はじめに
ライス大学とインテル社の共同開発によって、GPUのような特別なアクセラレーションハードウェアなしでディープラーニングを高速化できるSLIDEが考案されました。そのSLIDEについて解説します。
Deep Learning Breakthrough Results In A 44-Core Intel Xeon Destroying NVIDIA Tesla V100 GPU
TL:DR
GPUが得意とする行列演算をやるのではなく、LSHによって直接計算せず活性化したニューロンを取得することができます。
Locality Sensitive Hashing
Locality Sensitive Hashing(LSH)は、大量なデータから類似度が高いデータのペアを高速に抽出してくれるアルゴリズムです。以下は参考ページです。SLIDEはこのLSHの考え方に基づいて設計されています。
LSH (Locality Sensitive Hashing) を用いた類似インスタンスペアの抽出
LSHは類似度を総当たりで計算する処理は行いません。LSHではベクトルを入力とし、スカラ値を出力する関数 (ハッシュ関数) を定義し、似たベクトルであれば同一の値を返しやすくするよう設定します。
LSHのアルゴリズムでは$L$個の独立したハッシュテーブルを持っていて、それぞれのテーブルに$K$個のハッシュ関数を連結したメタハッシュ関数$H$を持ちます。クエリが与えられると各テーブルからのバケットの和を返します。
メタハッシュ関数はバケットをスパースにすることで偽陽性の確率を小さくすることができます。また、$L$個のバケットの結合を行うことで有効な最近傍点を保持する可能性のあるバケットの数を増やすことができ、偽陰性の可能性も小さくすることができます。
次に説明するSLIDE内のLSHで使用されるハッシュ関数は以下のようなものがあります。
- Simhash
- WTA hash
- DWTA hash
- Minhash
SLIDE : IN DEFENSE OF SMART ALGORITHMS OVER HARDWARE ACCELERATION FOR LARGE-SCALE DEEP LEARNING SYSTEMS
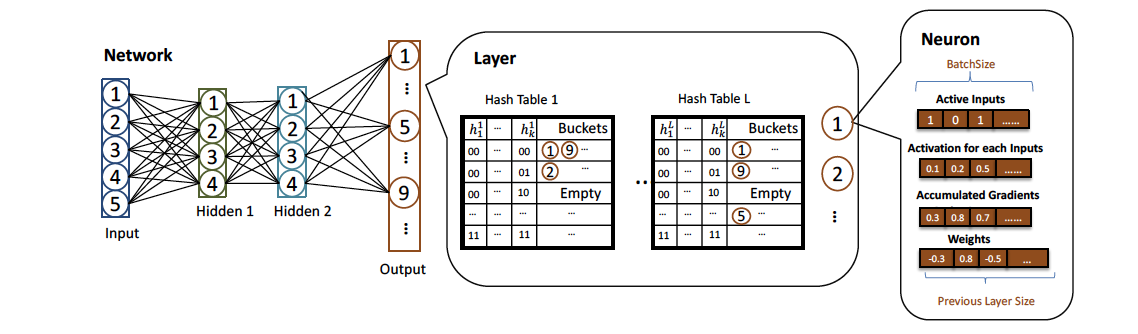
各レイヤーは、ニューロンのリストとLSHのハッシュテーブルをセットで持っています。各ハッシュテーブルではバケットに、ハッシュされたニューロンのIDが含まれています。$h_{l}$をメタハッシュ関数、$w_{l}^{a}$をレイヤー$l$における$a$番目のニューロンの重みとすると、$a$番目のニューロンはメタハッシュ関数$h_{l}(w_{l}^{a})$でバケットにマッピングされます。各層でのテーブルの構築は、レイヤー内の各ニューロンの処理が独立なことから複数のスレッドで並列して行うことができます。
順伝播
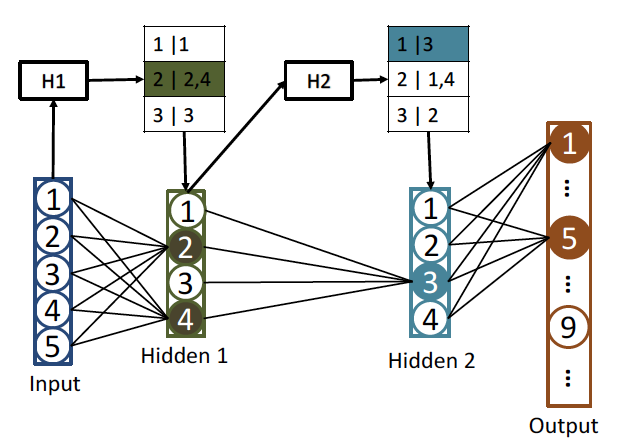
順伝播の段階では通常のニューラルネットが行う計算の代わりに、SLIDEでは活性化関数ではなくハッシュ関数で計算します。計算されたハッシュコードによってアクティブな(活性化した)ニューロンを取得するクエリとして機能します。
具体的には、上の図で説明すると、入力層から中間層1への入力を$x_1$, 中間層1のハッシュ関数を$h_1$とすると$h_1(x_1)$の出力であるハッシュコード$H1$は2となり、その値でハッシュテーブルに問い合わせることでアクティブなニューロンを取得します。加えて、アクティブなニューロンだけの情報を使用し、非アクティブなニューロンからの情報を0とすることでサンプリングし、計算量を抑える工夫をしています。
また、softmaxを活性化関数として持つ出力層でも同様にハッシュテーブルからサンプリングされたアクティブなニューロンを扱います。よって、出力層は以下のような値を出力します。ただし$x_l$はレイヤー$l$への入力です。
\sigma(N_o^k)=\frac{e^{{x_o}{w_o^x}}}{\sum_{N_o^a}{e^{{x_o}{w_o^x}}}}
逆伝播
一般的な誤差逆伝播法を用いて重みを更新します。ニューロンは、接続された重みを介して前の層のアクティブなニューロンだけに勾配を伝搬し、アクティブではないニューロンの重みを更新しません。これによりスパース性を確保でき、計算量がパラメータの総和ではなくアクティブなニューロンに関してのみとなります。
ハッシュテーブルの更新
重みの更新のあとで、ハッシュテーブルにおけるニューロンの位置を変更します。これには、古いバケットの削除と新しいバケットの追加の処理が含まれますが、かなり計算コストがかかるという問題があります。なので、オーバーヘッドを削減するための手法を次に示します。
- ハッシュテーブルの更新頻度を動的に変化させる
- すでに容量に空きのないバケットにニューロンを追加する時のプロトコルとして、LSHテーブルに合わせてVitters reservoir sampling algorithmを改良した、Wangらの手法を使用する
- ハッシュ関数がSimhashの場合、重みの更新には$w^Tx$の差しか影響しないため、ハッシュコードに加えて$w^Tx$の値もキャッシュしておく
評価
評価に使用するCPUとGPUはそれぞれ以下の通りです。
- CPU: 22core/44thread Intel Xeon E5-2699A v4 2.40GHz
- GPU: NVIDIA TeslaV100 Volta 32GB
また、評価に使用するデータセットは以下の通りです。リポジトリはこちら
- Delicious-200K
- Amazon-670K
実行時間とイテレーション数
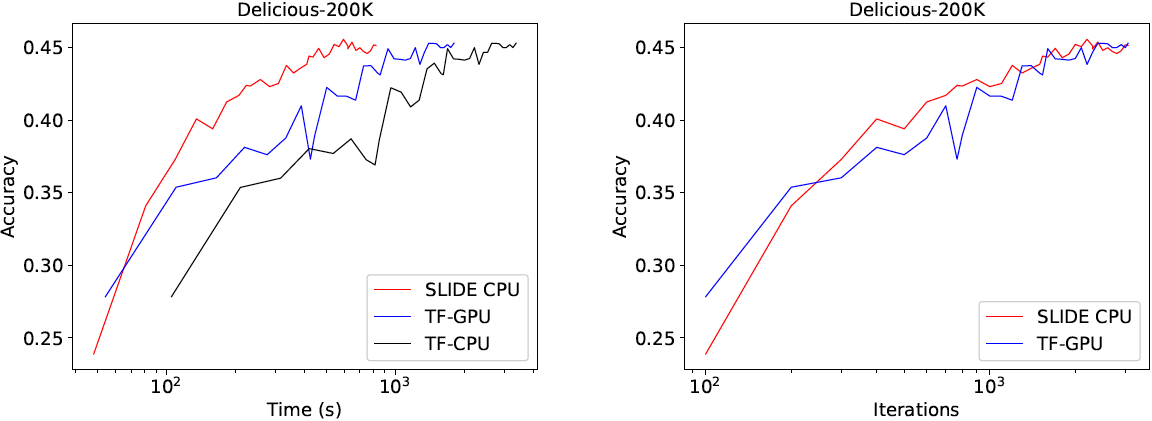
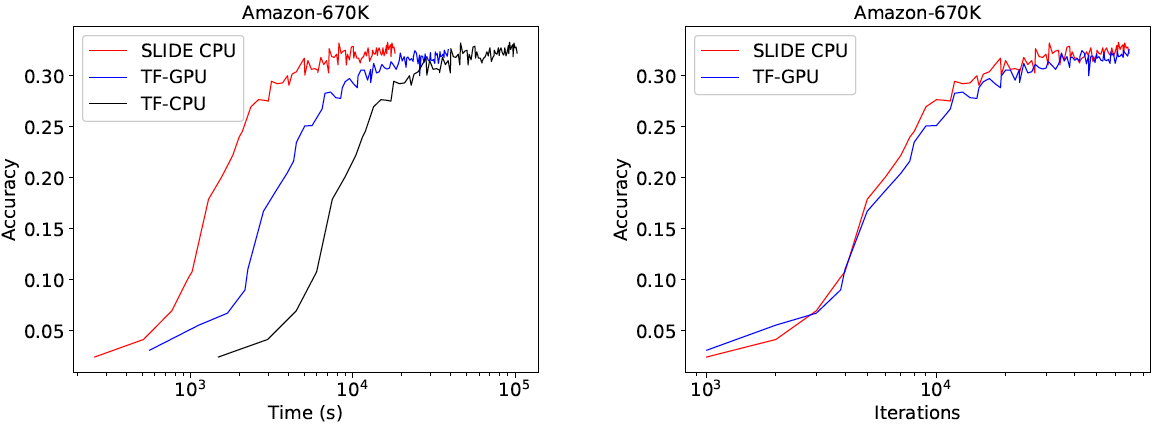
上の図では、学習にかかる実行時間とイテレーション数の比較です。収束にかかるイテレーション数はSLIDE CPUとTF-GPUで同等にもかかわらず、実行時間に関しては各データセットでSLIDE CPUが最も良い結果となっています。
数回のイテレーション後、SLIDEの出力層のアクティブなニューロン数はDelicious-200Kではおよそ1000, Amazon-670kではおよそ3000であり、これは出力層のおよそ0.5%に当たります。
CPUの使用効率

上の表はIntel VTune Performance Analyzer(2009)を使用した8, 16, 32スレッドでのCPUの平均使用率の解析結果です。SLIDEでは80%以上を保っていることが分かります。
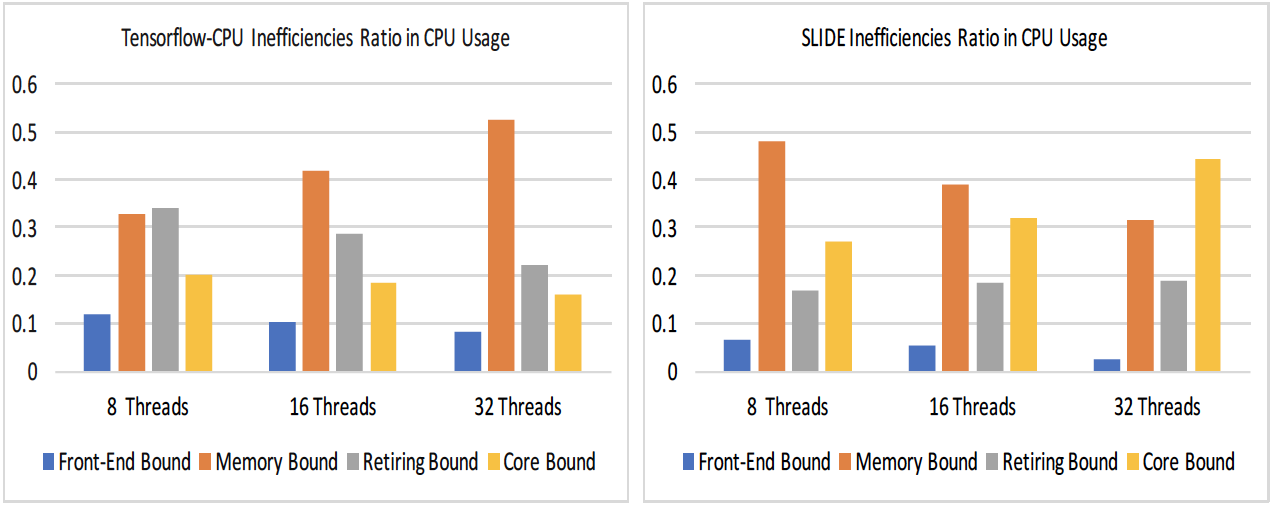
また、上の図はCPUの非効率性の分布を示したものです。ボトルネックとなるメモリのロードとストアに関して、TF-CPUではスレッド数が増加するに従い増加している一方、SLIDEでは減少していることが分かります。
まとめ
GPUのような特別なアクセラレーションハードウェアなしでディープラーニングを高速化できるSLIDEという手法についてまとめました。論文内では、今後の課題としてconvolution layerへの応用が挙げられているので、実現すれば画像分野でもSLIDEを用いて学習コスト軽減ができる日がくるかもしれません。実装のリポジトリを下に置いておくので、そちらも参考にしてみて下さい。