自己紹介
30代後半のエンジニア(?)で、妻と子供3人に囲まれ、ドタバタな毎日を送っています。
仕事は、某製造業に勤めていて、いままでルールベースの画像処理を使ってソフトを作ることはあっても、機械学習は全く扱ったことがありませんでした。この度、機械学習(特に画像認識)を扱う部署に異動し、右も左も分からない状態だったため、自己啓発としてAidemyのAIアプリ開発コース(6ヶ月コース)を受講し、その成果物としてパンの種類識別器を制作したので、実施した内容を以下に示します。
ちなみに、7/11から受講を開始して、現在8/16です。1ヶ月ちょっとでここまで来ました。
多少のプログラミングのスキルはあったものの、ちょっと飛ばし過ぎましたかね?復習が足りないのかな?
このコースが終わっても、別のコースを受け放題とのことなので、学習は引き続きやっていこうと思っています。
仕事でも徐々に機械学習コードを読む機会が増えてきて、コードを読んだ際に、講座で勉強したことが出てくることもあり、この講座を受けている効果が現れていると実感しています。
正直、まだ損失関数の種類や最適化を理解できていないので、これからその辺は更に勉強していこうと思っています。
取り敢えず、現段階ではアプリに画像を入力して結果を出すということを目標にし、次に理解できていない部分を深掘りしたいと思っています。
完成した成果物
https://bread-recognition.herokuapp.com/
味気は全然ないです。画像をインプットして処理させて結果表示して終わりです。
なぜパンの種類識別器?
- 仕事で扱う内容が画像認識であるため、画像に関するテーマにしたかった。
- 妻と一緒にパン屋・ケーキ屋をすることが将来の夢であり、それに関連させたテーマにしたかった。
- 画像データが比較的簡単に集められる。
といったことが挙げられます。
画像データの準備
機械学習を行う上で、学習用の画像と、精度検証用の画像を取得する必要があるため、その収集方法を記します。
なお、今回の成果物では、下記のパンの種類を識別できるようにしました。
- バゲット(いわゆるフランスパン)
- カンパーニュ
- クロワッサン
- フォカッチャ
- エピ
- カレーパン
- 食パン
パンの種類を何にするかは、それなりに迷いました。
これらは各々のパンの特徴がわかりやすそうということと、機械学習初心者としてはこれが分離できればよいかと思って選びました。
画像データの収集(icrawler)
チュータの方から、icrawlerというpythonのライブラリを使うと良いとのことだったので、それを使ってやってみました。
コードは下記のような感じで、WEBページを参照して作りました。
import base64
from icrawler import ImageDownloader
from six.moves.urllib.parse import urlparse
from icrawler.builtin import BingImageCrawler
from icrawler.builtin import GoogleImageCrawler
import argparse, os
parser = argparse.ArgumentParser(description='img_collection')
parser.add_argument('--output_dir', default="",type=str, help='')
parser.add_argument('--N', default=10, type=int, help='')
parser.add_argument('--engine', choices=["bing","google"], default="bing", type=str, help='')
args = parser.parse_args()
class Base64NameDownloader(ImageDownloader):
def get_filename(self, task, default_ext):
url_path = urlparse(task['file_url'])[2]
if '.' in url_path:
extension = url_path.split('.')[-1]
if extension.lower() not in [
'jpg', 'jpeg', 'png', 'bmp', 'tiff', 'gif', 'ppm', 'pgm'
]:
extension = default_ext
else:
extension = default_ext
# works for python 3
filename = base64.b64encode(url_path.encode()).decode()
return '{}.{}'.format(filename, extension)
def get_crawler(args, dir_name):
if args.engine == "bing":
crawler = BingImageCrawler(
feeder_threads=1,
parser_threads=1,
downloader_threads=4,
storage={'root_dir': dir_name })
elif args.engine == "google":
crawler = GoogleImageCrawler(
feeder_threads=1,
parser_threads=1,
downloader_threads=4,
storage={'root_dir': dir_name })
return crawler
if __name__=="__main__":
# read ini file.
with open('./setting.txt', mode='r', encoding = "utf_8") as f:
read_data = list(f)
print("SELECTED ENGINE : "+args.engine)
for i in range(len(read_data)):
print("SEARCH WORD : "+read_data[i].replace('\n', ''))
print("NUM IMAGES : "+str(args.N))
dir_name = os.path.join(args.output_dir, read_data[i].replace('\n', '').replace(' ', '_'))
#init crawler
crawler = get_crawler(args, dir_name)
crawler.crawl(keyword=read_data[i], max_num=args.N)
検索エンジンを複合的に使って、画像をもっとたくさん集めたいと思いました。しかし、画像の被りを防止するために、同じ画像を保存しないような仕組みを作りが必要で、これを実践するにはicrawlerの内部を修正しなければならないため、今回は諦めました。
画像データの取捨選択
画像を目視で確認しながら、以下のような画像を除外しました。
- 画像内に文字が表示されているもの
-> 文字のコントラストが高く、ノイズになりそうだから - 目当てのパンがメインではないもの(人が大きく写っている画像内にパンがあるとか)
-> 当たり前ですね - 目当てのパンがパッケージに入っているもの
-> パンそのものを識別したいのであって、パッケージを識別したいわけではないから - 目当てのパン以外のパンが同じ画像内に写っているもの
-> どのパンを識別したいのかがわからなくなるから
画像枚数
結果的に、各種類のパンの画像枚数は下記の通りとなりました。
| パンの種類 | 画像枚数 |
|---|---|
| バゲット | 122 |
| カンパーニュ | 139 |
| クロワッサン | 171 |
| フォカッチャ | 112 |
| エピ | 155 |
| カレーパン | 112 |
| 食パン | 97 |
学習
Google Colaboratoryを利用しました。実際のコードは下記にあります。
https://colab.research.google.com/drive/1uCTtfDkBOIm9i6uyj7YQh1kvcAQrgFMK?usp=sharing
画像データの水増し
集めた画像データだけでは不足していると考え、画像データを水増しすることにしました。
Aidemoyの講座ではデータクレンジングで扱われており、これを参考にしました。
import numpy as np
import cv2
def scratch_image(img, flip_lr=True, flip_tb=True, blur=True):
# 水増しの手法を配列にまとめる
methods = [flip_lr, flip_tb, blur]
# 画像のサイズを習得、収縮処理に使うフィルターの作成
img_size = img.shape
erode_kernel = np.ones((3, 3))
# オリジナルの画像データを配列に格納
images = [img]
scratch = np.array([
#左右反転
lambda x: cv2.flip(x, 1),
#上下反転
lambda x: cv2.flip(x, 0),
#ぼかし
lambda x: cv2.GaussianBlur(x, (5, 5), 0),
])
# 関数と画像を引数に、加工した画像を元と合わせて水増しする関数
doubling_images = lambda f, imag: (imag + [f(i) for i in imag])
# doubling_imagesを用いてmethodsがTrueの関数で画像データ(images)を水増し
for func in scratch[methods]:
images = doubling_images(func, images)
return images
講座の中では他にも水増しのための画像処理が行われていましたが、今回のユースケースで必要そうな、左右反転・上下反転・ガウシアンフィルタの画像を水増しデータとしました。
入力画像の前処理
入力画像のサイズは決まったサイズでなければならないという縛りはあるものの、検索エンジンから取得した画像のサイズはまちまちであったため、どのように画像のサイズを変更するかを考えました。
下記 preProcess関数が、前処理の関数です。
import math
def preProcess(img_path, height, width):
img = cv2.imread(img_path)
# 縦横の大きさを見て横向きの画像にする(90°回転)
size = img.shape
if size[0] > size[1]:
img = cv2.rotate(img, cv2.ROTATE_90_CLOCKWISE)
o_h, o_w = img.shape[:2]
if img.shape[2] != 3:
print(img_path)
print("image type failure")
return None, None
output_scale = min([height / o_h, width / o_w, 1])
dst_size = (math.floor(o_h * output_scale), math.floor(o_w * output_scale))
img_comp = cv2.resize(img, tuple(reversed(dst_size)))
pad_y = height - dst_size[0]
pad_x = width - dst_size[1]
output1 = cv2.copyMakeBorder(img_comp, 0, pad_y, 0, pad_x, cv2.BORDER_CONSTANT, (0, 0, 0))
output2 = cv2.copyMakeBorder(img_comp, pad_y, 0, pad_x, 0, cv2.BORDER_CONSTANT, (0, 0, 0))
return output1, output2
引数height/widthが入力した画像に対する出力画像のサイズとなるのですが、画像の高さと幅を安直にリサイズするとアスペクト比が崩れてしまい、特徴をうまく取り出せないと考え、アスペクト比はそのままにして、足りない部分はゼロパディングすることにしました。
また、戻り値を2つ用意していますが、これはパディングする場所違いで2つの画像データを戻り値とするためのものです。
例えば、高さ方向にパディングが必要となったとき、画像下部にパディングされた画像と、画像上部にパディングされた画像の2種類を戻すといったものです。
画像データの準備
icrawlerで集めた画像をGoogleドライブに保存し、保存した画像と上記の前処理関数と水増し関数を使って、学習に使う画像データをメモリ上に準備しました。
icrawlerで準備した画像は、パンの種類毎にフォルダに分割し、そのフォルダの先頭に番号を下記のように付与しました。
images
├── 1_Baguette
├── 2_Campagne
├── ...
以下省略
Google ColaboratoryからGoogleドライブ上のデータを参照するには、スクリプトでGoogleドライブをマウントする必要があり、これには下記を実行する必要があります。
from google.colab import drive
drive.mount('/content/drive')
ちなみに、一定時間ノートを触らないと、セッションが切れてしまい、変数が初期化されてしまい、更にマウントも最初からやり直しとなります。
このあたりは無料で使っているから致し方なしですね。
画像データとラベルデータは下記を実行することによりメモリ上に準備しました。
import glob
import os
img_dir = "/content/drive/MyDrive/Colab Notebooks/Aidemy/images/"
# 画像データフォルダの取得
dirs = os.listdir(img_dir)
X = []
y = []
# ディレクトリ分ループ(パンの種類分)
for dir in dirs:
name = dir.split('_')
# 画像ファイルを取得
files = glob.glob(img_dir + dir + "/*")
# 画像ファイル分ループ
for file in files:
# 前処理を実施して画像サイズを256x256にする
img1, img2 = preProcess(file, 256, 256)
# 画像の水増し
img1_scratch = scratch_image(img1)
X = X + img1_scratch
img2_scratch = scratch_image(img2)
X = X + img2_scratch
# ラベル付
for i in range(len(img1_scratch)):
y_tmp = [0, 0, 0, 0, 0, 0, 0]
y_tmp[int(name[0])-1] = 1
y.append(y_tmp)
for i in range(len(img2_scratch)):
y_tmp = [0, 0, 0, 0, 0, 0, 0]
y_tmp[int(name[0])-1] = 1
y.append(y_tmp)
フォルダの先頭番号をラベルとしているので、フォルダの先頭番号を利用してone hot vectorを画像データと対にして作成しました。
結果的に、14,528個のデータを準備できました。
ちなみに、この検討を行った初期段階では、もっと多くの種類で水増ししましたが(約50,000個)、学習時にメモリーが足りなくなってしまったためか、コードの実行中にクラッシュが発生してしまいました。
型変換と学習データとテストデータに分割
X, yは、list型であるため、これをnumpy.ndarray型に変換し、学習用データと評価用データで分割しました。
なお、学習用データと評価用データの比は8:2として、乱数の種を42としてランダムに分割しました。
# データをnp.darray型にキャスト
X = np.array(X)
y = np.array(y)
# データをランダムに並べ替え
np.random.seed(42)
rand_index = np.random.permutation(np.arange(len(X)))
X = X[rand_index]
y = y[rand_index]
# データの分割(8割をトレーニング画像とする)
X_train = X[:int(len(X)*0.8)]
y_train = y[:int(len(y)*0.8)]
X_test = X[int(len(X)*0.8):]
y_test = y[int(len(y)*0.8):]
これにより、データの準備は終わりです。
モデル作成と学習
今回は、VGG16モデルをベースとする転移学習を用いました。
世の中には親切な人がいっぱいいるものだと感心して使いました。
入力層は256x256x3とし、出力層は7で活性化関数にsoftmax関数を用いることで、スコア値に変換するようにしました。
from tensorflow.keras.layers import Dense, Dropout, Flatten, Input
from tensorflow.keras.applications.vgg16 import VGG16
from tensorflow.keras.models import Model, Sequential
from tensorflow.keras import optimizers
# vgg16のインスタンスの生成
input_tensor = Input(shape=(256, 256, 3))
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
# 追加のレイヤーの作成
#---------------------------
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation='relu'))
top_model.add(Dropout(rate=0.5))
top_model.add(Dense(128, activation='relu'))
top_model.add(Dense(7, activation='softmax'))
#---------------------------
# モデルの連結
model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output))
print(model.summary())
# VGG16の重みの固定
for layer in model.layers[:19]:
layer.trainable = False
# モデルのコンパイル
model.compile(loss='categorical_crossentropy',
optimizer='adadelta',
metrics=['accuracy'])
history = model.fit(X_train, y_train, batch_size=100, epochs=100, validation_data=(X_test, y_test))
学習に2時間かかりました。よくセッションが切れなかった。。。
学習過程の可視化とモデルの保存
下記のようにして、学習経過の可視化とモデルの保存を行いました。
import matplotlib.pyplot as plt
# 学習過程の可視化
plt.plot(history.history['accuracy'], label='acc', ls='-', marker='o')
plt.plot(history.history['val_accuracy'], label='val_acc', ls='-', marker='x')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.suptitle('model', fontsize=12)
plt.legend()
plt.show()
# 重みを保存
model.save('homework_model.h5')
学習の結果は下記のようになりました。
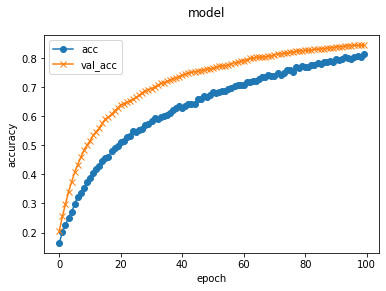
これを見る限り、epochを増やせば、もっと良い結果が出そうですが、時間がかかってしまい、Googleのセッションが切れてしまいそうなので、一旦これでよしとしました。
なお、100epochで、
loss: 0.6684 - accuracy: 0.8124 - val_loss: 0.4951 - val_accuracy: 0.8438
となりました。
約85%は正解するという結果ですね。
チューターさん曰く、それなりに優秀ということでした。
VGG16のおかげだとは思いますが。
Herokuへデプロイ
Herokuにアプリケーションをデプロイし、アプリを公開しました。
基本的には、アプリ制作の講座と同じことをやっていますが、ここでは講座との違いと追加でやったことを書きます。
OpenCVの追加
学習時に前処理を行ったのと同じで、推論時も同じ前処理が必要となります。
前処理では、リサイズとパディングを行う際に、OpenCVが必要となるため、アプリケーションでもこれが使えるようにするために、requirements.txtに下記を追加しました。
opencv-python--headless==4.5.1.48
ちなみに、Herokuで使えないバージョンを指定すると、gitでpushする際にエラーメッセージが表示されます。
今回は、エラーメッセージに表示される、使えるバージョンの中で最新のものを選択しました。
push時のエラー確認
pythonを修正したら、まぁエラーが起きる起きる。。。
その場合は、コマンドプロンプト上で下記コマンドを打ち込んでエラー内容を確認しました。
$ heroku logs --tail
メイン関数
メイン関数は下記のようにして、前処理を追加し、また、結果出力の際は、パンの種類に加えて、スコア値を表示するようにしました。
import os
from flask import Flask, request, redirect, render_template, flash
from werkzeug.utils import secure_filename
from tensorflow.keras.models import Sequential, load_model
from tensorflow.keras.preprocessing import image
import cv2
import numpy as np
import math
classes = ["バゲット","カンパーニュ","クロワッサン","カレーパン","エピ","食パン","フォカッチャ"]
image_size = 256
UPLOAD_FOLDER = "uploads"
ALLOWED_EXTENSIONS = set(['png', 'jpg', 'jpeg', 'gif'])
app = Flask(__name__)
def allowed_file(filename):
# ファイル名に.が含まれるか
# ファイル名の拡張子を確認
return '.' in filename and filename.rsplit('.', 1)[1].lower() in ALLOWED_EXTENSIONS
def preProcess(img_path, height, width):
img = cv2.imread(img_path)
# 縦横の大きさを見て横向きの画像にする(90°回転)
size = img.shape
if size[0] > size[1]:
img = cv2.rotate(img, cv2.ROTATE_90_CLOCKWISE)
o_h, o_w = img.shape[:2]
if img.shape[2] != 3:
print(img_path)
return None, None
output_scale = min([height / o_h, width / o_w, 1])
dst_size = (math.floor(o_h * output_scale), math.floor(o_w * output_scale))
img_comp = cv2.resize(img, tuple(reversed(dst_size)))
pad_y = height - dst_size[0]
pad_x = width - dst_size[1]
output = cv2.copyMakeBorder(img_comp, 0, pad_y, 0, pad_x, cv2.BORDER_CONSTANT, (0, 0, 0))
return output
model = load_model('./homework_model.h5')#学習済みモデルをロード
# GETやPOSTはHTTPメソッドの一種
@app.route('/', methods=['GET', 'POST'])
def upload_file():
# サーバーへデータを送信
if request.method == 'POST':
if 'file' not in request.files:
flash('ファイルがありません')
return redirect(request.url)
file = request.files['file']
if file.filename == '':
flash('ファイルがありません')
return redirect(request.url)
if file and allowed_file(file.filename):
filename = secure_filename(file.filename)
file.save(os.path.join(UPLOAD_FOLDER, filename))
filepath = os.path.join(UPLOAD_FOLDER, filename)
#受け取った画像を読み込んで前処理を実施
img = preProcess(filepath, 256, 256)
#バッチ化
data = np.array([img])
#変換したデータをモデルに渡して予測する
result = model.predict(data)[0]
predicted = result.argmax()
pred_answer = "これは " + classes[predicted] + " で、スコアは " + str(result.max()) + " です"
return render_template("index.html",answer=pred_answer)
return render_template("index.html",answer="")
if __name__ == "__main__":
port = int(os.environ.get('PORT', 8080))
app.run(host ='0.0.0.0',port = port)
結果
試しに、この画像をアプリに入れて推論を実施しました。

結果、下記のように推論がうまく行われていることがわかります。ちょっとスコア値が高すぎる気がしますが・・・

感想
今回は想像以上に良い正解率が出せました。これはVGG16を使うことによる効果と、前処理でアスペクト比を変えずに学習と推論を行っていることによる効果かと思っています。
更に正解率を上げるためには、学習回数を増やす必要がありますが、無料のGoogle Colaboratoryを使う上ではこれくらいが限界かなぁと思います。
他にも、物体検出のモデルと組み合わせるなどして、正解率を上げる方法があるかと思いますが、いまの自分の技術ではこれが限界です。
まずは、動かすという目標は何とかクリアできたので、良しとしたいです。
テーマを進める上で、まだまだ理解できていないと思う点が多々見受けられたので、今後も学習を続けていきたいと思います。