やったこと
架空のお店の売上高のトレンドの推定と、とある期間に行われた広告キャンペーンによってどれくらい売上高が変化したのかを、時変係数動的線形モデルとPystanを用いて推定してみました。もともとは時系列分析と状態空間モデルの基礎: RとStanで学ぶ理論と実装に掲載されていた事例をPystanを使って解いてみようと思ったのがきっかけです。ちなみに、本の中ではRのKFASを使ったソリューションが載っています。
また、一部結果等が見にくいところがありますが、https://github.com/hrkzz/Data_analysis_examples/blob/master/1_Analysing_ad_effects_by_dynamic_linear_model.ipynbにnotebookを公開しているので、必要に応じてご覧ください。
環境
Google Colabを使いました。環境構築の手間を考えると本当に便利ですよね。
ライブラリのインポート
# 基本ライブラリ
import numpy as np
import pandas as pd
# 図形描画ライブラリ
import matplotlib.pyplot as plt
import seaborn as sns
plt.style.use('seaborn-darkgrid')
from matplotlib.pylab import rcParams
# 統計ライブラリ
import pystan
シミュレーションデータ
# サンプルサイズ
N = 450
# 乱数固定
np.random.seed(10)
# 時間によって変化する広告効果
true_reg_coef = -np.log(np.arange(1,51))*2+10
# ランダムウォークする水準値(トレンド)
mu = np.cumsum(np.random.normal(loc=0, scale=0.5, size=N)) + 25
# 状態方程式
x = mu + np.concatenate((np.repeat(0,200),true_reg_coef, np.repeat(0,200)))
# 観測誤差
obs_error = np.random.normal(loc=0, scale=2, size=N)
# 観測値(広告効果が入った売上データ)
sales_ad = x + obs_error
# 説明変数(1なら広告あり)
dummy_ad = np.zeros(N)
dummy_ad[201:251] = 1
# データフレームで整理
data = pd.DataFrame(dict(sales_ad=sales_ad, dummy_ad=dummy_ad))
data.head()
| sales_ad | dummy_ad | |
|---|---|---|
| 0 | 22.834287 | 0.0 |
| 1 | 26.212849 | 0.0 |
| 2 | 25.638334 | 0.0 |
| 3 | 26.333011 | 0.0 |
| 4 | 25.669880 | 0.0 |
図示
rcParams['figure.figsize'] = 15,4
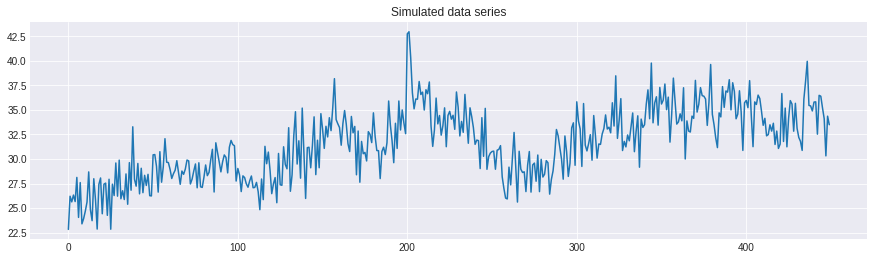
plt.plot(data.sales_ad)
plt.title('Simulated data series')
plt.show()
rcParams['figure.figsize'] = 15,4
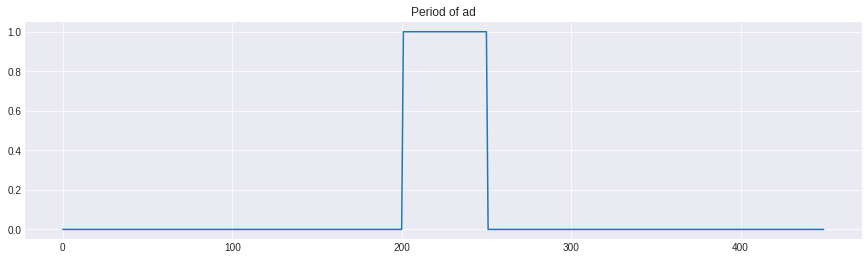
plt.plot(data.dummy_ad)
plt.title('Period of ad')
plt.show()
rcParams['figure.figsize'] = 15,4
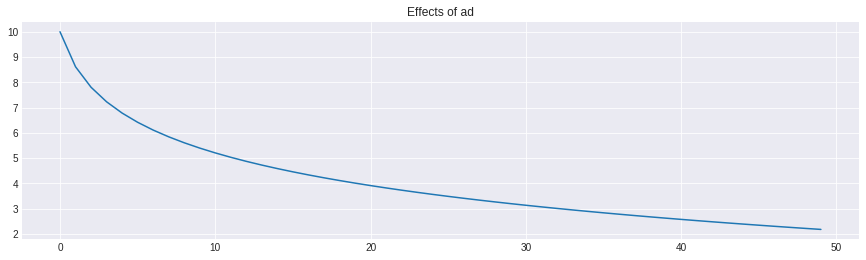
plt.plot(true_reg_coef)
plt.title('Effects of ad')
plt.show()
モデリング
状態空間モデルを使って推定を行っていきたいと思います。このモデルでは、回帰係数が時間よって変化する時変係数のモデリングが可能となっていて、時間とともにその効果が薄れていくことを表現することが可能です。
状態空間モデルのローカルレベルモデルに、広告効果に関する時変の説明変数を付け加えた、以下のモデルを使っていきます。広告効果のダミー変数の係数の右下に$t$と付けていますが、これが時変係数を表しています。
\begin{align}
\beta_t &= \beta_{t-1} + a_t&a_t \sim Normal(0,\sigma^2_a) \\
\mu_t &= \mu_{t-1} + w_t &w_t \sim Normal(0,\sigma^2_w) \\
y_t &= \mu_t + a_t*dummy\_ad_t+v_t &v_t \sim Normal(0,\sigma^2_v)
\end{align}
これを別の書き方にすると、
\begin{align}
\beta_t &\sim Normal(\beta_{t-1},\sigma^2_a) \\
\mu_t &\sim Normal(\mu_{t-1},\sigma^2_w) \\
y_t &\sim Normal(\mu_t + a_t*dummy\_ad_t,\sigma^2_v)
\end{align}
Stanの実装
Stanの式は次のとおり。なお、Stanでは事前分布を指定しないと自動的に制限された範囲内で十分に幅の広い一様分布が使われるようです。
Effect_ad_model = '''
data{
int<lower=0> N;
real<lower=0> sales_ad[N];
real<lower=0, upper=1> dummy_ad[N];
}
parameters{
real<lower=0> s_a;
real<lower=0> s_w;
real<lower=0> s_v;
real beta_zero;
real beta[N];
real mu_zero;
real mu[N];
}
model{
beta[1] ~ normal(beta_zero, s_a);
for(i in 2:N)
beta[i] ~ normal(beta[i-1], s_a);
mu[1] ~ normal(mu_zero, s_w);
for(i in 2:N)
mu[i] ~ normal(mu[i-1], s_w);
for(i in 1:N)
sales_ad[i] ~ normal(mu[i] + beta[i]*dummy_ad[i], s_v);
}
'''
上記のstanファイルを直接読み込んでもいいのですが、コンパイルと乱数発生を別にして、乱数発生を色々試したかったので、外からstanファイルを読み込むことにします。読み込み方はGoogle Colab流です。
from google.colab import files
uploaded = files.upload()
Effect_ad_model.stan(n/a) - 475 bytes, last modified: 02/05/2019 - 100% done
Saving Effect_ad_model.stan to Effect_ad_model.stan
まずはstanファイルのコンパイル。
stanmodel = pystan.StanModel(file='Effect_ad_model.stan')
INFO:pystan:COMPILING THE C++ CODE FOR MODEL anon_model_f35367349717199a1e7e29d1b7953b86 NOW.
データをstanに優しい形式にして、実行。BUGSなどのほかのパッケージに比べてStanはMCMCの自己相関が低いらしく、thinは1でも問題ないことが多いらしいですが、今回はthinを2にしておきます。
data_stan = dict(N=N, sales_ad=data.sales_ad, dummy_ad=data.dummy_ad)
fit = stanmodel.sampling(data=data_stan, iter=2000, warmup=500, chains=4, thin=2, seed=1, n_jobs=-1)
推定結果の解釈
1行目はモデルのファイル名
2行目にはMCMCのchain数、iterationのステップ数、warmupのステップ数、thinningのステップ数が表示。今回はデフォルトの設定。MCMCのサンプルの長さは
\frac{chains*(iterations - warmup)}{thinning}
になるので、今回は3000となります。
meanはMCMCのサンプルの平均値で事後平均。se_meanはmeanの標準誤差。sdは標準偏差。2.5%~97.5%はそれぞれの分位点。n_effはStanが自己相関等あkら判断した実効的なMCMCサンプル数。著者によると100くらいが望ましいです。RhatはMCMCの収束の判断のひとつ。1.1以下だと収束とみなせます。
今回はn-effはだいたい十分で、Rhatを見ると、うまく収束しているようです。
print(fit)
Inference for Stan model: anon_model_883d422f9f425c3ce85e7b9851134b2f.
4 chains, each with iter=2000; warmup=500; thin=2;
post-warmup draws per chain=750, total post-warmup draws=3000.
| mean | se_mean | sd | 2.5% | 25% | 50% | 75% | 97.5% | n_eff | Rhat | |
|---|---|---|---|---|---|---|---|---|---|---|
| s_a | 0.48 | 0.11 | 0.27 | 0.08 | 0.25 | 0.47 | 0.68 | 1.0 | 6 | 1.44 |
| s_w | 0.45 | 7.2e-3 | 0.07 | 0.33 | 0.4 | 0.44 | 0.49 | 0.61 | 99 | 1.06 |
| s_v | 1.87 | 2.0e-3 | 0.07 | 1.73 | 1.82 | 1.87 | 1.92 | 2.02 | 1313 | 1.0 |
残りの結果は長いので省略。
s_wの真の値が0.5、s_vの真の値が2なので、なかなかいい推定結果に。
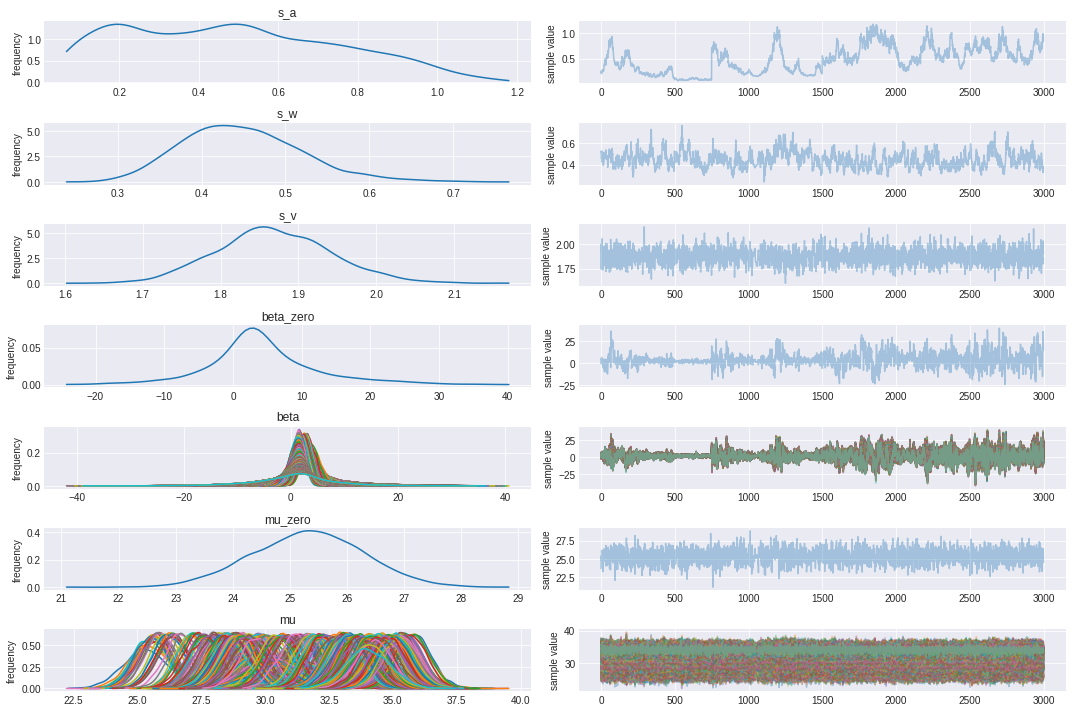
Traceplot
Traceplotでも収束具合を確認
rcParams['figure.figsize'] = 15, 10
fit.plot()
plt.show()
推定結果の図示
# 結果を抽出
ms = fit.extract()
# muの事後平均を算出
mu_mean = ms['mu'].mean(axis=0)
# 広告効果の回帰係数の事後平均を算出
beta_mean = ms['beta'].mean(axis=0)
# 広告効果を算出
ad_effects = beta_mean*data.dummy_ad
# 95パーセンタイルを抽出
mu_5 = np.array(pd.DataFrame(ms['mu']).apply(lambda x: np.percentile(x, 5), axis=0))
mu_95 = np.array(pd.DataFrame(ms['mu']).apply(lambda x: np.percentile(x, 95), axis=0))
beta_5 = np.array(pd.DataFrame(ms['beta']).apply(lambda x: np.percentile(x, 5), axis=0))
beta_95 = np.array(pd.DataFrame(ms['beta']).apply(lambda x: np.percentile(x, 95), axis=0))
ad_effects5 = beta_5*data.dummy_ad
ad_effects95 = beta_95*data.dummy_ad
# x軸
X = data.index
トレンドの推定
rcParams['figure.figsize'] = 15, 5
plt.plot(X, data.sales_ad, label='observed')
plt.plot(X, mu, label='true trend', c='green')
plt.plot(X, mu_mean, label='predicted trend', c='red')
plt.fill_between(X, mu_5, mu_95, color='red', alpha=0.2)
plt.legend(loc='upper left', borderaxespad=0, fontsize=15)
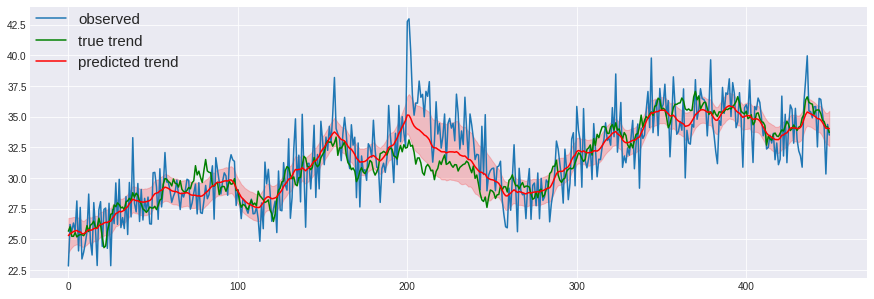
広告期間のところだけ、観測値より低く推定が出来ています。
広告効果の推定
rcParams['figure.figsize'] = 15, 5
plt.plot(X, np.concatenate((np.repeat(0,200),true_reg_coef, np.repeat(0,200))), label='true effects', c='green')
plt.plot(X, ad_effects, label='predicted effects', c='red')
plt.fill_between(X, ad_effects5, ad_effects95, color='red', alpha=0.2)
plt.legend(loc='upper left', borderaxespad=0, fontsize=15)
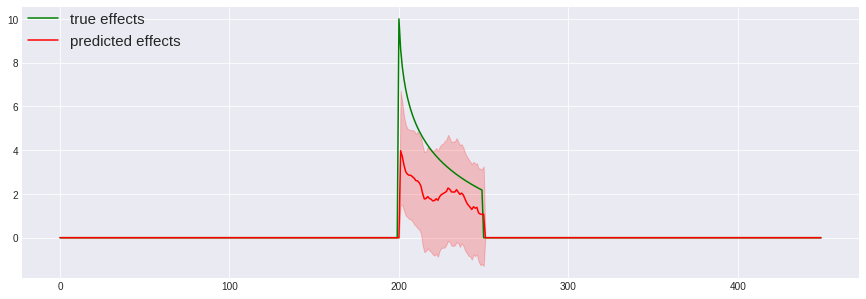
# 広告期間のみにフォーカス
rcParams['figure.figsize'] = 15, 5
plt.plot(X[201:250], np.concatenate((np.repeat(0,200),true_reg_coef, np.repeat(0,200)))[201:250], label='true effects', c='green')
plt.plot(X[201:250], ad_effects[201:250], label='predicted effects', c='red')
plt.fill_between(X[201:250], ad_effects5[201:250], ad_effects95[201:250], color='red', alpha=0.2)
plt.legend(loc='upper right', borderaxespad=0, fontsize=15)
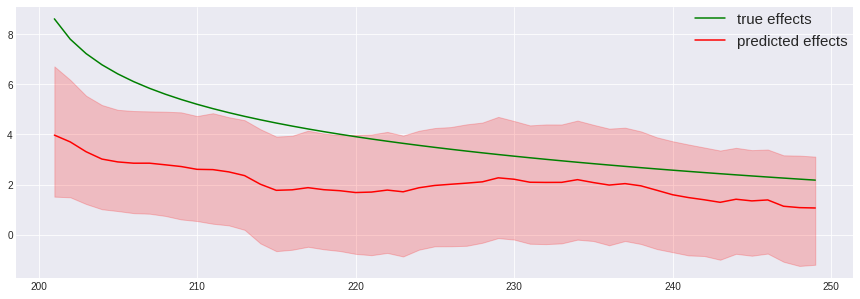
右肩下がりは示せていますが、事後平均は真の効果の半分くらいになってますね。
rcParams['figure.figsize'] = 15, 5
plt.plot(X, data.sales_ad, label='observed')
plt.plot(X, mu_mean+ad_effects, label='predicted trend + predicted ad effects', c='magenta')
plt.plot(X, mu_mean, label='predicted trend', c='red')
# plt.fill_between(X, mu_5, mu_95, color='red', alpha=0.2)
plt.legend(loc='upper left', borderaxespad=0, fontsize=15)
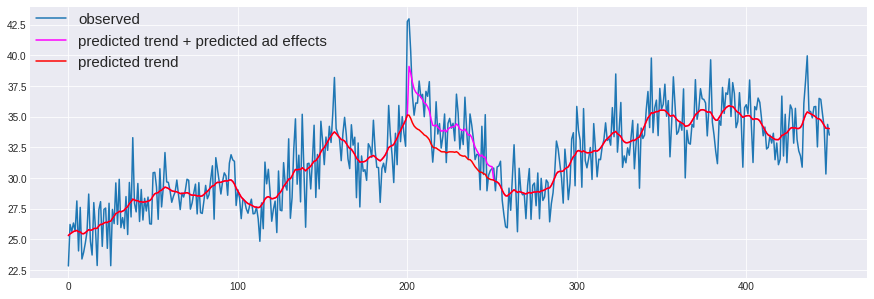
トレンドと広告効果を含めるとうまく、表現できている気がします。
おわりに
以上、走り書きのようにコードを書いて、stanを回して、という感じで作業をしたので、モデリングを中心に多々不備があると思います。こうやったらいいよという、ご意見があればコメントをお願いします!

