本稿は ZOZO Advent Calendar 2024 シリーズ7の1日目の記事です
はじめに
AWS Security Hub、使っていますか?
簡単に特徴を列挙すると以下のような機能をもっているサービスです。
- AWS上にあるリソースがセキュリティのベストプラクティスに沿っているかを自動でチェックしてくれる
- 優先順位によって重要度ラベルを振り分けてくれる
- コントロールの合格、失敗に応じてセキュリティスコアを算出してくれる
とりあえず有効化はしているが、きちんとモニタリングできていないという人も多いのではないでしょうか?
弊チームではチケットをGitHub Issueで管理しているため、Security Hubで検出された良くない設定を含むリソースの一覧や修正方法などはGitHub Issueで管理したい思いがありました。
探せばそういった連携ツールはあるかと思っていたのですが、理想とする挙動のツールはどうやらなさそうだったため、自作することにしました。
本稿ではPythonとLambdaを用いてSecurity Hubの検出結果をコントロールID単位でGitHub Issue化する方法について紹介します。
本稿に記載しないこと
- AWSの基礎的な知識やSecurity Hub, Lambda, Pythonなどの詳細な内容や用語の話
- 具体的にどんなコントロールで失敗しているかなどの話
- 実際にチームで運用しているコードそのまま(説明のために簡略化したコードを記載します)
完成系と構成図
以下のようなIssueを作ります。
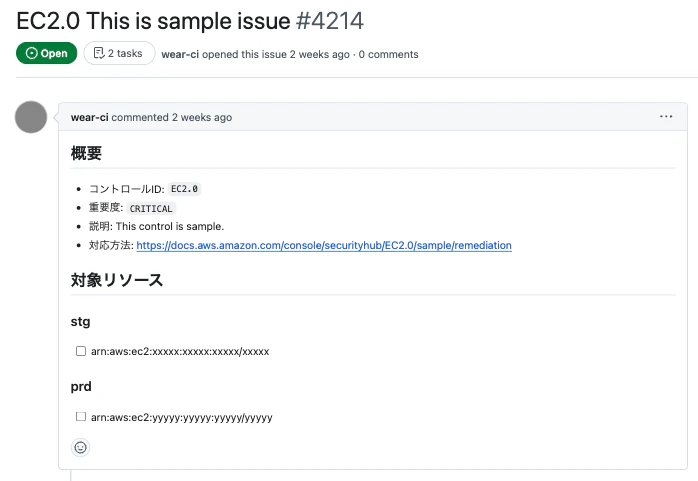
実際の検出結果を出すわけにはいかないのでこれはサンプルです(表示しているコントロールも存在しないIDです)。
コントロールIDごとにIssueを作成し、その中に重要度や内容の説明、対応方法を記載し、stg, prdの各環境で検出されているリソースをそれぞれ一覧化しています。
Issueがオープンなうちに新しくリソースが失敗として検出されたら、各環境の対象リソース欄に自動で追記されていきます。
構成図は以下の通りです。
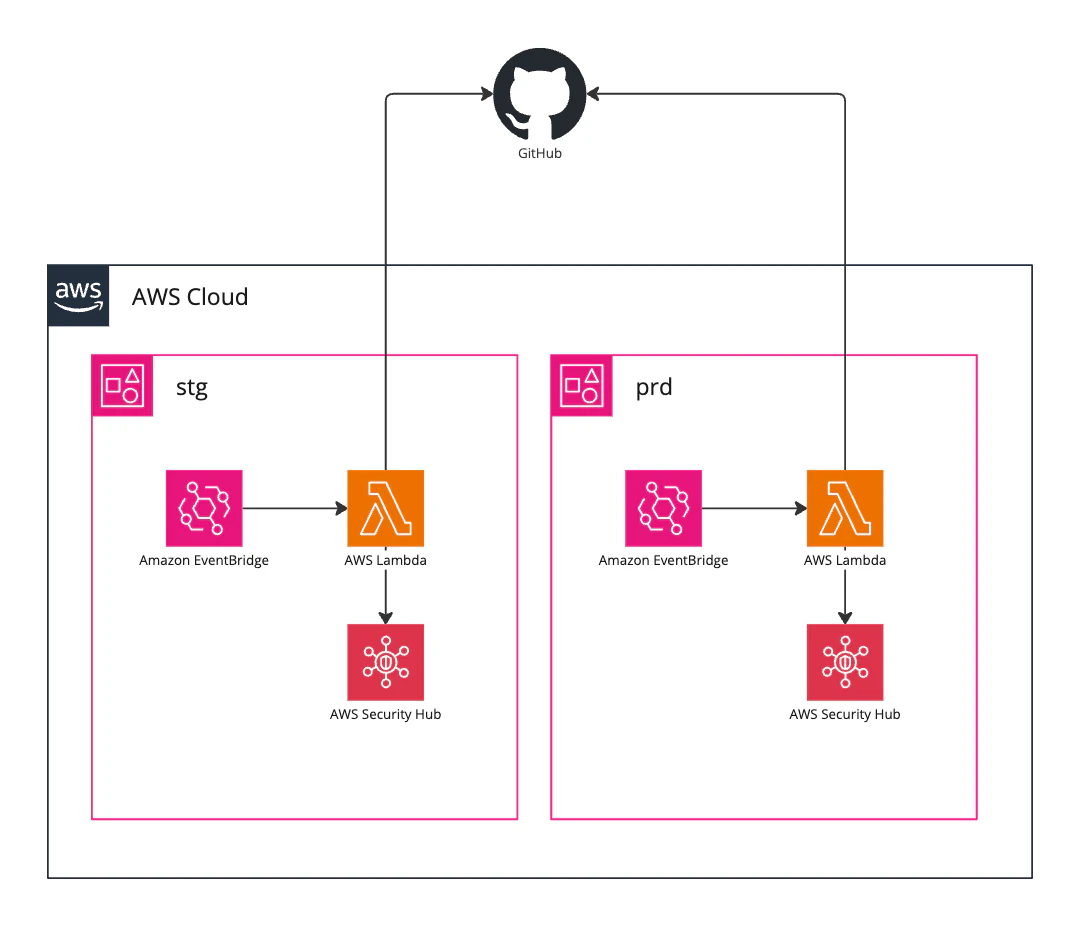
GitHubのトークンを利用するため、実際にこのようなシステムを構築する際は、秘匿情報の管理にAWS Secrets Manager等を利用してください。
本稿では説明の単純化のために省略しています。
stg, prd各アカウントにそれぞれ環境変数を変えたLambdaをデプロイしています。
一つのアカウントにデプロイし、別のアカウントの情報取得や更新を行うことも考えましたが、権限をシンプルに保つためにこのような構成を取りました。
EventBridgeをトリガーにLambdaを1日1回起動し、Issueの新規作成や更新を行います。ここではstgとprdで起動タイミングをずらしています。先に起動している方のアカウントのLambdaでコントロールごとにそれぞれIssueを新規作成し、後に起動した方でIssueのリソース一覧を更新するといった具合です。詳細は解説の章で説明します。
コード
簡略化したコードを以下に記載します。
単純化のためログ出力や例外処理等は省いています。
また、構成図の章にも書きましたが、本来秘匿情報はSecrets Manager等で管理すべきです。今回は簡単のため環境変数に直接入れています。
今回LambdaのデプロイはAWS SAMで行っていますが、他のデプロイ方法でも問題ありません。
コードの解説は次章で行います。
Lambdaのコード
from aws import (
get_securityhub_findings,
group_findings_by_security_control_id,
update_findings_workflow_status,
)
from conf import github_pat
from mygithub import (
close_github,
connect_github,
create_or_update_control_issue,
get_repo,
get_username,
)
def lambda_handler(event, context):
gh = connect_github(github_pat)
repo = get_repo(gh)
creator = get_username(gh)
findings = get_securityhub_findings()
if not findings:
print("No new findings")
return
grouped_findings = group_findings_by_security_control_id(findings)
if not grouped_findings:
print("No new control ids")
return
for grouped_findings_by_control_id in grouped_findings.values():
create_control_issue_and_update_findings_workflow_status(
repo, grouped_findings_by_control_id, creator
)
close_github(gh)
def create_control_issue_and_update_findings_workflow_status(
repo, grouped_findings_by_control_id, creator
):
"""
control_id1つに対してIssueを作成または更新し、FindingsのWorkflowStatusをNOTIFIEDに更新
"""
create_or_update_control_issue(repo, grouped_findings_by_control_id, creator)
update_findings_workflow_status(grouped_findings_by_control_id)
import time
import boto3
securityhub = boto3.client("securityhub")
def get_securityhub_findings():
"""
AWS Security Hubから新規のFindingsを取得
"""
paginator = securityhub.get_paginator("get_findings")
response = paginator.paginate(
Filters={
"WorkflowStatus": [{"Value": "NEW", "Comparison": "EQUALS"}],
"SeverityLabel": [
{"Value": severity, "Comparison": "EQUALS"}
for severity in ["CRITICAL", "HIGH"]
],
}
)
findings = []
for page in response:
findings.extend(page["Findings"])
return findings
def group_findings_by_security_control_id(findings):
"""
FindingsをSecurityControlIdでグループ化。
キーがSecurityControlId、値がFindingsの中で必要な値を抽出したdictを返す
"""
grouped_findings = {}
for finding in findings:
control_id = finding.get("Compliance", {}).get("SecurityControlId")
# Healthイベント等も含まれているため、SecurityControlIdが存在しない場合はスキップ
if not control_id:
continue
if not grouped_findings.get(control_id):
grouped_findings[control_id] = {
"control_id": control_id,
"title": finding["Title"],
"description": finding["Description"],
"severity": finding["Severity"]["Label"],
"remediation_url": finding["Remediation"]["Recommendation"]["Url"],
"resource_ids": [],
"finding_identifiers": [],
}
resource_id = finding["Resources"][0]["Id"]
# AWSアカウントが対象の場合、ARNにリージョンが含まれていないためプレフィックスとしてリージョンを追加
prefix = (
f'{finding["Resources"][0]["Region"]} / '
if finding["Resources"][0]["Type"] == "AwsAccount"
else ""
)
grouped_findings[control_id]["resource_ids"].append(f"{prefix}{resource_id}")
grouped_findings[control_id]["finding_identifiers"].append(
{"Id": finding["Id"], "ProductArn": finding["ProductArn"]}
)
return grouped_findings
def update_findings_workflow_status(grouped_findings_by_control_id, batch_size=100):
"""
FindingsのWorkflowStatusをNOTIFIEDに更新
"""
for i in range(
0, len(grouped_findings_by_control_id["finding_identifiers"]), batch_size
):
batch = grouped_findings_by_control_id["finding_identifiers"][
i : i + batch_size
]
securityhub.batch_update_findings(
FindingIdentifiers=batch, Workflow={"Status": "NOTIFIED"}
)
time.sleep(1)
import github
from conf import repo
from template import create_new_issue_body, create_update_issue_body
def connect_github(github_pat):
"""
GitHubに接続したインスタンスを返す
"""
auth = github.Auth.Token(github_pat)
return github.Github(auth=auth)
def get_repo(gh):
"""
GitHubリポジトリのインスタンスを返す
"""
return gh.get_repo(repo)
def close_github(gh):
"""
GitHubへの接続を閉じる
"""
gh.close()
def get_username(gh):
"""
GITHUB_PATのユーザ名を取得
"""
name = gh.get_user().name
return name
def create_or_update_control_issue(repo, grouped_findings_by_control_id, creator):
"""
control_idに対するIssueを作成または更新
"""
# control_idのラベルがついており、作成者がcreatorに一致するIssueを取得
control_id = grouped_findings_by_control_id["control_id"]
open_issues = list(repo.get_issues(labels=[f"SecurityHub/{control_id}"], creator=creator))
if len(open_issues) > 1:
raise Exception(
f"Multiple open issues found for control_id: {grouped_findings_by_control_id['control_id'], open_issues: {open_issues}}"
)
if len(open_issues) == 0:
# Issueが存在しない場合は新規作成
repo.create_issue(
title=grouped_findings_by_control_id["title"],
body=create_new_issue_body(grouped_findings_by_control_id),
labels=[
"SecurityHub",
f"SecurityHub/{grouped_findings_by_control_id['severity']}",
f"SecurityHub/{grouped_findings_by_control_id['control_id']}",
],
)
return
# Issueが存在する場合は更新
issue = open_issues[0]
body = create_update_issue_body(grouped_findings_by_control_id, issue.body)
issue.edit(body=body)
from jinja2 import Environment, FileSystemLoader
from conf import env_name, insert_mark_message_comment
file_loader = FileSystemLoader("templates")
env = Environment(loader=file_loader)
def create_new_issue_body(grouped_findings_by_control_id):
"""
新規Issueの本文をテンプレートから作成して返す
"""
template = env.get_template("new_issue_template.md")
return template.render(
{
"insert_mark_message_comment": insert_mark_message_comment,
"env_name": env_name,
**grouped_findings_by_control_id,
}
)
def create_update_issue_body(grouped_findings_by_control_id, old_body):
"""
既存Issueの本文の一部をテンプレートで上書きした本文を作成して返す
"""
template = env.get_template("resources.md")
resources_body = template.render(
{
"insert_mark_message_comment": insert_mark_message_comment,
"env_name": env_name,
**grouped_findings_by_control_id,
}
)
return old_body.replace(insert_mark_message_comment[env_name], resources_body)
import os
github_pat = os.environ["GITHUB_PAT"]
env_name = os.environ["ENV_NAME"]
repo = os.environ["GITHUB_REPO"]
insert_mark_message_format = "NOT DELETE:[{env_name}]insert-additional-resources"
insert_mark_message_comment = {
"stg": f"<!-- {insert_mark_message_format.format(env_name='stg')} -->",
"prd": f"<!-- {insert_mark_message_format.format(env_name='prd')} -->",
}
## 概要
- コントロールID: `{{ control_id }}`
- 重要度: `{{ severity }}`
- 説明: {{ description }}
- 対応方法: {{ remediation_url }}
## 対象リソース
### stg
{% if env_name == 'stg' -%}
{% include 'resources.md' %}
{% else -%}
{{ insert_mark_message_comment['stg'] }}
{%- endif %}
### prd
{% if env_name == 'prd' -%}
{% include 'resources.md' %}
{% else -%}
{{ insert_mark_message_comment['prd'] }}
{%- endif %}
{% for resource_id in resource_ids -%}
- [ ] {{ resource_id }}
{% endfor -%}
{{ insert_mark_message_comment[env_name] }}
Jinja2==3.1.4
boto3==1.35.45
PyGithub==2.4.0
SAMテンプレート
AWSTemplateFormatVersion: '2010-09-09'
Transform: 'AWS::Serverless-2016-10-31'
Parameters:
ScheduleExpression:
Type: String
EnvName:
Type: String
GitHubPAT:
Type: String
NoEcho: true
GitHubRepo:
Type: String
Resources:
MainFunction:
Type: AWS::Serverless::Function
Properties:
Handler: lambda_function.lambda_handler
Role: !GetAtt LambdaExecutionRole.Arn
CodeUri: src/
Events:
ScheduledEvent:
Type: Schedule
Properties:
Schedule: !Ref ScheduleExpression
Runtime: python3.12
Timeout: 300
Environment:
Variables:
ENV_NAME: !Ref EnvName
GITHUB_PAT: !Ref GitHubPAT
GITHUB_REPO: !Ref GitHubRepo
LambdaExecutionRole:
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument:
Version: 2012-10-17
Statement:
- Effect: Allow
Principal:
Service: lambda.amazonaws.com
Action: sts:AssumeRole
Policies:
- PolicyName: SecurityHubPolicy
PolicyDocument:
Version: 2012-10-17
Statement:
- Effect: Allow
Action:
- securityhub:BatchUpdateFindings
- securityhub:GetFindings
Resource: '*'
ManagedPolicyArns:
- arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole
Outputs:
MainFunctionArn:
Description: ARN of the main function
Value: !GetAtt MainFunction.Arn
ディレクトリ構成はこのようになっています。
.
├── src
│ ├── aws.py
│ ├── conf.py
│ ├── lambda_function.py
│ ├── mygithub.py
│ ├── requirements.txt
│ ├── template.py
│ └── templates
│ ├── new_issue_template.md
│ └── resources.md
└── template.yaml
template.pyとtemplate.yamlが紛らわしいですが、前者はIssueテンプレートを処理するもので、後者はSAMテンプレートのためまったく別物です。
解説
ポイントの解説を行います。
コードを大まかに分けるとこのようになっています。
- Security Hubから新規検出結果を取得し、検出結果をコントロールID単位でグルーピング
- 各コントロールIDに対し、Issueの作成または更新
- 各コントロールIDの検出結果に対し、ワークフローステータスを
NOTIFIEDに変更
Security Hubから新規検出結果を取得し、検出結果をコントロールID単位でグルーピング
aws.pyのget_securityhub_findings()とgroup_findings_by_security_control_id()で行っています。
get_securityhub_findings()でワークフローステータスがNEW、重要度ラベルがCRITICALかHIGHのものを取得しています。
そこで取得した検出結果のリストをgroup_findings_by_security_control_id()でコントロールIDごとにグルーピングしています。
この関数は、取得した検出結果をいい感じに整形する関数だと思ってもらえれば良いかと思います。
検出結果から、キーがコントロールIDになっているdictを生成します。値はIssueの作成・更新や検出結果のワークフローステータスを変更する際に使用する情報を抽出し、dictにした結果が格納されています。
イメージ的には以下のような感じです。
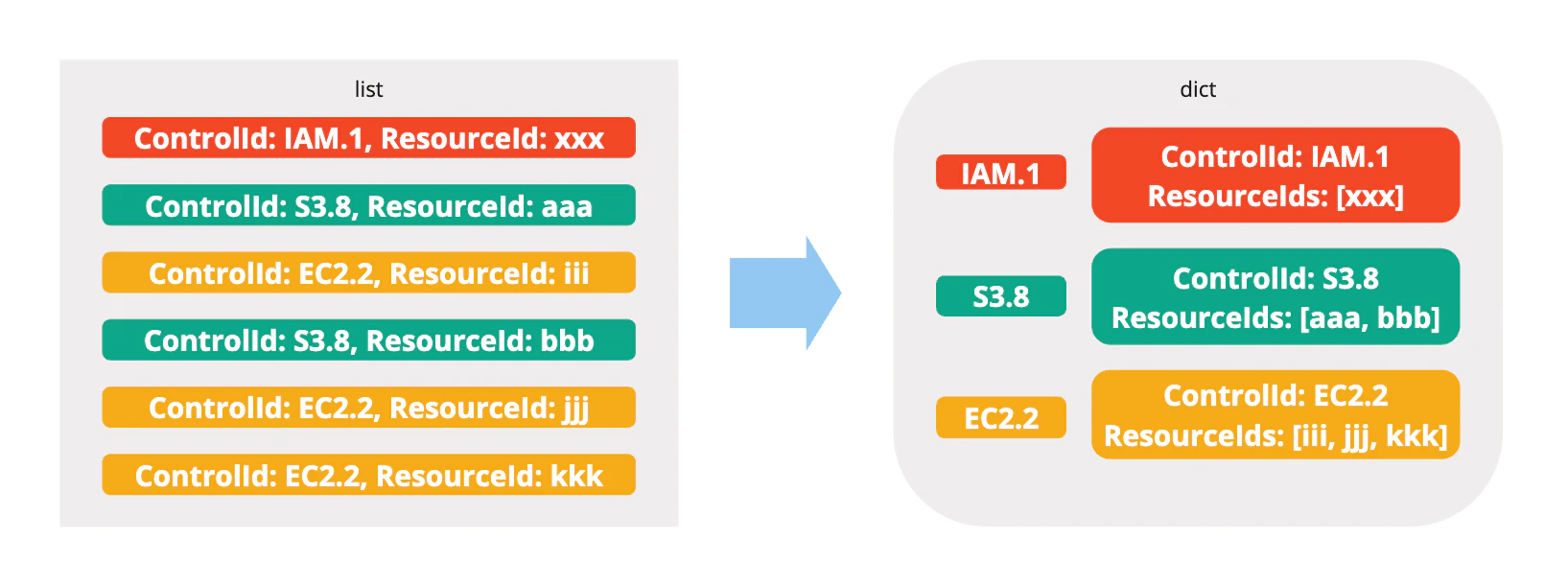
各コントロールIDに対し、Issueの作成または更新
コントロールID単位でIssueを作成または更新します。
mygithub.pyとtemplate.py, templates/以下を使用します。
GitHubの操作はPyGitHubを用いています。import時の名前がかぶるのでファイル名をgithub.pyではなくmygithub.pyにしています。
構成図を見て気づいた方もいらっしゃると思いますが、このシステムではDBを利用していません。もちろんDBに検出結果を格納した方が解決時に自動的にIssueをクローズするように作成できるなどメリットはありますが、考えることが増えるのと運用コストが上がるためにDBは使用していません。
ではどのようにして既存Issueを管理するかというと、ラベルを用いて行っています。
Issue作成時に以下のラベルを付けています。
SecurityHubSecurityHub/{重要度ラベル}SecurityHub/{コントロールID}
SecurityHubラベルはこのシステムで作成するIssueすべてに付与する共通ラベルです。これを検索することでSecurity HubのIssueを探しやすくする意図です。SecurityHub/{重要度ラベル}ラベルも意図としては同じで、人間が探しやすくするためのラベルです。
SecurityHub/{コントロールID}ラベルに関しては他と異なります。これはシステムが既存Issueを引いてくるためのラベルです。
以下の図のようなフローで新規作成か更新かを判断します。
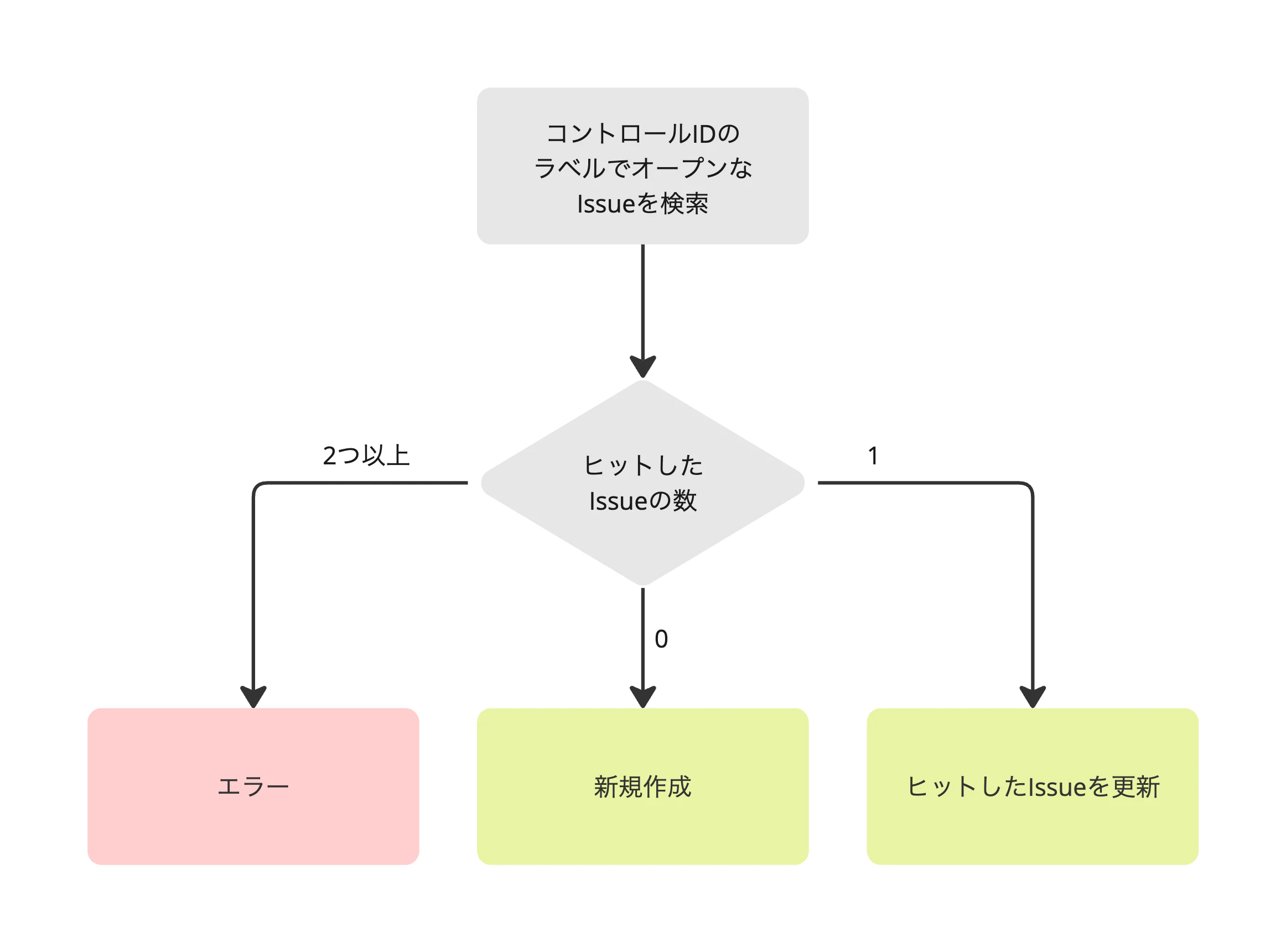
クローズした過去のIssueをオープンにして検出結果を追記することも考えましたが、弊チームのIssue運用方法だと新規作成した方が良さそうだったためこのようにしています。
Issueのbody作成はtemplate.pyで行います。
Jinja2を使用して、あらかじめ用意しているIssueテンプレート内の変数を展開します。
Issue新規作成時
Issueの新規作成時にはtemplates/new_issue_template.mdを使用します。
複数のアカウントの情報を1つのIssueにまとめるため、環境変数で取得してきた環境名で対象リソースの部分に検出されたリソースIDを箇条書きで記載します。
コードの章に記載しましたが、一部再掲します。
(省略)
## 対象リソース
### stg
{% if env_name == 'stg' -%}
{% include 'resources.md' %}
{% else -%}
{{ insert_mark_message_comment['stg'] }}
{%- endif %}
### prd
{% if env_name == 'prd' -%}
{% include 'resources.md' %}
{% else -%}
{{ insert_mark_message_comment['prd'] }}
{%- endif %}
環境名env_nameによって、templates/resources.mdを読み込むかinsert_mark_message_commentを展開するかを分岐しています。
insert_mark_message_commentはconf.pyで定義しており、以下のように定義してあります。
insert_mark_message_comment = {
"stg": "<!-- NOT DELETE:[stg]insert-additional-resources -->",
"prd": "<!-- NOT DELETE:[prd]insert-additional-resources -->",
}
この値はなんでも良いのですが、Issueの更新時にリソースIDを追記する際の目印としています。markdownのコメント文形式にすることで、GitHubからIssueを閲覧した際に表示されないようにしています。これを以降更新用目印と呼びます。
詳細はIssueの更新の部分で説明します。
templates/resources.mdは以下のようになっています。
{% for resource_id in resource_ids -%}
- [ ] {{ resource_id }}
{% endfor -%}
{{ insert_mark_message_comment[env_name] }}
リソースIDを箇条書きとして展開し、その後に更新用目印を入れます。
例えば、env_nameがstgで新規作成する場合は、以下のように変数が展開されます。
(省略)
## 対象リソース
### stg
- [ ] arn:aws:ec2:xxxxx:xxxxx:xxxxx/xxxxx
<!-- NOT DELETE:[stg]insert-additional-resources -->
### prd
<!-- NOT DELETE:[prd]insert-additional-resources -->
これをbodyとしてIssueを新規作成します。
Issue更新時
Issue更新時は、templates/resources.mdを用いて変数を展開します。これは新規作成時のテンプレート内でも使用していましたが、リソースIDを箇条書きにして展開します。
例えば、env_nameがstgのアカウントに新たにarn:aws:ec2:xxxxx:xxxxx:xxxxx/aaaaaというリソースが検出されたとすると、templates/resources.mdは以下のように展開されます。
- [ ] arn:aws:ec2:xxxxx:xxxxx:xxxxx/aaaaa
<!-- NOT DELETE:[stg]insert-additional-resources -->
更新前のIssueには新規作成で説明したようなbodyがセットされています。そのbodyの更新用目印を上記の値にreplaceすることで、以下のようなbodyになります。
(省略)
## 対象リソース
### stg
- [ ] arn:aws:ec2:xxxxx:xxxxx:xxxxx/xxxxx
- [ ] arn:aws:ec2:xxxxx:xxxxx:xxxxx/aaaaa
<!-- NOT DELETE:[stg]insert-additional-resources -->
### prd
<!-- NOT DELETE:[prd]insert-additional-resources -->
このようにリソースIDを追記してIssueを更新します。env_nameがprdの際はprd部分に記載されていきます。
各コントロールIDの検出結果に対し、ワークフローステータスをNOTIFIEDに変更
Issueの作成や更新が完了したら、検出結果のワークフローステータスをNOTIFIEDに変更します。これを行うことで、何度も同じリソースが検出されて対象リソース一覧が重複することを防止します。
BatchUpdateFindingsは一度に最大100件までしか更新できない1ため、100件ずつ更新します。
デプロイ
Lambdaをデプロイします。今回デプロイにはSAMを使用しています。
SAMのインストール方法は「AWS SAM CLI のインストール」を参考にしてください。macOSでHomebrewがインストールされている場合は以下のコマンドでインストールするのが楽だと思います。
brew install aws-sam-cli
template.yamlがあるディレクトリで以下のコマンドを実行します。
stack_nameは任意のスタック名、github_patはGitHubのパーソナルアクセストークン、github_repoはIssueを作成するGitHubリポジトリ名を入れてください。
GitHubのパーソナルアクセストークンの取得は「personal access token (classic) の作成」を参考にしてください。スコープはrepoにチェックを入れます。
GitHubのパーソナルアクセストークンの代わりにGitHub Appを用いる場合、GitHubへの接続方法が変わります。
ドキュメントを参考にコードを修正してください。
sam build
# 変数の設定
stack_name=
github_pat=
github_repo=
# stgのデプロイ
# stgのAWSアカウント認証情報を環境変数にセットした状態とする
sam deploy --stack-name $stack_name --resolve-s3 \
--parameter-overrides \
"EnvName=stg GitHubPAT=$github_pat ScheduleExpression='cron(0 1 * * ? *)' GitHubRepo=$github_repo" \
--capabilities CAPABILITY_IAM
# prdのデプロイ
# prdのAWSアカウント認証情報を環境変数にセットした状態とする
sam deploy --stack-name $stack_name --resolve-s3 \
--parameter-overrides \
"EnvName=prd GitHubPAT=$github_pat ScheduleExpression='cron(10 1 * * ? *)' GitHubRepo=$github_repo" \
--capabilities CAPABILITY_IAM
AWSアカウントの認証情報を環境変数にセットした状態として実行していますが、プロファイルが設定されていればコマンドオプション--profileで設定することも可能です。
コマンドオプション--resolve-s3を設定してデプロイに使用するAmazon S3バケットを自動的に作成していますが、別のバケットにしたい場合などは適宜読み替えてください。コマンドオプションは公式ドキュメントを参考にしてください。また、Lambda用のIAMロールを作成しているので、--capabilities CAPABILITY_IAMが必要です。
ScheduleExpressionでEventBridgeのスケジュールを設定します。同じ時間でなければ何時でも構いませんが、今回の例ではstgは日本時間で10:00, prdは日本時間で10:10に起動するように設定しています。stgとprdの起動タイミングをずらすことで、stgで作成したIssueにprdのリソースを追記しています。
スケジュールの時間より前にLambdaの実行を確認したい際は、マネジメントコンソールのLambda詳細画面からテストタブに遷移し、テストボタンを押下することでも実行できます。

stg, prd両方のAWSアカウントのLambda実行後は以下のようなIssueになっているはずです。
まとめ
Pythonで記述したLambdaを利用して、Security Hubの検出結果をコントロールID単位でGitHub Issue化する方法を解説しました。
参考になるところが少しでもあれば幸いです。
ここまで読んでくださりありがとうございました。
参考記事
-
↩The list of findings to update. BatchUpdateFindings can be used to update up to 100 findings at a time.
https://boto3.amazonaws.com/v1/documentation/api/1.26.91/reference/services/securityhub/client/batch_update_findings.html