はじめに
最近よく聞くようになったVector Databaseとは何かというのが気になったため、実際に検証します。
今回はVector DatabaseとしてPostgresのpgvectorを採用します。Postgresを使い慣れていることと、単純にVector Databaseを利用してみたいだけだからです。
Vector Databaseとは
AIの補佐として利用するデータベースです。主に、Hallucinationを防ぐためや、ChatGPTなどのLLMが知らない情報を補完するために利用します。
検証準備
前提
wslでUbuntu環境が作成済み
lsb_release -a
No LSB modules are available.
Distributor ID: Ubuntu
Description: Ubuntu 24.04.1 LTS
Release: 24.04
Codename: noble
全体像
今回は以下の環境で検証します。
wslでubuntuを作成してDocker上にPostgresを作ります。
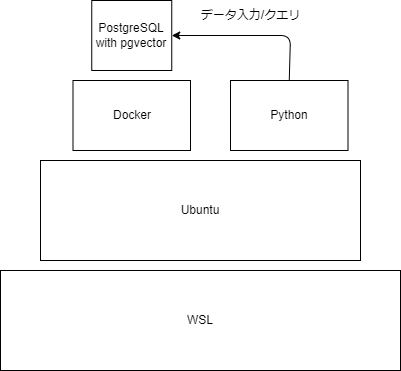
環境構築
sudo apt install docker.io
ユーザをdocker groupに割り当てて、今回検証するためのpostgres imageを取得
sudo usermod -aG docker <dockerを起動するユーザ>
sudo chown :docker /usr/bin/docker
# need to refresh the docker group
newgrp docker
# pull the docker image
docker pull pgvector/pgvector:pg17
docker上でpostgresを起動
- POSTGRES_PASSWORD: 任意
- POSTGRES_DB: 任意。Postgres内のデータベース名
docker run -d --name pgvector_test -p 127.0.0.1:5432:5432 \
-e POSTGRES_PASSWORD=secret0001 \
-e POSTGRES_DB=vector_db \
pgvector/pgvector:pg17
※まだpsqlをインストールしていない場合、以下を実行してpsql version 17をインストール
sudo sh -c 'echo "deb http://apt.postgresql.org/pub/repos/apt $(lsb_release -cs)-pgdg main" > /etc/apt/sources.list.d/pgdg.list'
wget --quiet -O - https://www.postgresql.org/media/keys/ACCC4CF8.asc | sudo apt-key add -
sudo apt update
sudo apt install postgresql-client-17
postgresに接続して確認します。
vectorを扱うためのextensionは有効になっていなかったため、有効にします。
また、文章を保存するためのテーブルを作成します。元の文章を保存しておくことで、後ほどコサイン距離(cosine distance)を計算したときに特定できるようにしています。
psql -h 127.0.0.1 -p 5432 -U postgres -d vector_db
# create an extension
vector_db=# CREATE EXTENSION IF NOT EXISTS vector;
CREATE EXTENSION
vector_db=# \dx
List of installed extensions
Name | Version | Schema | Description
---------+---------+------------+------------------------------------------------------
plpgsql | 1.0 | pg_catalog | PL/pgSQL procedural language
vector | 0.8.0 | public | vector data type and ivfflat and hnsw access methods
(2 rows)
### create a table
### id:
### sentence: an original sentence
### embedding: an embedded sentence
CREATE TABLE embeddings (
id SERIAL PRIMARY KEY,
sentence TEXT,
embedding VECTOR(384)
);
検証
psqlで直接データを入力する方法でも可能ではありますが、vectorを利用する関係でコマンドが大変なことになるため、今回はPythonを使います。
①postgresにpythonからアクセスするためのライブラリ、②embeddingを実施する際にall-MiniLM-L6-v2を利用するために、事前にpipコマンドでインストールします。
# ①
pip install psycopg2-binary
# ②
pip install sentence-transformers
それではpythonでデータをデータベースに入力するプログラムとデータをクエリするプログラムを作成します。
データ入力用
from sentence_transformers import SentenceTransformer
import psycopg2
# Load sentences
with open("sentences.txt", "r") as file:
test_sentences = [line.strip() for line in file.readlines()]
# Load the sentence-transformer model
model = SentenceTransformer('all-MiniLM-L6-v2')
conn = psycopg2.connect(
host="localhost",
port=5432,
database="vector_db",
user="postgres",
password="secret0001"
)
cursor = conn.cursor()
for sentence in test_sentences:
# Vectorize a sentence
vector = model.encode(sentence).tolist()
# Insert the original sentence and its embedding into the table you created earlier.
cursor.execute("INSERT INTO embeddings (sentence, embedding) VALUES (%s, %s)", (sentence, vector))
conn.commit()
cursor.close()
conn.close()
データクエリ用
クエリの際にcosine distanceを利用しているのはテキスト検索にはこれが良いことが多いと聞いたからです。他にも利用できる演算は参考の「Ultimate Guide To Text Similarity With Python」を参考にしてください。
from sentence_transformers import SentenceTransformer
import psycopg2
model = SentenceTransformer('all-MiniLM-L6-v2')
conn = psycopg2.connect(
host="localhost",
port=5432,
database="vector_db",
user="postgres",
password="secret0001"
)
cursor = conn.cursor()
# Read a sentence from your console
query_sentence = input("Enter a sentence: ")
query_vector = model.encode(query_sentence).tolist()
# Find a similar sentence
cursor.execute(f"""
SELECT id, sentence, embedding <=> '{query_vector}'::vector AS cosine_distance
FROM embeddings
ORDER BY cosine_distance
LIMIT 3;
""")
results = cursor.fetchall()
# Display the results
print("Top 3 similar sentences by cosine distance:")
for row in results:
print("ID:", row[0], "Sentence:", row[1], "Distance:", row[2])
cursor.close()
conn.close()
データベース入力用の文章です。ChatGPTに出力してもらいました。(20個)
A playful puppy runs through the green meadow.
Birds chirp softly as the sun rises over the forest.
The gentle breeze rustles the leaves of the tall oak tree.
A small rabbit hops quickly across the garden.
Language models learn to understand human speech.
Embedding vectors are useful for text classification tasks.
Machine learning transforms raw data into actionable insights.
Neural networks capture complex patterns in data.
The old, rusty car sat abandoned on the side of the road.
A sleek, modern laptop shines on the office desk.
The vibrant red apples look fresh and delicious.
Soft, white clouds float lazily in the clear blue sky.
She swiftly types on her keyboard, completing her assignment.
He jogs along the beach as the waves crash nearby.
The chef expertly chops vegetables for the salad.
They gathered around the campfire, sharing stories under the stars.
He sips his coffee slowly, savoring each warm drop.
She reads a fascinating novel under a cozy blanket.
The children laugh and play at the nearby park.
A cyclist pedals quickly through the busy city streets.
実行します。
# insert data
python vector-insert-data.py
# check data in the embeddings table.
vector_db=# select count(*) from embeddings;
count
-------
20
(1 row)
# query
python vector-query-data.py
Enter a sentence: my dog is so cute.
Top 3 similar sentences by cosine distance:
ID: 1 Sentence: A playful puppy runs through the green meadow. Distance: 0.6745794415473938
ID: 18 Sentence: She reads a fascinating novel under a cozy blanket. Distance: 0.7616130709648132
ID: 2 Sentence: Birds chirp softly as the sun rises over the forest. Distance: 0.7647473592980908
ちゃんとワンちゃんに関する文章が一番近い値になりましたね! 今回は近い文章を表示しているだけですが、この元の文章をLLMに渡してあげることで確度の高い回答が出てくるのだと思います。
おまけ
ivfflatというindexを作成してからプログラムを再度実行してみました。vector databaseでのindexは高速になる代わりに正確な結果が返るとはかぎらない(approximate nearest neighbor search)ようになっているみたいです。
私の認識だとcosine distanceの計算がクエリごとに変わるものだと思っていたのですが、実行結果が同じでした。これはあっているのでしょうか。。
# create an index
CREATE INDEX ON embeddings USING ivfflat (embedding vector_cosine_ops) WITH (lists = 100);
NOTICE: ivfflat index created with little data
DETAIL: This will cause low recall.
HINT: Drop the index until the table has more data.
CREATE INDEX
# execute the program again
python vector-query-data.py
Enter a sentence: my dog is so cute.
Top 3 similar sentences by cosine distance:
ID: 1 Sentence: A playful puppy runs through the green meadow. Distance: 0.6745794415473938
ID: 18 Sentence: She reads a fascinating novel under a cozy blanket. Distance: 0.7616130709648132
ID: 2 Sentence: Birds chirp softly as the sun rises over the forest. Distance: 0.7647473592980908
おわりに
今回はpostgresのpgvectorを使ってvector databaseを検証してみました。新しい技術ということもありハードルが高かったですが、postgresを利用できたことで少しハードル下がった気がします。
今回の検証ではpostgresを利用しましたが、パフォーマンスをスケールする際に難があるために大規模なデータベースには利用しづらいとのことでした。社内のchatbotを拡張するぐらいの規模間であればpgvectorを検討できそうだなとは思いました。
以上です。最後まで読んでいただきありがとうございます!
参考
- pgvector GitHub
- Ultimate Guide To Text Similarity With Python
- 今回のembeddingに利用したモデル