はじめに
最近、社内でAI勉強会をしていて、画像内の文字を任意のロゴに変換するプロダクトのプロトタイプを作りました。
社内AI勉強会を実施しました
今回はそれに似た論文があったので紹介しようと思います。
STEFANN: Scene Text Editor using Font Adaptive Neural Networkでは、下の画像のように画像中の文字を自然に、別の文字と入れ替えることができます。
Githubのリポジトリはこちら

TL:DR
以下の2つのモデルによって、二段階の処理をします。
- 置き換え対象の文字領域と置き換え後の文字データを受け取り白黒の文字画像を生成するFANet
- 元の文字の情報から色を付けるColorNet
ただし、既存の文字を一文字ずつ置き換えるため、元と違う文字数にすることはできません。(あくまで誤字を修正するようなもの)
提案手法
文字領域の選択
まず、バウンディングボックスによって文字を検知をします。本研究では EAST: An Efficient and Accurate Scene Text Detector を使用します。この処理によって得られた修正を必要とする領域を$\Omega$とします。
その後、$\Omega$に対して文字領域のバイナリマスクを生成します。この時、Robust text detection in natural images with edge-enhanced Maximally Stable Extremal Regionsで考案されているMSER(Maximally Stable Extremal Regions)アルゴリズムを使用します。ですが、MSERだけではシャープなマスクが生成できないため本研究では以下のような改善が行われています。
複数の文字が含まれた画像$I$があり、最終的に得られるマスクを$I_c$とします。このとき
I_c(\boldsymbol{p})=\begin{cases}
I_M(\boldsymbol{p})\odot I_B(\boldsymbol{p}) & if \boldsymbol{p} \in \Omega \\
0 & otherwise
\end{cases}
となります。ただし、$I_M$, $I_B$, $\odot$はそれぞれ、$I$を入力とした時のMSERの出力、$I$を2値化したもの、アダマール積です。もし文字が背景より暗い場合は$I$に逆2値化を行ます。
その後、文字が重なっていないことを前提として連結成分分析を行い、各連結成分の最小範囲の領域が収まる矩形を計算します。
前で述べたように切り出された矩形領域は文字に合わせているので正方形とは限りません。しかしニューラルネットワークの入力は通常正方形なので、文字領域の集合の中で最も大きいものに合わせてパディングしたあとで、64$\times$64にリサイズします。
Font Adaptive Neural Network (FANnet)
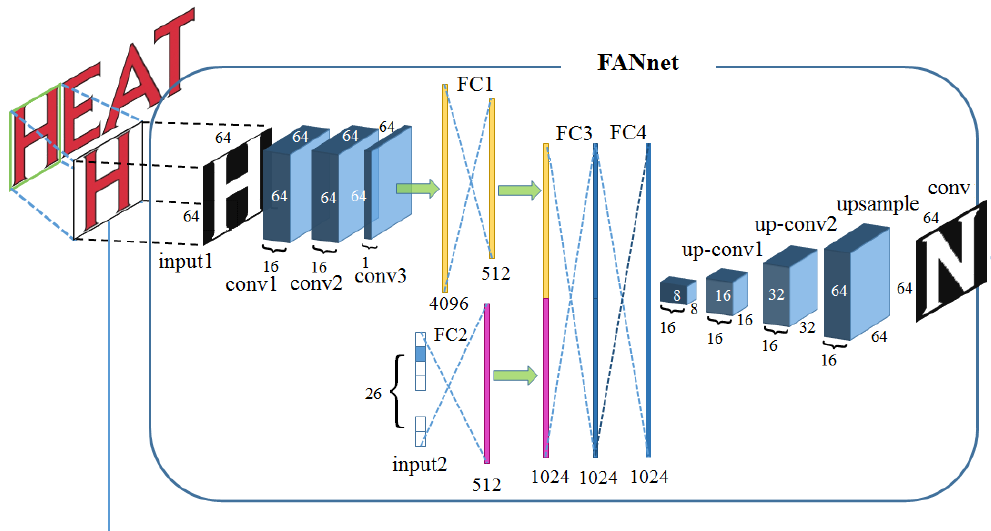
FANnetでは先ほどの64$\times$64の文字画像と、合成したいアルファベット(大文字)をone-hotエンコーディングしたベクトル$\boldsymbol{v}$を入力とします。
まず、画像の方は、上の図のように3層の畳み込み層を通ったあと全結合層(FC1)を通ります。また、ラベルの方は(FC2)を通ります。その後FC1とFC2の出力を合成しFC3へ入力されます。FC4を通った後は3層の逆畳み込み層でアップサンプリングされ64$\times$64の画像が生成されます。

上の図は本物のフォントと実際にFANnetで生成された文字の比較です。二段ずつ本物のフォント(上)と生成された文字(下)の比較が示されています。

また、この図のように以下のような実験も行われています。
(a): 小文字から小文字の生成
(b): 小文字から大文字の生成
(c): 大文字から小文字の生成
Colornet
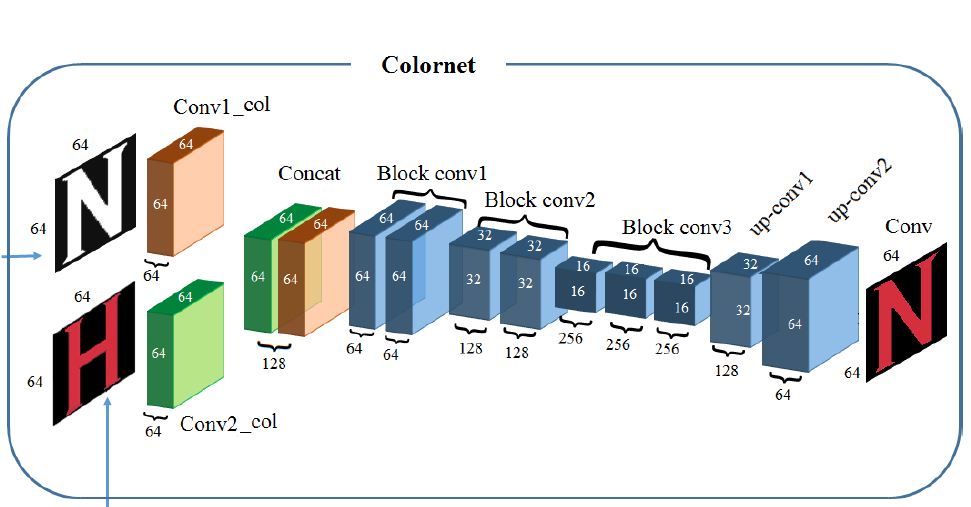
Colornetでは先ほどFANnetで生成した白黒画像と元画像を入力として、白黒画像に色を付けます。それぞれの画像は、畳み込み層を通り64$\times$64$\times$64のデータになった後、Batch Normalizationされた後、concatされ1つの64$\times$64$\times$128のデータとなります。その後、2層の畳み込み層の間に2層のMax Pooling層を挟んだBlock Conv層を3層通り、後の2層の逆畳み込み層でアップサンプリングされます。
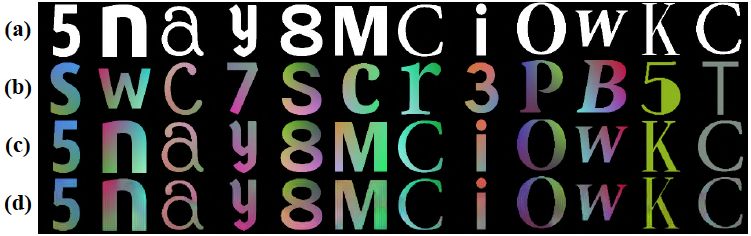
上の図は本物とColornetで生成されたものの比較です。
(a): FANnetで生成した白黒画像
(b): 色情報のソースとなる画像
(c): 本物
(d): Colornetの出力
元画像と生成画像の置換
An Image Inpainting Technique Based on the Fast Marching Methodを用いて画像$I$から対象の文字領域と生成画像を置換します。
結果
データセットCOCO-TextとICDAR datasetを用いて結果を示します。

それぞれ左がデータセットの画像で、右がSTEFANNによって生成された画像です。
評価
FANnet
FANnetの評価ではASSIM(average structural similarity index)という指標を使用します。SSIMは、以下の3つの要素がどれくらい変化したかを評価しているようです。
- 画素値(輝度値)の変化
- コントラストの変化
- 構造の変化
類似度なので高いほど良いスコアとなります。
テストフォント300種類におけるアルファベット間のASSIMはだいたい0.8弱でした。
FANnetの評価方法は、"A"という文字の画像を入力としたときの、出力と入力におけるASSIMです。

上の図から、通常のFCNでは十分に学習できていないと言えます。一方で、FANnetではテストフォントのASSIMと同等のスコアが出ています。
他の手法との比較
比較対象は以下の通りです。

上の図はFANnetとMC-GANの比較です。ただし、緑の部分はどちらもうまく生成できたもの、黄色の部分はMC-GANの方がうまく生成できたものです。

まとめ
画像のように画像中の文字を自然に、別の文字と入れ替えることができるSTEFANNを紹介しました。論文内では誤字訂正の用途で使用されることを想定していますが、他のことにも応用できそうな技術だと感じました。