はじめに
10月15日にFastlyのブログにて、「Fastly’s real-time log streaming support extends to Apache Kafka and Elasticsearch」という記事が公開されました。
Fastlyへのリクエストについて、ログを様々なサービスにストリームする「real-time log streaming」の中で、KafkaとElasticsearchへのログ供給が可能になるということです。
現状では「Limited Availability」ということなので、リクエストベースで有効化してもらう、という形でした。
なぜElasticsearchだと嬉しいのか?
従来、CDNのログを扱うというと、FastlyからS3に書き出して、S3からElasticsearchへのロードはプラグインや任意のスクリプトを使っていたかと思います。
今回のLog StreamingのElasticsearchサポートによって、データ転送の手間が無くなる上、基本的にリアルタイムにデータが投入されるようになります。Elasticsearchのインデックス更新頻度にもよりますが、1秒未満でログが集計対象になるスピード感でした。
ログがリアルタイムに扱えると…
- 現状把握、異常検知 が直ぐに行える。問題の発見が早くなるので機会損失を抑えられる
- Elasticsearch/Kibanaの機械学習を駆使して、最新のデータに基づいた予測や分析結果が得られる。サービス側に結果をフィードバックして、最適化サイクルを迅速に回せる
- リアルタイムなモニタリング、分析のソリューションは色々あるが、コストもかかる。FastlyとElasticsearchで完結できると、データ反映速度とコストのバランスが良い
個人的には、マーケティングデータを扱う前提で使っているので、
- 機械学習、予測、形態素解析 といった機能が組み込まれていて、コーディング無しにUIで構成できる
- Kibanaの可視化は最高! チャートを作ったりダッシュボード化するのはもちろん、Timelionで異なる期間の数値変動を1つのチャートで比較できたり、Canvasを使ってインフォグラフ的な可視化もできてしまう
- 圧倒的なデータ構造の柔軟性。IngestlyではいくつかのフィールドはJSON文字列としてログに埋込、Elasticsearch上ではフィールドのネストを展開して扱える
やってみる
IngestlyのデータをBigQueryだけでなく、Elasticsearchにも送れたら、以前の職場で構築した、RDBとNoSQLの併用でデータ構造の柔軟性と扱いやすさを両立した構成ができるなと思い立ち、早速サポートに有効化をリクエストしました。

有効化はメールまたはサポートポータルから、FastlyのService IDを明記して有効化をお願いするだけです。
もちろん日本語でOK。
Elasticsearch側の設定(BASIC認証前提)
ロールとユーザーの作成
まず、権限を付与するための準備として「Role」を作ります。
Roleで重要なのは、Fastlyがログを書き込むときに、書き込む先のインデックスが存在しない場合、ログの投入と同時にインデックスを作成する必要があるので、「create_index」権限が必要です。
また、アクセスできるインデックスには、これから作成されることになる(=現時点ではまだ存在しない)インデックスも指定する必要があるので、「Indices」には手入力でインデックス名のパターンを指定してやります。
もし権限の不足があると、FastlyのUIで「API Error」が表示され、Elasticsearchから401エラーが返っている等で状況を把握できます。

次に、FastlyがElasticsearchに接続するためのユーザーを作成します。
適当に作成し、さきほど定義したロールを選択します。

Mapping TemplateをPUTしておく
Ingestlyの場合、ログを正しく扱うためにMapping Templateもリポジトリに入れてあります。
Mapping Templateを先にPUTするかどうかは、好みやログの書式の成熟度によります。
Elasticsearchは型を自動判定してくれますが、最初のレコードの型に基づいて決まってしまうので、後続のログで型が合わないとか、文字列と数値が意図したものと逆だったりすると面倒です。
なので、ある程度先に型を指定できるとスムースに集計に進めます。
Dynamic Templateを使って、フィールド名とのマッチングで自動処理することができるので、全フィールドをちまちま定義する必要はありません。
Mapping Templateで重要な設定として、レプリカやシャードの数、リフレッシュ頻度、圧縮の有無を上手く設定することで、コスト効率やパフォーマンスを改善できます。目的や期待する性能に応じて調整しましょう。(ここでは詳細は触れません)
Fastly側の設定
★ 前提として、Elasticsearch連携が有効化されていること
Fastlyでは、CONFIGUREタブからLoggingを開き、Elasticsearch連携を追加します。
設定は見ての通りですが、ログのフォーマットはJSON形式にしつつ、内部でVCLで使う関数が呼び出せます。ただあまり複雑な処理はできそうにありません。

このログフォーマット、BigQuery連携を既に利用している人は同じものがそのまま使えるのですが、BigQueryでの扱いやすさのためにフラットな構造にしていることが多いと思います。Elasticsearchはフィールドをネストできるので、直感的に扱えるか等を考えてうまく改良してもいいと思います。
それから、エンドポイントや認証情報を指定します、今回はBASIC認証なので、ユーザー名とパスワードを指定しています。

「Index」のところで、書き込み先のインデックス(RDB的に言うとテーブル)を指定しますが、BigQuery連携と似た、時系列での分割をサポートしています。
Elasticsearchでは、インデックスが肥大化するとパフォーマンスが低下するので、日や時の粒度でインデックスを分割する戦略を採ることがあります。Fastlyからのログストリームでも、動的にインデックス名を指定して時系列インデックスに分割することができます。
書式はSTRFTIMEが利用できます。
Kibanaの設定
Kibanaでログを扱うためには、インデックスパターンを定義します。
インデックスが時系列に分割されるので、ワイルドカードで部分一致させる形で指定します。
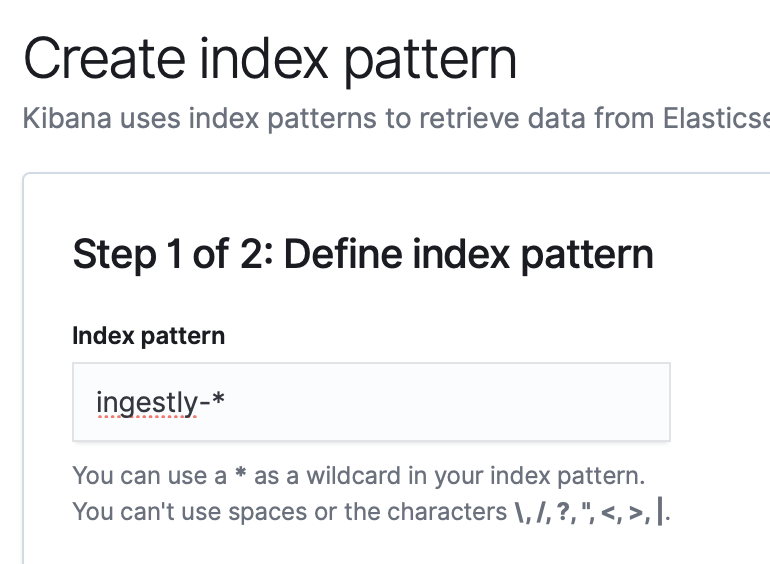
ということで、UIでポチポチやれば直ぐ連携できてしまいます。
BigQueryより分かりやすく、データの探索もしやすいと思います。
まとめ
- 有効化はサポートに依頼しましょう
- Fastly側のLog Format、Elasticsearch側のMapping Templateは上手く設計しましょう
- ElasticsearchでRole設定に注意
- セットアップも分析もすごく簡単なのでオススメ