目次
1. 概要
セグメンテーションの SegNeXt [1] (2022/9) と MetaSeg [2] (2024/1) のエンコーダで採用されている Multi-Scale Convolutional
Attention Network (MSCAN) のネットワーク構造と精度について確認する。
主に、MSCAN が提案された SegNeXt の論文を読み進める。
実装について、今回は独自に作成してみたが、mmsegmentation にもある。
[補足] SegNeXt と MetaSeg は比較的最近のセグメンテーション手法で、精度も良いので1回使ってみてもいいかもしれません。
2. ネットワーク構造
2.1. 全体のネットワーク構造について
大きく入力層、MSCAN、ダウンサンプリングからなる。
入力画像のサイズを 3×H×W (チャンネル数×高さ×幅)とする。
-
入力層
入力層で画像サイズを H/4×W/4 にする。 -
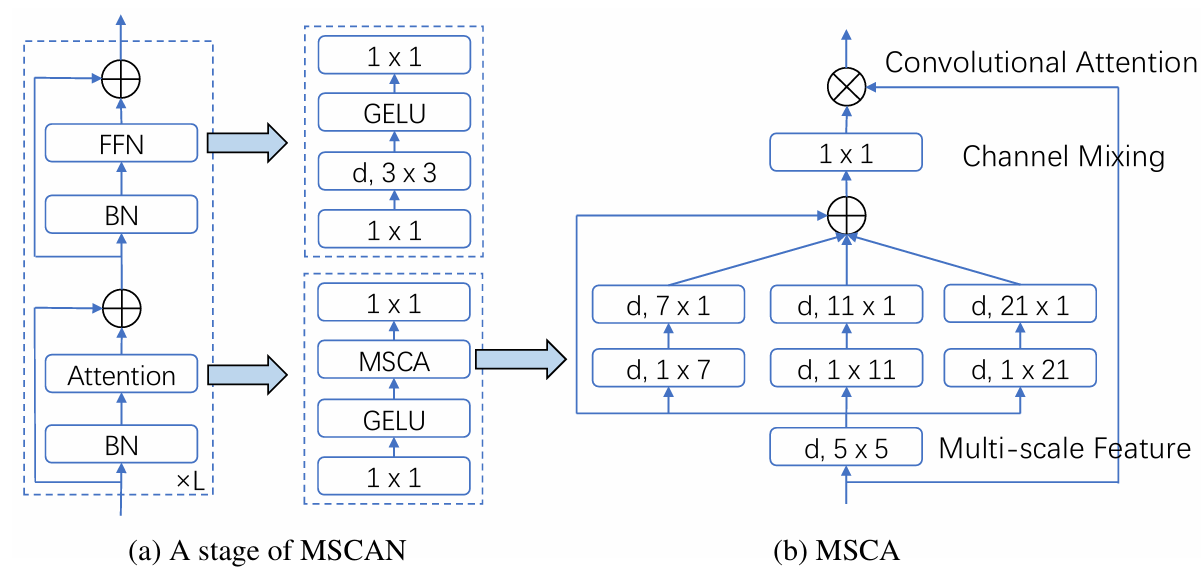
MSCAN(図 2.1.1)
次の2つのブロックからなる。- Attention
バッチ正規化後にアテンションを行う。
アテンションでは、MSCA というブロックがあり、様々なサイズの物体をとらえられるように、異なるカーネル数の Depth-wise 畳み込み後に、チャンネルをミックスする。 - FFN
バッチ正規化後に、FNN に入力される。
FNN は、MLP → Depth-wise 畳み込み → GELU → MLP となっている。
レイヤー正規化よりも、バッチ正規化の方が性能が良かったという記載がある(詳細は不明だが、チャンネルミキシングと関係がありそう?)。
また、上の2つのブロックでは、スキップ接続を適用している(一般的な制度向上)。 - Attention
-
ダウンサンプリング
各 MSCAN の後に、画像サイズが 1/2 倍ずつ減るようにダウンサンプリング(カーネルサイズ 3×3、ストライド 2)をする。
2.2. パラメータについて
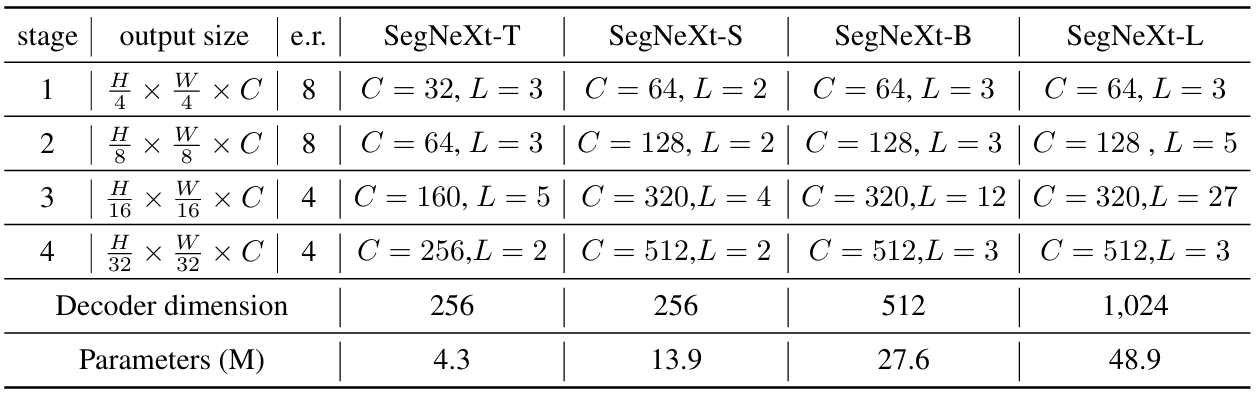
SegNeXt における MSCAN は、S, T, B, L の4種類ある。
表 2.2.1 において、e.r. は FFN の隠れ層の次元の倍率、C はチャンネル数、L は MSCAN のブロック数を表す。
3. 精度
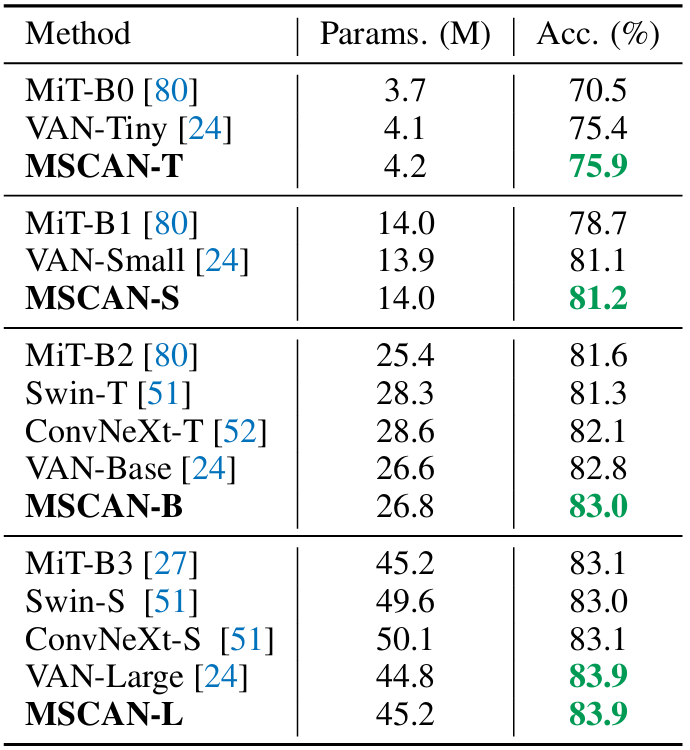
MSCAN は、MiT、Swin、ConvNeXt、等と比較しても、パラメータ数も同程度で、精度も最良である。
4. 実装
全体像は次の通りである。
入力層、または、ダウンサンプリングの後に図 2.1.1 の MSCAN の各ブロックに入力する。この記事では、画像分類用に、最後に全結合層を追加している。
class MSCAN(nn.Module):
def __init__(self, in_ch: int, dim_list: list, hidden_dim_ratio: list, num_layers: list, num_classes: int):
super(MSCAN, self).__init__()
self.in_ch = in_ch
self.dim = dim_list
self.hidden_dim_ratio = hidden_dim_ratio
self.num_layers = num_layers
model_list = []
for i in range(len(dim_list)):
if i == 0:
model_list += [StemConv(in_ch=in_ch, dim=dim_list[0])]
else:
model_list += [DownConv(dim_list[i-1], dim_list[i])]
model_list += [Block(dim=dim_list[i], hidden_dim_ratio=hidden_dim_ratio[i]) for _ in range(num_layers[i])]
self.model = nn.Sequential(*model_list)
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.linear = nn.Linear(dim_list[-1], num_classes)
def forward(self, x: torch.Tensor):
x = self.model(x)
x = self.avg_pool(x)
x = x.flatten(1)
x = self.linear(x)
return x
入力層とダウンサンプリングは次の通りである。
class StemConv(nn.Module):
def __init__(self, in_ch: int, dim: int):
super(StemConv, self).__init__()
self.conv1 = nn.Conv2d(in_ch, dim, kernel_size=(3, 3), stride=2, padding=1)
self.bn = nn.BatchNorm2d(dim)
self.conv2 = nn.Conv2d(dim, dim, kernel_size=(3, 3), stride=2, padding=1)
self.gelu = nn.GELU()
def forward(self, x: torch.Tensor):
x = self.conv1(x)
x = self.bn(x)
x = self.conv2(x)
x = self.gelu(x)
return x
class DownConv(nn.Module):
def __init__(self, in_ch: int, dim: int):
super(DownConv, self).__init__()
self.conv = nn.Conv2d(in_ch, dim, kernel_size=(3, 3), stride=2, padding=1)
def forward(self, x: torch.Tensor):
x = self.conv(x)
return x
MSCAN の各ブロックは次の通りである。
BN→Attention(MSCA)→BN→FFN の順に入力する。
class Block(nn.Module):
def __init__(self, dim: int, hidden_dim_ratio: int):
super(Block, self).__init__()
self.dim = dim
self.bn = nn.BatchNorm2d(self.dim)
self.attn = Attention(self.dim)
self.ffn = FNN(dim=self.dim, hidden_dim_ratio=hidden_dim_ratio)
def forward(self, x: torch.Tensor):
out1 = self.bn(x)
out1 = self.attn(out1)
out2 = out1 + x
out3 = self.bn(out2)
out3 = self.ffn(out3)
return out2 + out3
class MSCA(nn.Module):
def __init__(self, dim: int):
super(MSCA, self).__init__()
self.conv1 = nn.Conv2d(dim, dim, kernel_size=(5, 5), stride=1, padding=(5//2, 5//2), groups=dim)
self.conv21 = nn.Conv2d(dim, dim, kernel_size=(7, 1), stride=1, padding=(7//2, 0), groups=dim)
self.conv22 = nn.Conv2d(dim, dim, kernel_size=(1, 7), stride=1, padding=(0, 7//2), groups=dim)
self.conv31 = nn.Conv2d(dim, dim, kernel_size=(11, 1), stride=1, padding=(11//2, 0), groups=dim)
self.conv32 = nn.Conv2d(dim, dim, kernel_size=(1, 11), stride=1, padding=(0, 11//2), groups=dim)
self.conv41 = nn.Conv2d(dim, dim, kernel_size=(21, 1), stride=1, padding=(21//2, 0), groups=dim)
self.conv42 = nn.Conv2d(dim, dim, kernel_size=(1, 21), stride=1, padding=(0, 21//2), groups=dim)
self.conv_out = nn.Conv2d(dim, dim, kernel_size=(1, 1), stride=1, padding=0)
def forward(self, x: torch.Tensor):
out1 = self.conv1(x)
out2 = self.conv21(x)
out2 = self.conv22(out2)
out3 = self.conv21(x)
out3 = self.conv22(out3)
out4 = self.conv21(x)
out4 = self.conv22(out4)
out1 = out1 + out2 + out3 + out4
out1 = self.conv_out(out1)
return x * out1
class Attention(nn.Module):
def __init__(self, dim: int):
super(Attention, self).__init__()
self.conv1 = nn.Conv2d(dim, dim, kernel_size=(1, 1), stride=1, padding=0)
self.msca = MSCA(dim)
self.gelu = nn.GELU()
self.conv2 = nn.Conv2d(dim, dim, kernel_size=(1, 1), stride=1, padding=0)
def forward(self, x: torch.Tensor):
x = self.conv1(x)
x = self.msca(x)
x = self.gelu(x)
x = self.conv2(x)
return x
class FNN(nn.Module):
def __init__(self, dim: int, hidden_dim_ratio: int):
super(FNN, self).__init__()
hidden_dim = hidden_dim_ratio * dim
self.conv1 = nn.Conv2d(dim, hidden_dim, kernel_size=(1, 1), stride=1, padding=0)
self.dwconv = nn.Conv2d(hidden_dim, hidden_dim, kernel_size=(3, 3), stride=1, padding=1, bias=True, groups=hidden_dim)
self.conv2 = nn.Conv2d(hidden_dim, dim, kernel_size=(1, 1), stride=1, padding=0)
self.gelu = nn.GELU()
def forward(self, x: torch.Tensor):
x = self.conv1(x)
x = self.dwconv(x)
x = self.gelu(x)
x = self.conv2(x)
return x
使用例
# 入力確認用の配列(バッチサイズ, チャンネル数, 高さ, 幅)
x = torch.randn(4, 3, 512, 512)
# モデル
model = MSCAN(
in_ch=x.shape[1], # 画像のチャンネル数
dim_list=[32, 64, 160, 256], # チャンネル数
hidden_dim_ratio=[8, 8, 4, 4], # FFN の隠れ層の次元の倍率
num_layers=[3, 3, 5, 2], # ブロック数
num_classes=10 # クラス数
)
# モデルに入力
out = model(x)
5. 参考文献
[1] Meng-Hao Guo, , Cheng-Ze Lu, Qibin Hou, Zhengning Liu, Ming-Ming Cheng, Shi-Min Hu. "SegNeXt: Rethinking Convolutional Attention Design for Semantic Segmentation." (2022). https://arxiv.org/abs/2209.08575, https://github.com/Visual-Attention-Network/SegNeXt
[2] Beoungwoo Kang, , Seunghun Moon, Yubin Cho, Hyunwoo Yu, Suk-Ju Kang. "MetaSeg: MetaFormer-based Global Contexts-aware Network for Efficient Semantic Segmentation." (2024). https://arxiv.org/abs/2408.07576, https://github.com/hyunwoo137/MetaSeg