ネストした多対多データのjsonファイルを扱う中で、行の対象を変えることがあります。
Pandasを用いてそれを行う方法を紹介します。
多対多のデータの例として、ファッションアイテムとコーディネートのデータを取り上げます。
WEARのようなコーディネート投稿サイトでは、1つのコーディネートに対し複数のアイテムが使われ、逆に、1つのアイテムが複数のコーデに使われることがあります。
なので、コーディネートとアイテムは多対多の関係にあります。
このようなデータにおいて、行の対象をコーディネートからアイテム、アイテムからコーディネートにする方法を紹介します。
具体的には、以下のような2つの形のDataFrameを行ったり来たりする変形を行います。
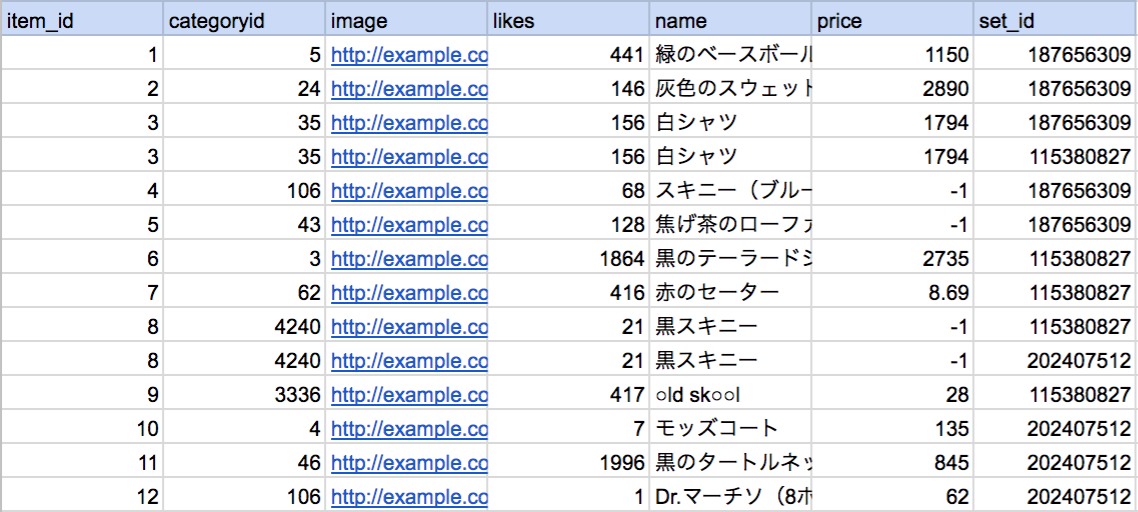
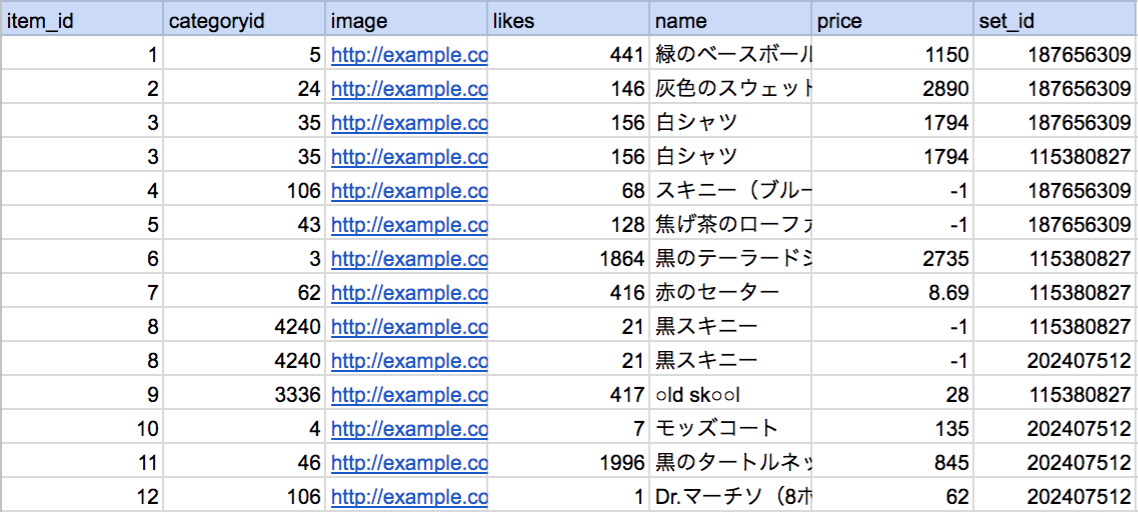
以下、行がコーディネートのDataFrame

以下、行がアイテムのDataFrame
先にコードだけ載せます。
コーデ→アイテム
import pandas as pd
from pandas import json_normalize
df_items = json_normalize(df.to_dict("records"),
"items", "set_id")
df_items.sort_values("item_id")
アイテム→コーデ
df_items.groupby("set_id")\
[df_items.columns.difference(df.columns)]\
.apply(lambda df_group: df_group.to_dict("records")) \
.rename("items")\
.reset_index()
データの確認
jupyter notebook で実行していきます。
sample.json にデータがあるとし、読み込みます。
初めは、行がコーディネートの形だとします。
import pandas as pd
json_file = "./sample.json"
df = pd.read_json(json_file)
df

items カラムの各行には、そのコーデで使っているアイテムのリストが入っています。
アイテムは辞書で表現されているので、辞書のリストが各行に入っています。
具体的に、 items カラムの1行目を見てみます。
このコーデは5つのアイテムを使っていることがわかります。
df["items"].iloc[1]
\[{'index': 1,
'name': '黒のテーラードジャケット',
'price': 2735.0,
'likes': 1864,
'image': 'http://example.com/06.jpg',
'categoryid': 3},
{'index': 2,
'name': '赤のセーター',
'price': 8.69,
'likes': 416,
'image': 'http://example.com/07.jpg',
'categoryid': 62},
{'index': 3,
'name': '白シャツ',
'price': 1794.0,
'likes': 156,
'image': 'http://example.com/03.jpg',
'categoryid': 35},
{'index': 4,
'name': '黒スキニー',
'price': -1,
'likes': 21,
'image': 'http://example.com/08.jpg',
'categoryid': 4240},
{'index': 5,
'name': '○ld sk○○l',
'price': 28.0,
'likes': 417,
'image': 'http://example.com/08.jpg',
'categoryid': 3336}\]
行をコーディネートからアイテムにする
上記のような 辞書のリスト のカラムに対し、リストの各要素であるアイテム(辞書)を行とするDataFrameを作るには pandas.io.json.json_normalize を用います。
from pandas.io.json import json_normalize
df_items = json_normalize(df.to_dict("records"),
"items", "set_id")
df_items.sort_values("item_id")
上記のコードを実行すると、以下のように行がアイテムのDataFrameを得られます。
上記のコードの詳細を追っていきます。
.to_dict("records")
json_normalize(df.to_dict("records"),
"items", "set_id")
df.to_dict("records") はDataFrameを辞書(のリスト)にするのですが、方法がいくつかあり、orient という引数で指定します。
orient="records" では以下のように、各行を辞書としたリストが作成されます。各辞書のキーは「カラム名」、バリューは「その行、列での値」になります。
[
{
"items": [
{
"item_id": 10,
"name": "モッズコート",
"price": 135.0,
"likes": 7,
"image": "http://example.com/10.jpg",
"categoryid": 4
},
{
"item_id": 11,
"name": "黒のタートルネック",
"price": 845.0,
"likes": 1996,
"image": "http://example.com/11.jpg",
"categoryid": 46
},
{
"item_id": 8,
"name": "黒スキニー",
"price": -1,
"likes": 21,
"image": "http://example.com/08.jpg",
"categoryid": 4240
},
{
"item_id": 12,
"name": "Dr.マーチソ(8ホール)",
"price": 62.0,
"likes": 1,
"image": "http://example.com/12.jpg",
"categoryid": 106
}
],
"likes": 408,
"name": "寒い冬も怖くない、ドラゲナイコーデ",
"set_id": 202407512,
"views": 2554
},
...
]
json.json_normalize
json_normalize(df.to_dict("records"),
"items", "set_id")
-
data=df.to_dict("records"):変形したいDataFrameを辞書のリストにしたもの -
record_path="items":要素を展開したい 辞書のリスト のカラム名 -
meta="set_id":展開後も残しておきたい元のDataFrameのカラム名
アイテムの辞書に set_id は含まれていません。
もし、 meta 引数がなければ、変形後に set_id は持ち越されません。
また、 持ち越したいカラムが複数あれば、meta 引数をカラム名の リストで指定する こともできます。
上記以外にも引数があり、より複雑な整形ができます。
詳しくは公式ドキュメントで確認できます。
行をアイテムからコーディネートに戻す
今度は逆に、行をアイテムからコーディネートに戻します。
df_new = df_items.groupby("set_id")\
[df_items.columns.difference(df.columns)]\
.apply(lambda df_group: df_group.to_dict("records")) \
.rename("items")\
.reset_index()
df_new
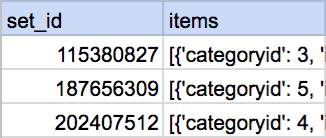
上記のコードを実行すると、以下のように行がコーディネートのDataFrameに戻すことができます。
ただし、 df_items 作成時に落としたカラムは戻せません。
上記のコードの詳細を追っていきます。
.groupby("set_id")
df_items.groupby("set_id")\
[df_items.columns.difference(df.columns)]\
.apply(lambda df_group: df_group.to_dict("records")) \
.rename("items")\
.reset_index()
groupby を行うと、引数で指定したカラムが同じ値を持つ行どうしをグループとしてまとめます。
結果として、 DataFrameを要素に持つSeriesのようなもの ができます。
各要素のDataFrameはグループを表し、指定したカラムは同じ値で統一されています。
今回は、コーデのidである set_id が同じアイテムのグループが作られます。
[df_items.columns.difference(df.columns)]
df_items.groupby("set_id")\
[df_items.columns.difference(df.columns)]\
.apply(lambda df_group: df_group.to_dict("records")) \
.rename("items")\
.reset_index()
この記述では、変形後のアイテムの辞書に set_id が入り込まないようにしています。
groupby の後も、DataFrameと同様に [[カラム名]] で使いたいカラムに絞ることができます。
DataFrame.columns には difference という演算が備わっており、 df1.columns.difference(df2.columns) とすることで、 df1 のうち df2 に含まれないカラム名を指定することができます。
今、 df_items のうち、 df と共有しているカラムは含めたくないので、 df_items.columns.difference.(df.columns) としています。
こうすることで、 json_normalize で meta を複数指定した場合にも対応できます。
.apply(lambda df_group: df_group.to_dict("records"))
df_items.groupby("set_id")\
[df_items.columns.difference(df.columns)]\
.apply(lambda df_group: df_group.to_dict("records")) \
.rename("items")\
.reset_index()
Series や DataFrame 同様、 groupby の結果にも apply を施すことができます。
apply で指定した関数の引数は、 各グループを表すDataFrameになります。
今回の例だと、同じコーデでまとめたアイテムを行とするDataFrameです。
これを最初の形と同じく辞書にして、ほぼ完成です。
ただ、このままだと、コーデのid set_id を index に持つSeriesができるだけです。
元の形にするには、DataFrameにします。
.rename("items").reset_index()
df_items.groupby("set_id")\
[df_items.columns.difference(df.columns)]\
.apply(lambda df_group: df_group.to_dict("records")) \
.rename("items")\
.reset_index()
reset_index は index を振り直す以外に、Series を DataFrameにする ことにも使えます。
元の値とindexをカラムに持つDataFrameができます。
また、単純に振り直す場合は、 reset_index(drop=True) を使います。
ただ、これだけだと、できあがったDataFrameのカラムが [["set_id", 0]] となってしまいます。
なので、DataFrameにする前にSeriesの名前を rename で "items" にしておくことで、 [["set_id", "items"]] とすることができます。
まとめ
Pandasを用いて、ネストした多対多データのjsonファイルを読み込んだDataFrameの行の対象を変える方法を紹介しました。
例としてファッションのデータを使い、行をコーディネート→アイテム→コーディネートと変形するコードを記載しました。
コーディネート→アイテムの場合は json_normalize 、 アイテム→コーディネートの場合は groupby と apply(lambda df:df.to_dict("records")) がキーポイントでした。
それでは皆さん、良いお年を!