Pythonでデータを可視化するライブラリはいくつかありますが、Pandasだけでも結構なんとかなります。
Pandasを使った可視化はメソッドチェーンで完結できるので、無秩序に一時変数が散乱することを僅かながら防ぐことができます。
この記事では、私が実務でよく使うものを中心に、可視化のレシピを紹介します。
準備
環境
- Python: 3.6.8
- Pandas: 1.0.4
データ
今回は次の2つのデータをお借りします。
それぞれtitanicとcrimeというDataFrameにします。
import pandas as pd
import zipfile
# 便利ジェネレータ
def read_zipcsv(file, **kwargs):
with zipfile.ZipFile(file) as myzip:
for name in myzip.namelist():
with myzip.open(name) as myfile:
yield name, pd.read_csv(myfile, **kwargs)
_, titanic = next(read_zipcsv('titanic.zip'))
_, crime = next(read_zipcsv('crimes-in-boston.zip', encoding='latin-1', parse_dates=['OCCURRED_ON_DATE']))
可視化のレシピ
数値データの可視化
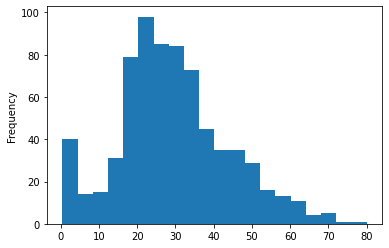
シンプルなヒストグラム
titanic['Age'].plot.hist(bins=20)
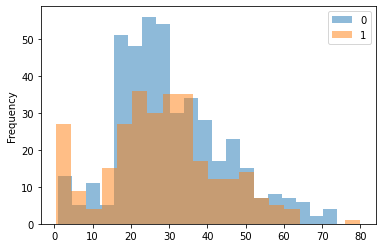
カテゴリごとのヒストグラム
titanic.groupby('Survived')['Age'].plot.hist(bins=20, alpha=0.5, legend=True)
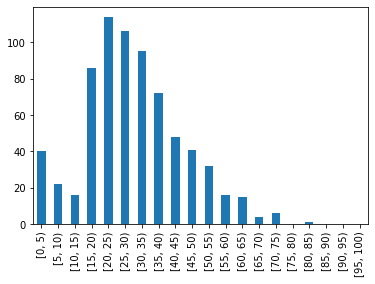
年齢階級別の棒グラフ
年齢の場合はよく年齢階級別に集計します。これは5歳ごとの年齢階級で集計する例です。
pd.cut(titanic['Age'], range(0, 101, 5), right=False).value_counts(sort=False).plot.bar()
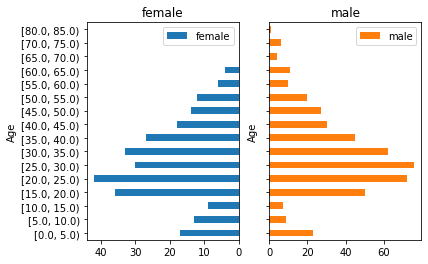
年齢階級・性別の棒グラフ
更に性別別に集計する場合は水平棒グラフを2つ並べて左方のX軸を反転させます。所謂、人口ピラミッドです。
(ax0, ax1), = pd.crosstab(pd.cut(titanic['Age'], range(0, 101, 5), right=False), titanic['Sex']).plot.barh(subplots=True, layout=(1, 2), sharex=False)
ax0.invert_xaxis() # 左側のグラフのX軸を反転する
ax1.set_yticklabels([]) # 右側のグラフのY軸のラベルを消す
シンプルな散布図
titanic.plot.scatter(x='Age', y='Fare', alpha=0.3)
カテゴリごとの散布図
ax = plt.axes()
for i, (name, group) in enumerate(titanic.groupby('Survived')):
group.plot.scatter(x='Age', y='Fare', c=[plt.get_cmap('tab10').colors[i]], label=name, alpha=0.3, ax=ax)
カテゴリデータの可視化
シンプルな棒グラフ
titanic['Embarked'].value_counts(dropna=False).plot.bar()
DataFrameのStylingで水平棒グラフ
DataFrameを棒グラフっぽくできます。
画像と違ってテキストを検索できます。
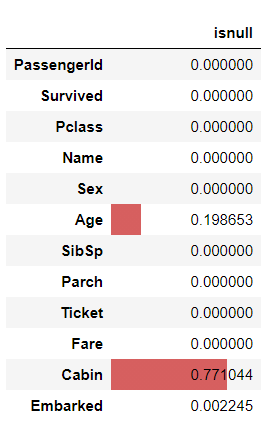
nullの割合
titanic.isnull().mean(axis=0).rename('isnull').to_frame().style.bar(vmin=0, vmax=1)
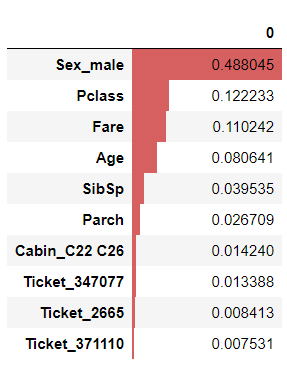
feature importance
決定木のfeature importanceもこの通り。
from sklearn.tree import DecisionTreeClassifier
X = pd.get_dummies(titanic.drop(columns=['Survived', 'PassengerId']), drop_first=True).fillna(0)
y = titanic['Survived']
model = DecisionTreeClassifier(max_depth=6).fit(X, y)
pd.DataFrame(model.feature_importances_, index=X.columns).sort_values(0, ascending=False)[:10].style.bar(vmin=0)
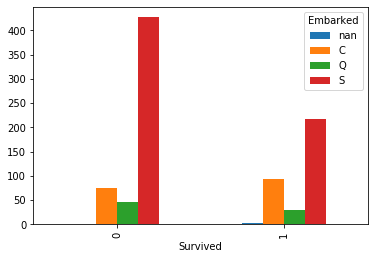
カテゴリごとの棒グラフ
titanic.groupby('Survived')['Embarked'].value_counts(dropna=False).unstack().plot.bar()
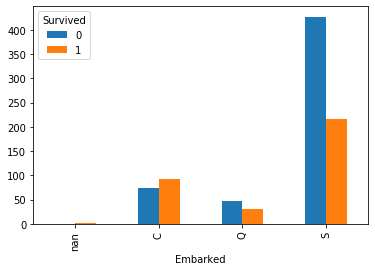
titanic.groupby('Survived')['Embarked'].value_counts(dropna=False).unstack(0).plot.bar()
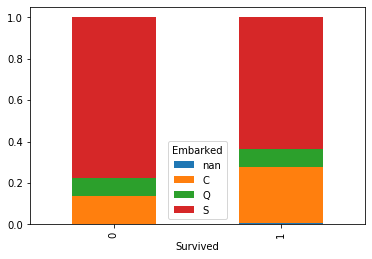
100%積み上げ棒グラフ
titanic.groupby('Survived')['Embarked'].value_counts(dropna=False, normalize=True).unstack().plot.bar(stacked=True)
エラーバー付き棒グラフ
yerrでエラーバーのサイズを渡します。
標準偏差
Pandasのstdはデフォルトでddof=1なので、不偏標準偏差が返ってきます。
titanic.groupby(['Survived', 'Pclass'])['Fare'].mean().unstack(0).plot.bar(
yerr=titanic.groupby(['Survived', 'Pclass'])['Fare'].std().unstack(0)
)
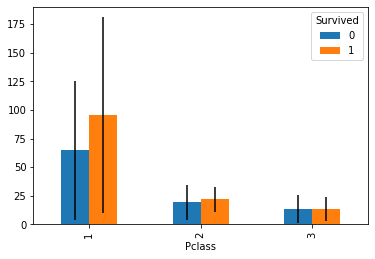
Note: ちなみに不偏標準偏差は不偏分散の平方根ではないです。詳しくはこちらの記事をご覧ください。
信頼区間
母平均の95%信頼区間を求めてみます。母分散は未知です。(既知のケースってあるのかな…)
Pandasのvarは(stdと同様に)デフォルトでddof=1なので、不偏分散が返ってきます。
import numpy as np
from scipy.stats import t
def c(s, alpha=0.95):
return t.ppf((1 + alpha) / 2, s.shape[0] - 1) * np.sqrt(s.var() / s.shape[0])
pd.crosstab(titanic['Pclass'], titanic['Survived'], titanic['Fare'], aggfunc='mean').plot.bar(
yerr=pd.crosstab(titanic['Pclass'], titanic['Survived'], titanic['Fare'], aggfunc=c),
)
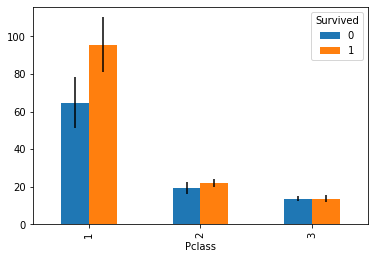
Note: 「母分散は未知」と書きましたが、結果に影響するのはサンプルサイズが小さいとき(具体的には30未満くらい)なので、あまり意識する機会はないと思います。一応t分布を使って信頼区間を求めてますが、サンプルサイズが大きければ正規分布で近似しても良いですし、95%と決まってるなら
t.ppf((1 + alpha) / 2, s.shape[0] - 1)の代わりに1.96を使っても良いです。
日付データの可視化
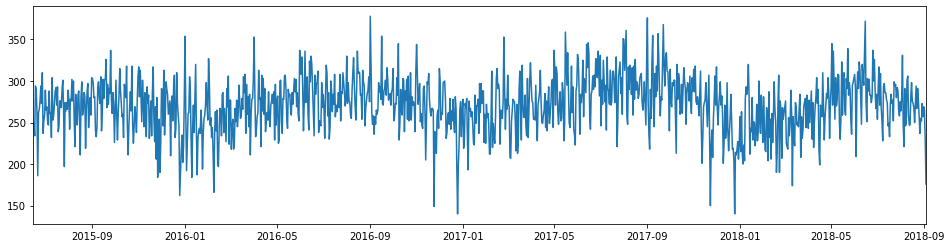
年月日の折れ線グラフ
crime['OCCURRED_ON_DATE'].dt.date.value_counts().plot.line(figsize=(16, 4))
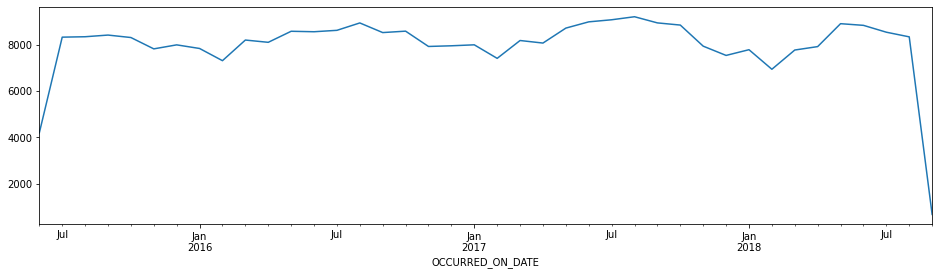
年月の折れ線グラフ
crime['OCCURRED_ON_DATE'].dt.date.value_counts().plot.line(figsize=(16, 4))
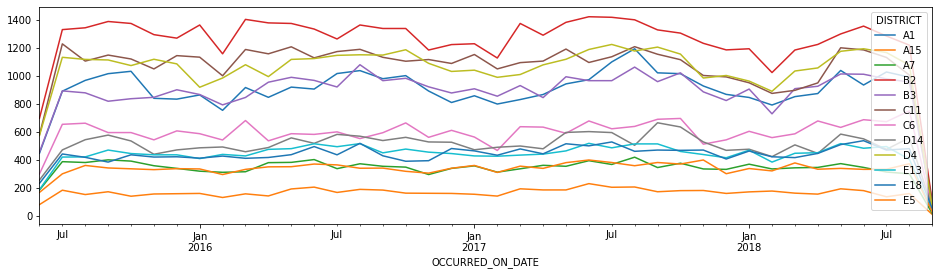
カテゴリごとの年月の折れ線グラフ
crime.groupby(pd.Grouper(key='OCCURRED_ON_DATE', freq='M'))['DISTRICT'].value_counts().unstack().plot.line(figsize=(16, 4))
その他の可視化
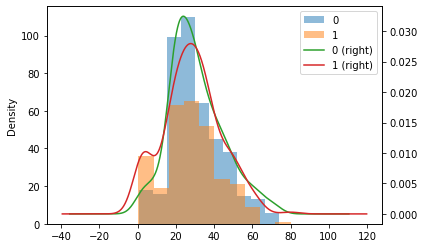
グラフを重ねる
ヒストグラムとカーネル密度推定のグラフを重ねてみます。
titanic['Age'].groupby(titanic['Survived']).plot.hist(alpha=0.5, legend=True)
titanic['Age'].groupby(titanic['Survived']).plot.kde(legend=True, secondary_y=True)
芝生
pd.crosstab(
crime['OCCURRED_ON_DATE'].dt.day_name().rename('day_of_week'),
crime['OCCURRED_ON_DATE'].dt.week.rename('week')
).loc[['Sunday', 'Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday']].style.background_gradient(axis=None, cmap='YlGn')

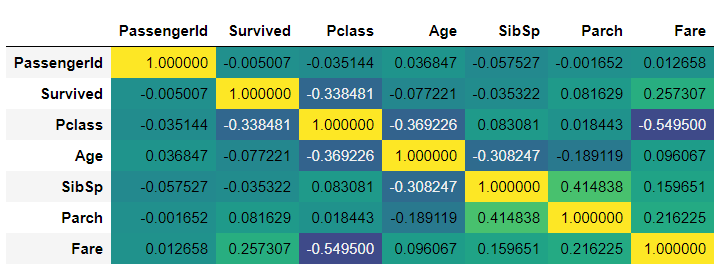
相関行列
次の記事で紹介してます。
corr = titanic.corr()
low = (1 + corr.values.min()) / (1 - corr.values.min())
corr.style.background_gradient(axis=None, cmap='viridis', low=low).format('{:.6f}')
終わり
比較的簡単に使えそうなものを紹介してみました。
こんなのもあるよ!という方、ぜひ教えてください。
より凝ったグラフを描きたい方は次のページが参考になると思います。