はじめに
本記事は、「ゼロ知識証明の汎用化とzkVM」シリーズのパート3となります。
パート1では、ゼロ知識証明(ZKP: Zero-Knowledge Proof)がプライバシー強化技術(PETs)の一つとして注目され、特に検証可能な計算という側面で汎用的な応用が可能になっている現状について解説しました。パート2では、その汎用性をさらに高める技術として注目されているzkVM(ゼロ知識仮想マシン)の概念、その実現アプローチ、そしてRISC Zeroを例にした基本的なワークフローをご紹介しました。
ゼロ知識証明に関する基本的な説明は、レポート「ゼロ知識証明の現在地〜ブロックチェーンを超えた活用可能性〜(日本総合研究所 先端技術リサーチ)」もご覧いただければ幸いです。
これらの記事を通して、zkVMが既存のプログラミング資産を活用しやすく、ゼロ知識証明をより身近なものにする可能性を秘めていることをお伝えできたかと思います。
では、zkVMは実際にどのような応用が可能で、その性能はどの程度なのでしょうか?
今回のパート3では、著者たちの研究チームがWWW2025(The ACM Web Conference 2025)Short Papers Trackで発表した論文「Generating Privacy-Preserving Personalized Advice with Zero-Knowledge Proofs and LLMs」1の内容をベースに、zkVMを用いた具体的な応用例と、その実用性を評価するために行ったベンチマークの結果について詳しく解説したいと思います。特に、ゼロ知識証明部分であるzkVMの具体的な実装と評価に焦点を当ててご説明します。
LLMベースのアドバイザーとプライバシー問題
近年、ChatGPTに代表される大規模言語モデル(LLM)は、金融、ヘルスケア、対人関係など様々な分野で、ユーザーの特性や状況に合わせたパーソナライズされたアドバイスを提供するチャットボットとして活用が進んでいます。
しかし、より質の高い、ユーザーにとって効果的なアドバイスを行うためには、収入や資産といった金融情報、年齢や病歴といった医療情報 のように、ユーザーの機微な個人データが必要となる場面が多くあります。これにより、重大なプライバシーの懸念が生じています。
多くのチャットボットプラットフォームはプライバシーポリシーを定めていますが、データ収集や利用に関する課題は依然として存在します。GDPRなどの規制で強調されているように、データ最小化の原則、つまり必要最低限のデータのみを扱うことが非常に重要です。
ここで、パート1、パート2で解説したゼロ知識証明(ZKP)技術が有力な解決策として期待されます。ZKPを用いることで、ユーザー自身が持つ特定の情報(例えば、年齢が18歳以上であることや、総資産が一定額を超えること)を、その情報自体を開示することなく証明することが可能になります。これにより、サービス提供側(LLM)は、ユーザーの機微なデータそのものを取得することなく、アドバイスに必要なユーザー特性の「検証可能な証明」を得ることができるようになります。
特に、パート2で紹介したzkVMは、従来のZKPフレームワークでは難しかった複雑な計算や既存のプログラムを比較的容易にゼロ知識証明化できるため、このようなLLMベースのアドバイザーにおけるプライバシー保護への応用が期待されています。
zkVMを活用したプライバシー保護アドバイザーの提案アーキテクチャ概略
私たちの研究で提案しているアーキテクチャの概略は下図(論文より引用)の通りです。
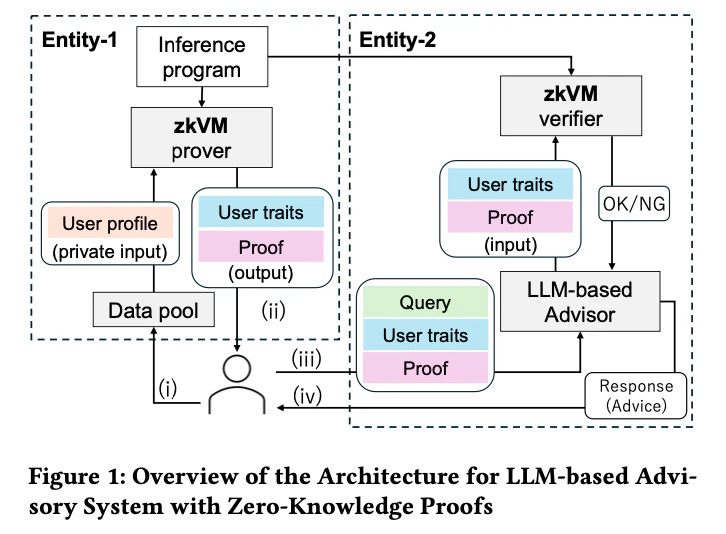
このアーキテクチャは、大きく分けて二つの独立したエンティティから構成されます。
- エンティティ1: ユーザーのプライベートデータを保有する機関(金融機関やヘルスケアプロバイダーなど)を想定。ここでは、zkVM proverとしても機能します。
- エンティティ2: LLMを用いてユーザーにアドバイスを提供するクラウドベースのサービスなどを想定。ここでは、zkVM verifierとしても機能します。
これらのエンティティ間で、ユーザーの機微な個人データ自体が直接共有されることはありません。
ワークフローは以下のようになります:
(i) ユーザーはエンティティ1に対し、自身のプロファイルに基づいた「抽象化されたユーザー特性」の推論を依頼します。
(ii) エンティティ1はユーザーデータを用いてユーザー特性を推論し、その結果と、その推論が正しいことを証明するゼロ知識証明(ZKP)をzkVMを用いて生成し、ユーザーに渡します。
(iii) ユーザーは、エンティティ1から受け取ったユーザー特性とZKP、そしてアドバイスを受けたい内容のクエリをエンティティ2に提供します。
(iv) エンティティ2は受け取ったZKPを検証することで、ユーザー特性がエンティティ1によって正しく推論されたものであることを確認できます。
検証が成功した場合、エンティティ2は確認できたユーザー特性に基づき、LLMを用いてパーソナライズされたアドバイスを生成し、ユーザーに提供します。このアーキテクチャの重要な点は、エンティティ2はユーザーのプライベートなプロファイルデータそのものを知ることなく、エンティティ1によって「正しく推論された」ユーザー特性だけを、ZKPによって検証済みの信頼できる情報として受け取れることです。
zkVMによるユーザー特性推論アプリケーションの実装と評価
私たちは、このアーキテクチャの実現可能性を示すため、具体的なzkVMアプリケーションの実装と評価を行いました。
zkVMで実行するアプリケーションとして、私たちはルールベースのユーザー特性推論ロジックを選択しました。具体的には、全国銀行協会が公開しているリスク許容度診断テストのWebアプリケーションを参考に、ユーザーが10個の金融に関する質問に回答することで、そのリスク許容度を4つのカテゴリ(安全性重視タイプ、安定成長タイプ、バランス運用タイプ、積極運用タイプ)に分類するロジックを対象としました。この分類結果は、ユーザーの金融関連の特性(=上述の抽象化されたユーザー特性)を示す情報となります。
このユーザ特性を算出するためのプロファイルを下記のようなJSONデータ形式で、ZKPアプリケーションに渡しています。
{ //質問に対するユーザの回答が記載されたプロファイル
"questions": [
{
"question": "年収分以上の貯蓄がある。",
"options": {
"ある": 5,
"年収の半分くらいある": 3,
"ない": 1
},
"user_answer": "ある"
},
{
"question": "毎年、年収の2割以上の貯蓄ができている。",
"options": {
"毎年できている": 5,
"毎年ではないが少しできている": 3,
"できていない": 1
},
"user_answer": "毎年できている"
},
///以下省略///
],
//ユーザがどのカテゴリを取り得るかの一覧も記載
"categories": {
"1": {
"name": "安全性重視タイプ",
"description": "預金など、安全な運用法を好む",
"range": [0, 14]
},
"2": {
"name": "安定成長タイプ",
"description": "安全性を好みつつ、お金を増やす方法を考え直したい",
"range": [15, 29]
},
///以下省略///
ルールベースの分類ロジックは、一般的なRustコードとして実装し、これをzkVM上で動作するZKPアプリケーションとして構築します。分類ロジックは、上記プロファイルから"user_answer"の回答に応じて、"options"で割り振られたスコアを加算し、合計スコアによってユーザの特性タイプが決定するという、非常に簡単ものです。
今回はJSONデータ内に、ユーザがどのようなカテゴリになり得るかも記載することにしました(合計スコアが0-14点は"安全性重視タイプ"、15-29点は"安定成長タイプ"など、"categories"の項目を参照)JSONデータ側にカテゴリ情報を持つことによって、スコアリングによってタイプを分類するユースケースに対して、同一のゲストコードで汎用的に対応できます。
パート2で解説したzkVMのワークフローに従い、ゲストコード(推論ロジック)とホストコード(zkVMの制御、入出力処理)を実装しました。zkVMでは、安全なゲストコードの実装が重要になるため、今回の推論ロジックを実装したゲストコードについて解説します。
// RISC Zeroのゲストコード例(抜粋)
fn main() {
// 1. zkVMからの入力データ(JSON)読み込み
let data: String = env::read();
// 2. 入力JSONスキーマのハッシュを計算(注:user_answerを除外)
let input_hash = calculate_hash(&data);
// 3. JSONデータをパース
let questions: Questions = serde_json::from_str(&data).expect("Invalid JSON format");
let mut score = 0;
// 4. 回答の検証とスコア計算
for question in &questions.questions {
if validate_answer(question) {
if let Some(points) = question.options.get(&question.user_answer) {
score += points;
}
}
}
// 5. スコアに基づくカテゴリー分類
let mut output = Outputs { /* 初期化コード(省略) */ };
for category in questions.categories.values() {
if score >= category.range[0] && score <= category.range[1] {
output.category = category.name.clone();
output.description = category.description.clone();
output.input_hash = input_hash;
break;
}
}
// 6. 結果をコミット
env::commit(&output);
}
上記のゲストコードの流れは以下の通りです。
-
JSON形式の入力データを読み込む
-
入力JSONからハッシュ値を計算(JSONスキーマ検証のため
user_answerフィールドを除外) -
JSON形式でのユーザー回答をパース
-
各回答の検証とスコア計算
-
スコアに基づくカテゴリー分類
-
結果(カテゴリー、説明、入力ハッシュ)をコミット
ゲストコードの入力は、先ほどの「JSONデータ」で、出力は「カテゴリー/(カテゴリーの)説明/入力ハッシュ」の3つです。
zkVMの証明スキームからみると、ユーザープロファイルはJSON形式のプライベート入力としてzkVMに渡されます。zkVM内でルールベースの推論が実行され、推論されたカテゴリ/説明/入力ハッシュが公開出力(RISC Zero用語でいうジャーナル)としてコミットされ、その実行に対するZKP(RISC Zero用語でいうシール)が生成されます。
検証者に対しては、「カテゴリ/説明/入力ハッシュ」が公開され、その他の情報(ユーザが何の回答を選んだか,スコアの合計値など)は開示することなくゼロ知識証明によってカテゴリが正しく分類されていることを検証できるようになります。
JSONスキーマ検証と整合性保証
実装の中で少し注意したいところは、JSONスキーマについてハッシュ値を取り、これも出力としてコミットしているところです。
fn calculate_hash(data: &str) -> String {
// JSONデータをパース
let mut json: Value = serde_json::from_str(data).expect("Invalid JSON");
// 'user_answer'フィールドを削除
remove_user_answers(&mut json);
// JSONをソートされたマップに変換
let sorted_map: BTreeMap<String, Value> = serde_json::from_value(json).unwrap_or_default();
// キーと値を連結して文字列を作成
let combined_string = sorted_map.iter()
.map(|(k, v)| format!("{}:{}", k, v))
.collect::<Vec<String>>()
.join("");
// ハッシュを計算
let mut hasher = Sha256::new();
hasher.update(combined_string);
format!("{:x}", hasher.finalize())
}
あくまでもスキーマに限定してハッシュを取るため,ユーザの回答('user_answer')はremove_user_answers関数で、取り除くようにしています。なぜこのようにユーザの回答を取り除いて、ハッシュ値をコミットする必要があるのでしょうか?
特に、次の3つについて保証するため、このような処理を追加しています。
-
証明者と検証者が同じJSONフォーマット(質問構造、選択肢、配点など)を使用していることを検証
-
入力データの構造やルールセットの改ざんを防止
-
異なるバージョンのフォーマットを識別可能
この「フォーマット検証」は、このシステムの信頼性において非常に重要です。ハッシュに含まれる情報(user_answerを除く部分)により、証明者と検証者の間で「評価ルール」についての合意が取れていることが保証されます。(検証者が想定するJSONスキーマを証明者も受け取っているかを保証する)これにより、例えば証明者が勝手に配点やカテゴリー分類の条件を変更するといった不正を防止できます。
実用性の評価(ベンチマーク)
zkVMフレームワークとしては、パート1、パート2でも触れたRISC Zero と SP1 (Succinct Labs) を採用しました。これらのzkVMは、既存のRustコードを比較的容易にZKPアプリケーションに変換できる点 や、ローカル環境での実行が可能でブロックチェーンに依存しない実装を選択できる点 から、今回の用途に適していました。二つのフレームワークの対して、ほぼ同一のRustコードを再利用して推論ロジックを動作させることができました。
評価では、40個のサンプルユーザープロファイル(質問への回答セット)に対して、zkVM上での証明生成時間と検証時間を計測しました。得られたベンチマーク結果の一部を、論文より引用した下表に示します。
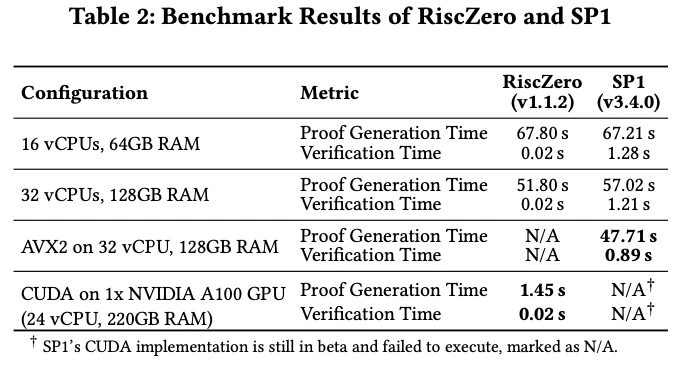
結果が示すように、CPUベースでの証明生成には数十秒程度の時間を要しました。ゼロ知識証明の生成は計算コストが高いことで知られています。しかし、LLMベースのチャットボットのようなリアルタイム性が求められるアプリケーションにおいては、検証時間の方が重要となります。ベンチマーク結果を見ると、検証時間はRISC Zeroで0.02秒、SP1でも1秒台と非常に短く、この要件は十分に満たせる実用的なレベルにあることが確認できました。
さらに注目すべきは、RISC ZeroがGPUを活用した場合、証明生成時間が1.45秒と大幅に短縮された点です。これにより、ユーザー側が自身のデバイスで証明を生成してサービス提供側(エンティティ2)に提出するようなシナリオにおいても、ユーザビリティを大きく向上させる可能性が示されました。この実験を通じて、既存のルールベース推論ロジックをzkVMアプリケーションとして実現し、実用的な時間内で証明生成と検証が可能であることを、具体的な性能評価によって示すことができました。
プロンプト戦略の概略(LLM部分について)
本筋のzkVMから話が少し逸れますが、LLM側(エンティティ2)では、zkVMで検証されたユーザー特性(ZKPによって信頼性が保証された特性)をどのように活用して、パーソナライズされた一貫性のあるアドバイスを生成するかが課題となります。私たちは、この課題に対応するためのプロンプト戦略についても検討を行いました。
提案したプロンプト戦略では、ユーザー特性を「ZKPで検証可能な特性」と「検証できない探索的な特性」に分け、LLMへの入力(コンテキスト)において、どちらの特性をより強調するかを調整します。そして、LLMに「推奨アクション」と「その説明」の二つの部分を生成させます。
この戦略の評価では、LLM(GPT-4o, Llama-3.1 405B)が強調されたユーザー特性に応じて推奨アクションを選択できるか、また選択されたアクションに対して一貫した説明を生成できるか を確認しました。
評価結果から、LLMはコンテキストで強調されたユーザー特性に影響を受けて推奨アクションを変化させること、そして多くのケースで推奨アクションと矛盾せず一貫した説明を生成する傾向があることが示されました。ただし、矛盾するコンテキストを与えた場合のモデルの挙動など、更なる詳細な調査が必要な側面も見られました。
このプロンプト戦略は、検証済みのユーザー特性をLLMによるアドバイス生成に効果的に組み込むための一つのアプローチですが、今回の記事ではゼロ知識証明部分に焦点を当てているため、LLM側の評価や戦略の詳細については論文をご参照いただければ幸いです。
おわりに
本シリーズのパート3では、LLMベースのアドバイザーにおけるプライバシー課題に対し、ゼロ知識証明(ZKP)技術、特にzkVMがどのように貢献できるかを具体的に解説しました。
紹介した研究では、zkVMを用いて現実世界の推論ロジックをゼロ知識アプリケーションとして実装できること、そして実用的な時間スケールで証明生成と検証が可能であることを、RISC ZeroとSP1を用いたベンチマークによって示しました。特に、RISC ZeroにおけるGPU活用による証明生成時間の短縮は、ユーザーが証明を生成するシナリオでの実用性を高める上で、今後重要になると思われます。
また、LLM側で検証済みユーザー特性を活用するためのプロンプト戦略についても検討を行いました。
これにより、ユーザーの機微なデータをサービス提供側に開示することなく、データが特定の条件を満たすことだけを証明し、その証明に基づいてLLMがパーソナライズされたアドバイスを生成するという、プライバシー保護とアドバイスのパーソナライズを両立するフレームワークの実現可能性を示すことができました。
本シリーズを通して、ゼロ知識証明技術、特にzkVMが、ブロックチェーン分野を超えて多様なアプリケーション、今回の例で言えばプライバシー保護が重要なLLMサービスにおいて、いかに強力なツールとなりうるかをお伝えできたなら幸いです。
最後までお読みいただき、ありがとうございました。
-
H. Watanabe and M. Uchikoshi, "Generating Privacy-Preserving Personalized Advice with Zero-Knowledge Proofs and LLMs," in Companion Proceedings of the ACM Web Conference 2025 (Short Papers Track) ↩