はじめに
昔から卓球、特に男子卓球が好きで、選手の強さとか分析してみたいなと思い、ベイズモデリングを使って色々と試してみました。分析にあたっては、アヒル本の第10章にあるプロ棋士の分析やテニス選手でのベイズモデリングの記事を大いに参考にさせていただきました(というか後者の写経ですね)。
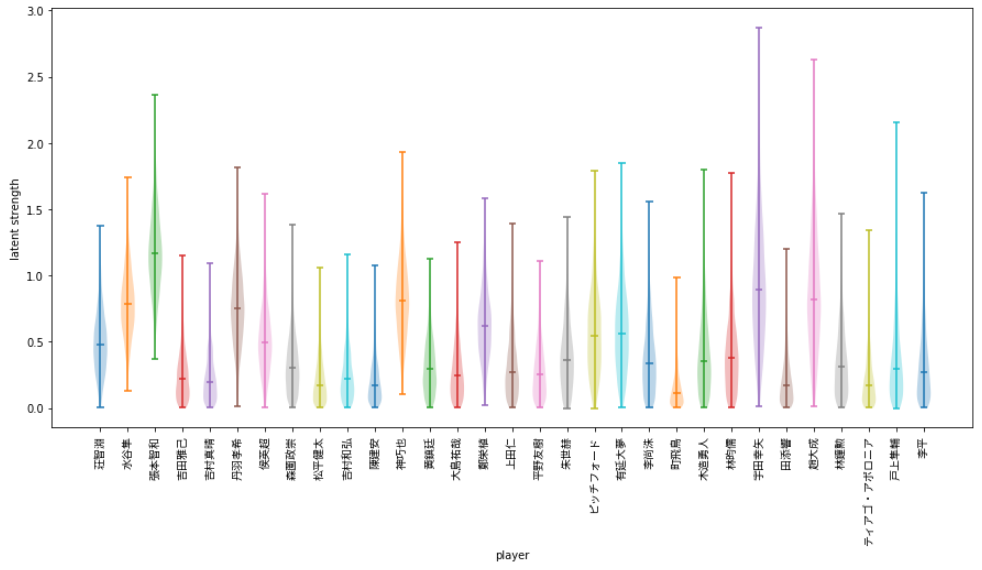
↑こういうの作っていきます
ベイズモデリング
今回使用するモデルはこちらです。
\begin{aligned}
performance[g,1] &\sim Normal(\mu[Loser[g]], \sigma[Loser[g]]) &g=1,...,G \\
performance[g,2] &\sim Normal(\mu[Winner[g]], \sigma[Winner[g]]) &g=1,...,G \\
performance[g,1] &< performance[g,2] &g=1,...,G \\
\mu[n] &\sim Normal(0, \sigma_{\mu}) &n=1,...,N \\
\sigma[n] &\sim Gamma(10, 10) &n=1,...,N \\
\end{aligned}
ここで、$Loser$を負けたプレイヤーのインデックス、$Winner$を勝ったプレイヤーのインデックス、各選手の強さを$\mu[n]$、勝負のムラを$\sigma[n]$として、1回の勝負で発揮する力は平均$\mu[n]$、標準偏差$\sigma[n]$のパラメータを持つ正規分布から生成されると考えます。
各選手は基本的に$\mu[n]$の強さを持っているのですが、毎回の試合で同じ強さを発揮できるとは限らず、好調なときもあれば、不調なときもあります。$\sigma[n]$はその試合ごとのムラを表現しています。
そして、勝負の結果は試合ごとのパフォーマンスが大きい方が勝つと考えます。
なお、標準偏差$\sigma[n]$の弱情報事前分布としてはガンマ分布を使用します。Stanでは事前分布を指定しないと自動的に制限された範囲内で十分に幅の広い一様分布が使われるのですが、それではパラメータが収束しなくなりました。そこで、かならず正の値を取り、正規分布に近い形の$Gamma(10, 10)$を指定し、収束しやすくします。
データ
Tリーグデータ
2018年から開幕した卓球プロリーグのTリーグの勝敗データを使用します。対象期間は2018年の開幕戦から直近の11月22日までです。自分でせっせと集めましたので、多少ミスがあるかもしれません…。データはこんな感じです。
import pandas as pd
df = pd.read_excel("df.xlsx")
df.head(10)
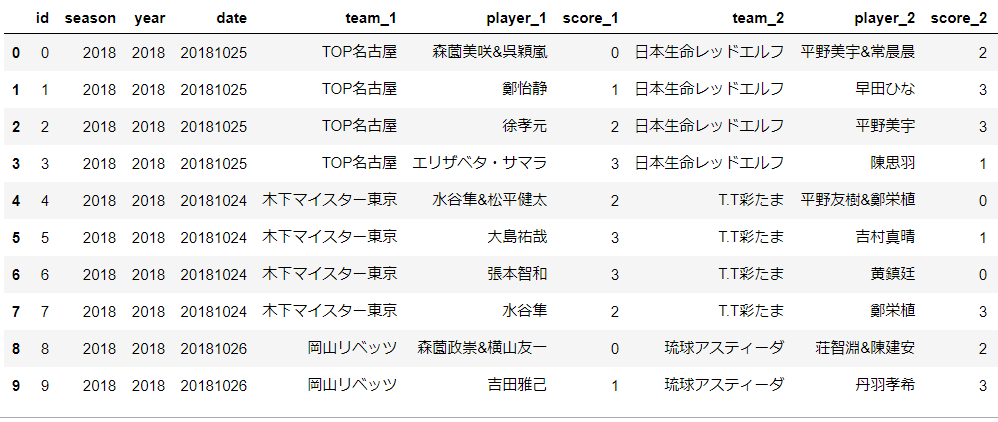
seasonはTリーグのシーズン、yearは開催年、dateは試合日、teamは所属チーム、playerは選手、scoreは獲得したゲーム数となっています。また、playerで2人の選手が&で繋がれているものはダブルスになります。あと、ビクトリーマッチも含まれています。
今回はこの中から、男子選手のシングルスの試合のみを抽出して分析を進めていきます。
team_male = ['木下マイスター東京', '岡山リベッツ', 'T.T彩たま', '琉球アスティーダ']
df_male = df[df.team_1.isin(team_male)].reset_index(drop=True)
df_male_singles = df_male[~df_male.player_1.str.contains("&")].reset_index(drop=True)
df_male_singles.head()
選手
あまりにも試合数が少ないとパラメータが収束しないので、ある程度試合に出ている選手を抽出します。まずは出場試合数の確認。
df_male_singles.player_1.append(df_male_singles.player_2).value_counts()
荘智淵 38
水谷隼 37
張本智和 35
吉田雅己 31
丹羽孝希 30
吉村真晴 30
侯英超 28
森薗政崇 26
松平健太 25
吉村和弘 25
陳建安 24
神巧也 23
鄭栄植 21
黄鎮廷 21
大島祐哉 21
上田仁 18
平野友樹 17
朱世赫 16
ピッチフォード 14
李尚洙 13
有延大夢 13
町飛鳥 10
宇田幸矢 9
木造勇人 9
林昀儒 9
田添響 8
趙大成 7
林鐘勲 7
ティアゴ・アポロニア 5
李平 5
戸上隼輔 5
三部航平 4
ワン・ヤン 4
村松雄斗 4
モーレゴード 4
及川瑞基 4
パナギオティス・ギオニス 3
田中佑汰 3
マルコス・フレイタス 2
英田理志 2
篠塚大登 2
岸川聖也 2
高見真己 1
横山友一 1
松平賢二 1
松山祐季 1
dtype: int64
台湾のレジェンドの荘智淵選手が、水谷選手、張本選手を抑えて、堂々の出場回数1位!ちなみに、必要な最低試合数はモデルを回してみて収束するか確認していきました。今回は私の趣味も含めて最低5回以上出場している選手を抽出しました。
list_target_player = ['荘智淵', '水谷隼', '張本智和', '吉田雅己', '吉村真晴',
'丹羽孝希', '侯英超', '森薗政崇', '松平健太', '吉村和弘',
'陳建安', '神巧也', '黄鎮廷', '大島祐哉', '鄭栄植',
'上田仁', '平野友樹', '朱世赫', 'ピッチフォード',
'有延大夢', '李尚洙', '町飛鳥', '木造勇人', '林昀儒',
'宇田幸矢', '田添響', '趙大成', '林鐘勲',
'ティアゴ・アポロニア', '戸上隼輔', '李平']
df_male_target =
df_male_singles[df_male_singles.player_1.isin(list_target_player) &
df_male_singles.player_2.isin(list_target_player)].reset_index(drop=True)
また、モデリングからも分かる通り、今回必要になるのは、WinnerとLoserの組み合わせになりますので、データを整形していきます。
list_male_singles_win = []
list_male_singles_lose = []
for i in range(df_male_target.shape[0]):
if df_male_target.score_1[i] > df_male_target.score_2[i]:
list_male_singles_win.append(df_male_target.player_1[i])
list_male_singles_lose.append(df_male_target.player_2[i])
else:
list_male_singles_win.append(df_male_target.player_2[i])
list_male_singles_lose.append(df_male_target.player_1[i])
df_male_win_lose = pd.DataFrame({"winner":list_male_singles_win,
"loser": list_male_singles_lose})
df_male_win_lose.head()

可視化
せっかくなので、試合数と勝率を可視化してみます。
list_match_count = []
list_win_rate = []
for player in list_target_player:
cnt_win = len(df_male_win_lose[df_male_win_lose['winner'] == player])
cnt_lose = len(df_male_win_lose[df_male_win_lose['loser'] == player])
list_match_count.append(cnt_win+cnt_lose)
list_win_rate.append(cnt_win/(cnt_win+cnt_lose))
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
font_path = "./font/NotoSansMonoCJKjp-Regular.otf"
font_prop = FontProperties(fname=font_path)
fig, axs = plt.subplots(ncols=2, figsize=(15, 5))
axs[0].bar(x=list_target_player, height=list_match_count, color='b', alpha=0.5)
axs[0].set(xlabel='player', ylabel='cnt')
for tick in axs[0].get_xticklabels():
tick.set_rotation(90)
tick.set_font_properties(font_prop)
axs[1].bar(x=list_target_player, height=list_win_rate, color='r', alpha=0.5)
axs[1].set(xlabel='player', ylabel='rate')
for tick in axs[1].get_xticklabels():
tick.set_rotation(90)
tick.set_font_properties(font_prop)
plt.show()
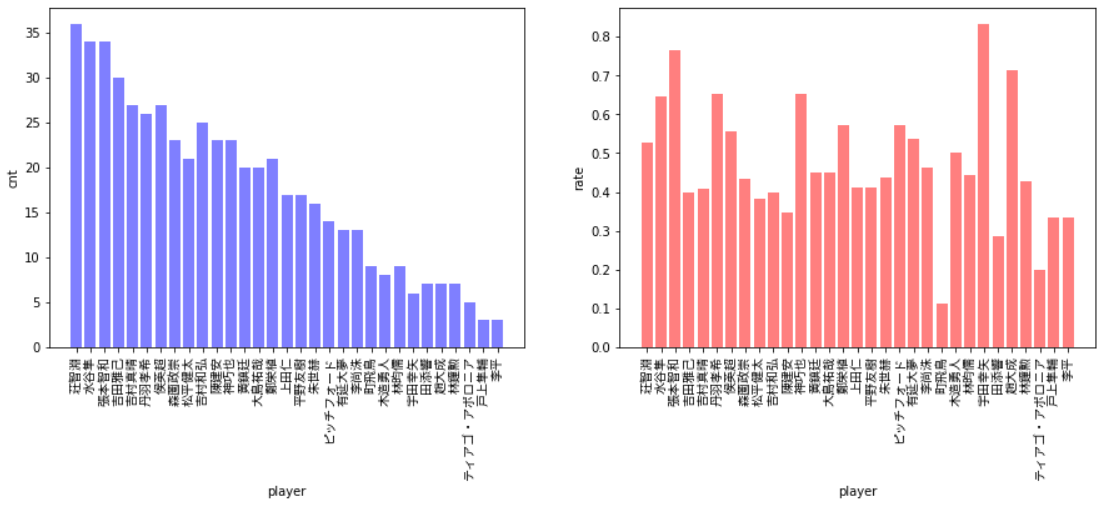
選んだ選手同士での試合のみを抽出しているので、先ほどの試合数とは若干異なります。2020年全日本王者の宇田幸矢選手の勝率が凄いことになってますね。
実装
Stan用データ整形
まずは選手ごとにIDを振っていきます。
dic_target_player = {}
for player in list_target_player:
if player not in dic_target_player:
dic_target_player[player] = len(dic_target_player)+1
dic_target_player
{'荘智淵': 1,
'水谷隼': 2,
'張本智和': 3,
'吉田雅己': 4,
'吉村真晴': 5,
'丹羽孝希': 6,
'侯英超': 7,
'森薗政崇': 8,
'松平健太': 9,
'吉村和弘': 10,
'陳建安': 11,
'神巧也': 12,
'黄鎮廷': 13,
'大島祐哉': 14,
'鄭栄植': 15,
'上田仁': 16,
'平野友樹': 17,
'朱世赫': 18,
'ピッチフォード': 19,
'有延大夢': 20,
'李尚洙': 21,
'町飛鳥': 22,
'木造勇人': 23,
'林昀儒': 24,
'宇田幸矢': 25,
'田添響': 26,
'趙大成': 27,
'林鐘勲': 28,
'ティアゴ・アポロニア': 29,
'戸上隼輔': 30,
'李平': 31}
LoserとWinnerにのペア情報をIDに変えていきます。
LW = []
for player_a in list_target_player:
for player_b in list_target_player:
df_tmp = df_male_win_lose[
(df_male_win_lose['winner'] == player_a) &
(df_male_win_lose['loser'] == player_b)
]
for _ in range(len(df_tmp)):
LW.append([dic_target_player[player_b], dic_target_player[player_a]])
df_tmp = df_male_win_lose[
(df_male_win_lose['winner'] == player_b) &
(df_male_win_lose['loser'] == player_a)
]
for _ in range(len(df_tmp)):
LW.append([dic_target_player[player_a], dic_target_player[player_b]])
LW = np.array(LW, dtype=np.int32)
上位10個はこんな感じ。負け選手IDと勝ち選手IDの順に、試合ごとに格納されています。
LW[:10]
array([[1, 2],
[3, 1],
[1, 3],
[4, 1],
[4, 1],
[5, 1],
[1, 5],
[7, 1],
[7, 1],
[1, 7]], dtype=int32)
モデリング
アヒル本の写経…。
import pystan
model = """
data {
int N;
int G;
int<lower=1, upper=N> LW[G, 2];
}
parameters {
ordered[2] performance[G];
vector<lower=0>[N] mu;
real<lower=0> s_mu;
vector<lower=0>[N] s_pf;
}
model {
for (g in 1:G)
for (i in 1:2)
performance[g, i] ~ normal(mu[LW[g, i]], s_pf[LW[g, i]]);
mu ~ normal(0, s_mu);
s_pf ~ gamma(10, 10);
}
"""
fit1 = pystan.stan(model_code=model, data={'N': len(dic_target_player), 'G': len(LW), 'LW': LW}, iter=1000, chains=4)
la1 = fit1.extract()
ordered[2] performance[G]が今回の肝で、$performance[g,1]$が $performance[g,2]$より小さいということを表現しています。
回してみる
15分くらいで、結果が出てきました。
fit1
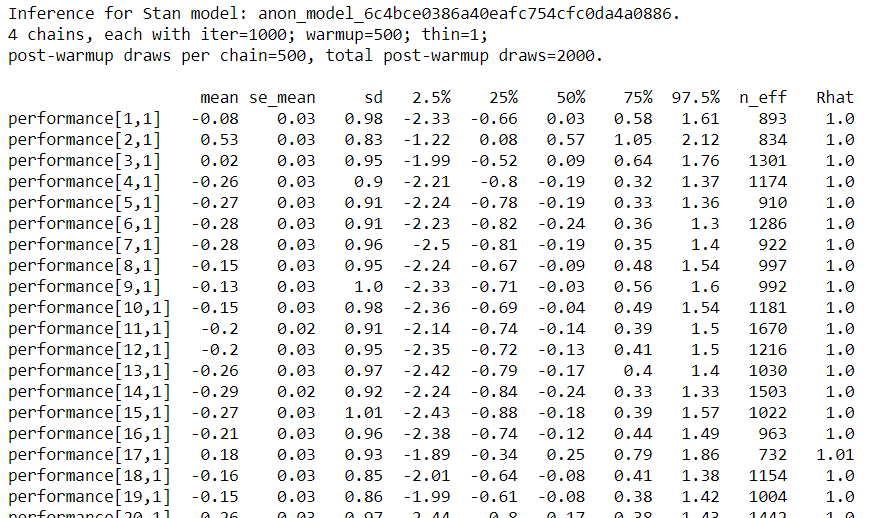
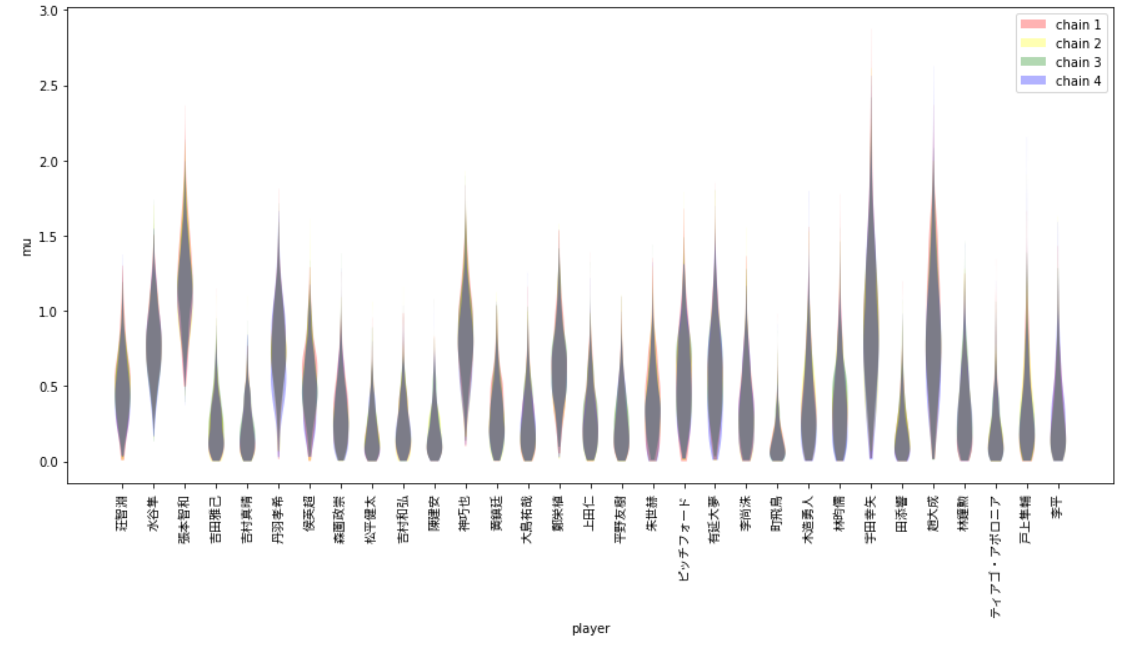
ざっと見た感じ、Rhatがおおよそ1.0付近になっています。念のための各chainごとのサンプリング結果をプロット(ここからは、テニス選手の分析記事の写経です)。まずは$\mu[n]$。
plt.figure(figsize=(15,7))
colors = ['red', 'yellow', 'green', 'blue']
for i, player in enumerate(list_target_player):
for j in range(4):
g = plt.violinplot(la1['mu'][j*500:(j+1)*500, i], positions=[i], showmeans=False, showextrema=False, showmedians=False)
for pc in g['bodies']:
pc.set_facecolor(colors[j])
plt.legend(['chain 1', 'chain 2', 'chain 3', 'chain 4'])
plt.xticks(list(range(len(list_target_player))), list_target_player)
plt.xticks(rotation=90, fontproperties=font_prop)
plt.xlabel('player')
plt.ylabel('mu')
plt.show()
次に$\sigma[n]$。
plt.figure(figsize=(15,7))
colors = ['red', 'yellow', 'green', 'blue']
for i, player in enumerate(list_target_player):
for j in range(4):
g = plt.violinplot(la1['s_pf'][j*500:(j+1)*500, i], positions=[i], showmeans=False, showextrema=False, showmedians=False)
for pc in g['bodies']:
pc.set_facecolor(colors[j])
plt.legend(['chain 1', 'chain 2', 'chain 3', 'chain 4'])
plt.xticks(list(range(len(list_target_player))), list_target_player)
plt.xticks(rotation=90, fontproperties=font_prop)
plt.xlabel('player')
plt.ylabel('s_pf')
plt.show()
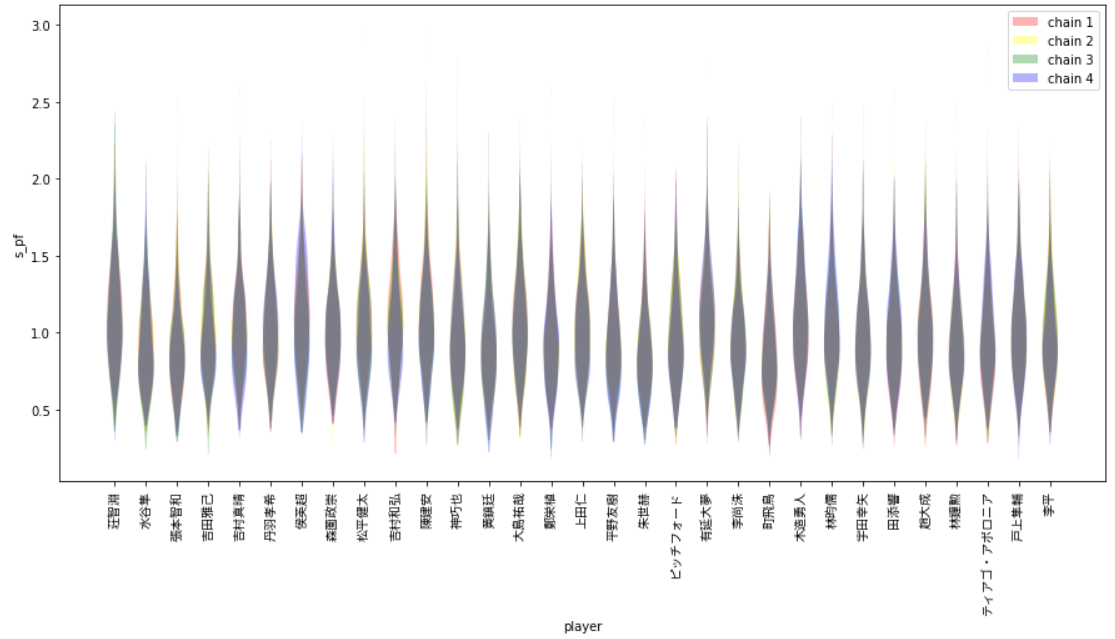
まあ、悪くない結果。それなりに収束してそう。
結果
各選手のパフォーマンス
まずは選手のパフォーマンス結果を見ていきます。ベイズモデリングの結果の1%、10%、25%、メディアン、75%、90%、99%、標準偏差を抽出して、メディアンの大きい順に並べていきます。最初の関数は結果の表を色付けするやつみたいです。
from matplotlib.colors import LinearSegmentedColormap
def generate_cmap(colors):
values = range(len(colors))
vmax = np.ceil(np.max(values))
color_list = []
for v, c in zip(values, colors):
color_list.append(( v / vmax, c))
return LinearSegmentedColormap.from_list('custom_cmap', color_list)
cm = generate_cmap(['white', 'violet'])
summary = np.zeros((len(list_target_player), 8))
for i, player in enumerate(list_target_player):
samples = la1['mu'][:, i]
median = np.median(samples, axis=0)
std = np.std(samples, ddof=1)
lllower, llower, lower, upper, uupper, uuupper = np.percentile(samples, q=[1.0, 10.0, 25.0, 75.0, 90.0, 99.0], axis=0)
summary[i] = [lllower, llower, lower, median, upper, uupper, uuupper, std]
summary = pd.DataFrame(summary, index=list_target_player, columns=['1%', '10%', '25%', 'median', '75%', '90%', '99%', 'std'])
summary.sort_values("median", ascending=False).style.background_gradient(cmap=cm, axis=0)

これを可視化したのがこちら。
plt.figure(figsize=(15,7))
cmap = plt.cm.get_cmap('tab10')
for i, player in enumerate(list_target_player):
g = plt.violinplot(la1['mu'][:, i], positions=[i], showmeans=False, showextrema=True, showmedians=True)
c = cmap(i%10)
for pc in g['bodies']:
pc.set_facecolor(c)
g['cbars'].set_edgecolor(c)
g['cmaxes'].set_edgecolor(c)
g['cmedians'].set_edgecolor(c)
g['cmins'].set_edgecolor(c)
plt.xticks(list(range(len(list_target_player))), list_target_player)
plt.xticks(rotation=90, fontproperties=font_prop)
plt.xlabel('player')
plt.ylabel('latent strength')
plt.show()
メディアンをみると、世界ランク3位まで上り詰めたことのある張本智和選手1強!一人だけ、とびぬけていますね。しかし、上振れ幅を考えると、宇田幸矢選手、趙大成選手も負けていません。ちなみに、趙大成選手は、長年韓国を引っ張ってきた李尚洙と鄭栄植、そして張禹珍に続く、韓国の新星です。
そして、リオオリンピックに出場した水谷隼選手、丹羽孝希選手、鄭栄植選手を抑えて4位にランクインしたのは神巧也選手!さすがは、 2019-2020シーズン後期MVPを獲っただけのことはありますね。ガッツあふれるプレーが大好きな選手です。
各選手のムラ
cm = generate_cmap(['white', 'violet'])
summary = np.zeros((len(list_target_player), 8))
for i, player in enumerate(list_target_player):
samples = la1['s_pf'][:, i]
median = np.median(samples, axis=0)
std = np.std(samples, ddof=1)
lllower, llower, lower, upper, uupper, uuupper = np.percentile(samples, q=[1.0, 10.0, 25.0, 75.0, 90.0, 99.0], axis=0)
summary[i] = [lllower, llower, lower, median, upper, uupper, uuupper, std]
summary = pd.DataFrame(summary, index=list_target_player, columns=['1%', '10%', '25%', 'median', '75%', '90%', '99%', 'std'])
summary.sort_values("median", ascending=False).style.background_gradient(cmap=cm, axis=0)

plt.figure(figsize=(15,7))
cmap = plt.cm.get_cmap('tab10')
for i, player in enumerate(list_target_player):
g = plt.violinplot(la1['s_pf'][:, i], positions=[i], showmeans=False, showextrema=True, showmedians=True)
c = cmap(i%10)
for pc in g['bodies']:
pc.set_facecolor(c)
g['cbars'].set_edgecolor(c)
g['cmaxes'].set_edgecolor(c)
g['cmedians'].set_edgecolor(c)
g['cmins'].set_edgecolor(c)
plt.xticks(list(range(len(list_target_player))), list_target_player)
plt.xticks(rotation=90, fontproperties=font_prop)
plt.xlabel('player')
plt.ylabel('uneven performance')
plt.show()
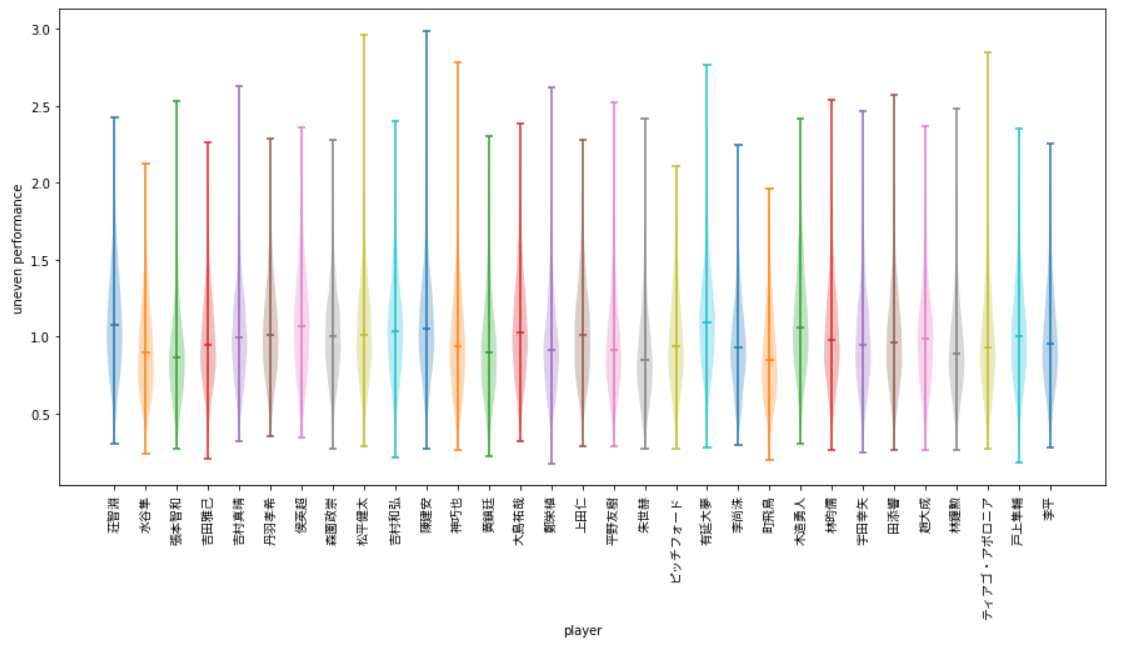
試合数が少なすぎるのか、あまり差が目立ちませんが、目に留まるとすると、水谷選手と張本選手のムラが小さいということでしょうか。
あとは、個人的に安定して勝っていそうな荘智淵選手、侯英超選手のムラが大きいのには少し驚きました。
データが不十分?
と、ここまでTリーグ所属選手のパフォーマンスとムラを見てきましたが、もっと差が出てもいいのかなというのが直感でした。試しに各選手の勝ち負けを可視化してみました(写経です)。
cm = generate_cmap(['white', 'violet'])
df_tmp = df_male_win_lose[
(df_male_win_lose['winner'].isin(list_target_player)) &
(df_male_win_lose['loser'].isin(list_target_player))
]
summary = np.zeros((len(list_target_player), len(list_target_player)), dtype=np.int32)
for i in range(len(list_target_player)):
for j in range(i+1, len(list_target_player)):
summary[i, j] = len(df_tmp[
(df_tmp['winner'] == list_target_player[i]) &
(df_tmp['loser'] == list_target_player[j])
])
summary[j, i] = len(df_tmp[
(df_tmp['loser'] == list_target_player[i]) &
(df_tmp['winner'] == list_target_player[j])
])
fig, axs = plt.subplots(figsize=(9, 9))
im = axs.imshow(summary, cmap=cm, interpolation='nearest')
axs.grid(False)
axs.set_xticks(list(range(len(list_target_player))))
axs.set_yticks(list(range(len(list_target_player))))
axs.set_xticklabels(list_target_player, fontproperties=font_prop)
axs.set_yticklabels(list_target_player, fontproperties=font_prop)
axs.set_ylabel('winner')
axs.set_xlabel('loser')
for tick in axs.get_xticklabels():
tick.set_rotation(90)
tick.set_font_properties(font_prop)
for i in range(len(list_target_player)):
for j in range(len(list_target_player)):
text = axs.text(j, i, summary[i, j], ha='center', va='center', color='black')
fig.tight_layout()
plt.show()
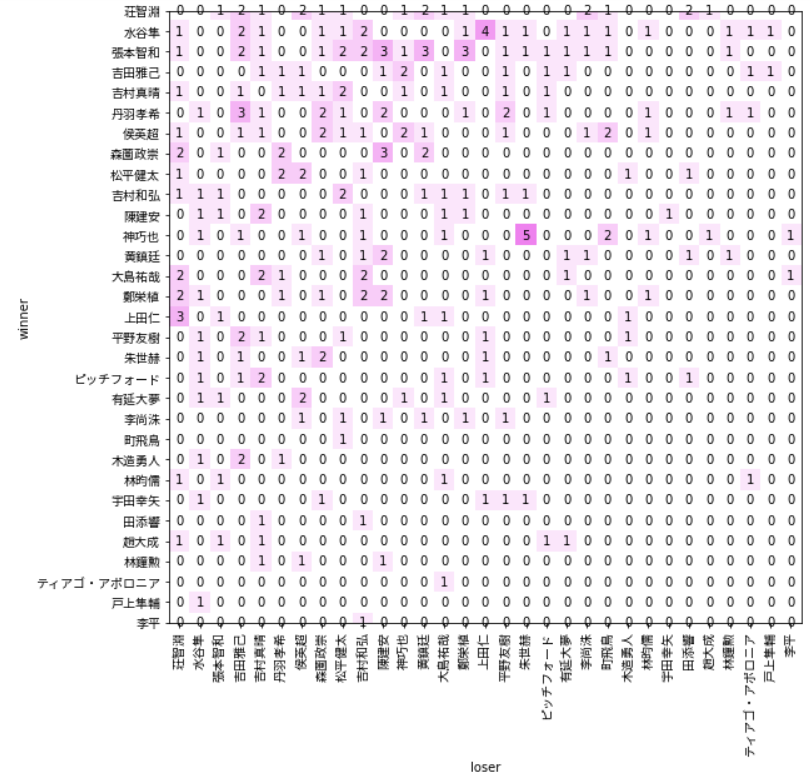
神選手、朱世赫選手に対してやたら強いな…。ではなく、ゼロがいっぱい。
卓球の一ファンとして、卓球分析屋さんの一人として、新型コロナウイルスなんかに負けずに、今後もTリーグが運営されていくことを切に願います。
さいごに
ベイズモデリングを使うと、勝ち負けのデータだけでここまで分析が可能なのかと驚きました。今後も色々と実験していければなと、ワクワクしてきた分析時間でした。
あと、今後のTリーグに期待と上述しましたが、Tリーグには統計データの整備&公表も期待したいところです。今回はデータ収集に一番時間を取られましたので。私みたいな形で日本の卓球を盛り上げていく方法もあるのかなと思っています。