデックスを使ったほうが早いと思うのなら、使っているDBのSQLにインデックスを使うことを促す文法(Oracleのヒント句とか)が用意されていればそれを用いてみたり、UNIONをつかうとインデックスを使ってくれたりする。
インデックス対象のカラムに対して関数を使っている
前述のテーブルplayerので「身長が180cm台」の選手を探したいとする。この時に整数に切り下げる関数FLOORを用いて「FLOOR(height/10)=18」といった条件で探索をするとする。このようにインデックスに使われているカラムを関数に入れてしまった場合にDBは上手く気を使ってインデックスを使ってくれたりはしない。この場合は「height>=180 AND height<190」といったようにカラムを関数に入れないような書き方を心がけよう。
暗黙の型変換を使っている
暗黙の型変換を使った場合もインデックスを使ってくれないことがある。以下のように日付型のカラムと文字列の比較をしたときに、DBが気を利かせてくれて文字列をいい感じに日付として扱ってくれたりするように、DBが優しさで良い感じに型変換を行ってくれるやつである。
SELECT * FROM player WHERE birthday = '1986-06-21';
なので、インデックスのカラムを条件に入れるときはちゃんと型変換をした形(ORACLEならTO_DATE関数など)で指定をしよう。
そもそも、暗黙の型変換はSQLを実行する環境の設定に依存してしまうため、SQLを実行する環境次第で結果が変わってしまうことがある。そのため、インデックスどうこう以前に、バグを引き起こしやすいので開発の際は使うのはやめよう。例えば日付1988年4月3日を、設定がイギリスの場合で文字列で暗黙の型変換を使おうとすると、dd-mm-yyyy形式とかになっていたりして'03-04-1988'となる。しかしながら、設定がアメリカとなってしまっていた場合はmm-dd-yyyy形式だったりして1988年3月4日と解釈されてしまったり、日本でyyyy-mm-dd形式だったりして「そんな日付ねーよ!」と怒られてしまったりする。(実際にこの暗黙の型変換とExceptionの握り潰しという2つの悲しみがあわさった悲しみを見たことがある)
まとめ
・インデックスとは探索木とかを使ってデータの取得を効率化しているやつのこと
・インデックスにはカラムの順番があるからちゃんと守ろう
・主キーには自動的にインデックスができる
・LIKEを使うときは前方一致で
・インデックスを使うときはORは慎重に、関数、暗黙の型変換は使っちゃだめだよ(そもそも暗黙の型変換はつかうな)