論文メモです。ポケモン対戦の用語がわかる人向け。
Showdown AI Competition
論文はこちらから読めます。
Showdownを使ってAI同士のポケモン対戦を行わせる実験。
ルール
第6世代(XY、ORAS)
シングルバトル6-6でチームはランダムに生成される。技構成もランダムに決まるがでんきショックやはねるなどの通常対戦で使用されない技は除かれている。
基本的にはShowdownコミュニティのローカルルールに準拠。
- 同じ種類のポケモンは1匹まで
- 複数催眠禁止
- 意図的な無限ターン禁止(交代し続ける選択の他、このルールではターンスキップが可能なため。後述)
- バトンタッチを覚えているポケモンは1匹まで。また、そのポケモンは加速と積み技を同時に持っていてはいけない。
- 影分身、小さくなる、地割れ、ハサミギロチン、つのドリル、絶対零度、いばるの使用禁止
- ゲンガナイト、ガルーラナイト、ルカリオナイト、クチートナイト、ヤミラミナイト、ボーマンダナイト、こころのしずくの使用禁止
- 対戦での使用頻度が低いポケモンの禁止
- このサイトでBannedとなっているポケモン(ほとんど禁止級伝説だけどなぜかギルガルドが含まれている)および使用頻度が低いポケモンの禁止
- 挙動が複雑になるため?ゾロアークを禁止
コンピュータ同士での対戦ということで以下のルールを追加している。
- 各エージェントは20秒以内に行動を決定する。それができない場合ターンをスキップする(何もしないをする)
- 経過ターン数が500を超えた場合引き分けとする
- もしエージェントがエラーや例外を吐いた場合は敗北として扱う
このゲームをAIにやらせる上で難しいところ
分岐する枝の数
分岐する枝の数が状態とプレイヤーの選択によって変化する。基本的には4通りの技を使うか裏のいずれかのポケモンに交代するかだが、アンコールなどによって技の選択肢が減ることもあるしバトンタッチやとんぼがえりなどによって技を出した後交代する交代先についての選択肢が生じるため枝の数が増える。
無限ターンが可能
人間同士での対戦ではおおよそ60ターン以内に対戦は終了するが、理論的に上限があるわけではないので適切に設計されていないエージェント同士の対戦では例えば両者共にポケモンを交代し続けるなどの行動を取ることで無限ターンが発生しうる。ルールの項でターン数の制限を設けているのはこの可能性を排除するため。
同時ターン制である
このゲームでは双方のプレイヤーが行動を選択した後、実際にその行動が行われるまでにタイムラグがある。例えば、プレイヤー2の選択した技によって先にプレイヤー1のポケモンが倒された場合、プレイヤー1のポケモンは選択した技を出すことはない。このように、エージェントは実際に行動するタイミングではなくその前に意思決定を行うため、実際の行動時の状態ではその選択が最善でなくなっていることがありうる。
状態の評価に必要な要素が多い
HPは状態を評価するための重要な指標であるため、HPが多い方が概ね有利であり相手のHPを多く減らせる技は概ね有効な行動とみなせる。しかし実際には色々な状態異常・ステータス補正・フィールド効果などがあるため、HPの大小だけでは状態の良し悪しを判断できない。
行動結果に確率が絡む
行動結果は以下の点で確率の影響を受ける
- 技の命中率
- ダメージ計算における乱数
- 急所
- 追加効果
また、これらの確率は持ち物・特性・天候などの影響を受けるため、戦略によって確率を増減できる。
不完全情報
相手のポケモンについて、以下の要素を事前に知ることはできない。
ただし、ドメイン知識により予測できる部分はある。
- 特性
- 努力値
- 技構成
- 持ち物
- 交代のタイミング
ポケモンの偽装
ゾロアークのイリュージョンのこと。仕様上、ドメイン知識を持たないエージェントがイリュージョンを看破するのは難しいため今回の実験からはゾロアークを除いている。
シミュレーションコスト
Showdown側の制約があるため、複雑な戦略を採っていたり状態探索を行うようなエージェントが十分な数の状態を探索すると非常に時間がかかる。
ドメイン知識
タイプ相性、ポケモンの並び、行動時ではなくそのしばらく後に効果を発揮する行動の存在(ステルスロック、まきびしなど)など、エージェントに考慮させることで戦略が改良されるかもしれないドメイン知識について触れている。
実験
以下の戦略のエージェント同士で対戦。
- ランダム(Random)
- 幅優先探索(BFS)
- ミニマックス法(Minimax)
- Q学習(SLP, MLP)
- One Turn Lookahead(OTL)
- Type Selector(TS)
- 枝刈りあり幅優先探索(PBFS)
OTLとType Selectorについて説明する。OTLは「目の前の相手ポケモンに与えるダメージを自分のパーティの全ポケモンの技について計算し、それが最大である技を今場に出ているポケモンが持つならその技を選択、そうでないならその技を持つポケモンに交代する」というアルゴリズム。Type Selectorは「目の前の相手ポケモンを瀕死にできる技があるならそれを選択する、そうでない場合、タイプ相性が有利であれば居座って最大のダメージを与える技を選択、不利であれば最も有利なポケモンに交代する」というアルゴリズム。
結果
ランダムに配られたパーティで3回対戦→パーティを入れ替えて3回対戦で、多く勝った方の勝ち。各組み合わせで15Round (90Battle)の対戦を行い、各セルは行エージェントが列エージェントに勝利したRound数とBattle数を示す。
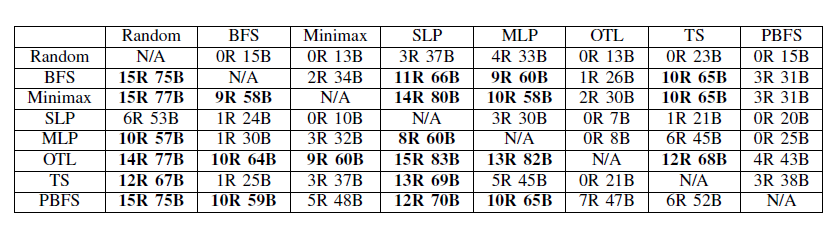
PBFSおよびOTLが他のアルゴリズムよりよい結果を残した。PBFSがBFSやMinimaxに優越したのは、枝刈りにより探索時間を減らすことで20秒以内に行動を決めるルールに抵触しにくかったから。
OTLの最大ダメージを狙っていく戦略はこの実験では強かったが人間相手では通用しないだろう。
結論と展望
- OTLはベースラインの戦略に使えるかもしれない
- ドメイン知識により枝刈りの効率がよくなれば探索ベースの手法もよいかもしれない
- Q学習は今回は奮わななかったけど今後に期待
- 今回はパーティはランダムだったがパーティ構築を含めた拡張もやりたい。
感想
実験条件がちゃんと書かれていないなどよくわからない部分の多い論文だけど、One Turn Lookahead戦略がそこそこ強かったという結果は面白く、ポケモン対戦AIを構築する上では少なくともこの戦略に勝てる必要があると感じた。数報この論文を引用している論文が出ているようなので、そちらも読んでおきたい。