LLM(大規模言語モデル)は、自然言語処理(NLP)タスクを解決するための人工知能モデルの一種です。これらのモデルは、翻訳、質問応答、文章生成などのタスクを達成する能力を持っています。また、これらのモデルは非常に大規模なテキストデータセットから学習し、文の構造、語彙、文法、さらには一部の世界知識を理解します。
Agent(エージェント)
エージェントは、一定の知識と自立行動能力を持つエンティティを指します。これは、計画を立て、ツールを呼び出し、アクションを実行することができます。大規模な言語モデルを使って計画を立て、どのステップを実行するか、各ステップでどのツール(例えばRAG)を呼び出すかを決定し、その後、適切なツールを呼び出してタスクを完了します。
RAG(Retrieval-Augmented Generation)
RAGは、大規模モデルが問題に対する正確な回答を提供するのを助けるためのものです。従来の大規模モデルは、答えを「創り出す」傾向がありますが、RAGは、検索と生成の2つのステップを通じてこの問題を解決し、"幻覚"を解消する重要な手段となります。
まず、それは関連するドキュメントやデータソース(例えば、データベースやウェブリソース)を検索し、最も関連性の高いフラグメントを証拠として見つけ出します。
次に、大規模モデルは、これらの証拠を用いて正確な回答を生成します。
RAGシステムは3つの主要なモジュールで構成されています:
- リトリーバ(Retriever):コンテキストに関連する知識源からドキュメントの段落を検索します。
- リランカ(Reranker):検索できる段落を再評価し、再順序付けします。
- ジェネレータ(Generator):コンテキストと検索した段落を統合して出力テキストを生成します。
成功したRAGシステムには、主に2つの機能が必要です:検索では、ユーザーのクエリに最も関連性のあるドキュメントを見つける必要があります。そして、生成では、これらのドキュメントを効果的に使用してユーザーのクエリに回答する必要があります。
LangChain
LangChainは、大規模言語モデルに基づくアプリケーションの開発を目指したプログラミングフレームワークです。これは、開発者がさまざまなコンポーネントを構築し統合するのを容易にする一連のツールとサービスを提供します。
RAG技術の応用に関連して、LangChainは開発者が多様なデータソースを効率的に整理、検索、接続するのを助けます。例えば、テキストデータをベクトル化して保存し、大規模モデルとインタラクションを行うことができます。
三者の関係は次のように理解
例えば、カスタマーサービスのQ&Aプロダクトを作る場合、
1、LangChainは基盤となるプラットフォームとして、このようなシステムを構築するためのツールとサービスを提供します。開発者はLangChainを使用して、検索サービスや商品価格情報ベース、大規模モデルなど、さまざまなツールとサービスを統合します。
2、エージェントは、全体のカスタマーサービス処理プロセスを調整し実行する中心的な役割を果たします。
①計画を立てる:ユーザーが「5キロの特大リンゴと3キロの中サイズのリンゴ、合計でいくらですか?」と問いかけた場合、エージェントは大規模モデルを呼び出して計画を立てます。
大規模モデルは、このプロセスを2つのステップに分けます。第一ステップでは、特大リンゴの単価と中サイズのリンゴの単価を問い合わせ、第二ステップでは、5キロの特大リンゴと3キロの中サイズのリンゴの合計価格を計算します。第一ステップではRAGツールを、第二ステップでは計算器ツールを呼び出す必要があります。
②ツールを呼び出す:RAGツールは、まず検索モジュールを通じて商品価格情報ベースから関連情報を検索し、最も関連性の高い項目を見つけます。その後、エージェントはこれらの項目を計算ツールに渡し、計算ツールは合計価格を計算します。
③アクションを実行する:大規模モデルは、合計価格に基づいてカスタマーサービスの文章を生成します。
RAG(Retrieval-Augmented Generation)の技術詳細
RAG(Retrieval-Augmented Generation)の技術詳細は以下のステップに要約できます:
データインデックス
データ抽出
データクレンシング:データローダー、PDF、Word、マークダウン、およびデータベースやAPIなどからのデータ抽出を含みます。
データ処理:データ形式の処理、認識できない内容の除去、圧縮および整形などを含みます。
メタデータ抽出:ファイル名、時間、章節のタイトル、画像のalt属性などの情報を抽出することは非常に重要です。
検索フェーズ:
まず、質問が到着すると、RAGシステムは検索モデル(Retriever)を使用して、予め設定されたドキュメントセット(例えば、ウィキペディア)から関連するドキュメントや情報フラグメントを探します。
この検索モデルは通常、質問とドキュメントをベクトル形式に変換するembeddingと呼ばれる方法を使用し、これらのベクトル間の距離や類似性を計算して最も関連するドキュメントを見つけます。
主な検索方法はこの数種類があります:
類似度検索: ユークリッド距離、マンハッタン距離、コサイン類似度など6種類の類似度検索アルゴリズムがあります。
キーワード検索: メタデータによるフィルタリングはその一種ですが、別の方法としてはまずチャンクを要約し、次にキーワード検索を行って関連するチャンクを見つけ出す方法があり、検索効率が向上します。Claude.aiもこの方法を採用しているそうです。
SQL検索: これはより従来の方法ですが、ローカル企業アプリケーションにとってはSQLクエリは不可欠なステップです。
この段階の目的は、質問の答えを含む可能性があるドキュメントを見つけることです。
ランキングフェーズ:
検索フェーズの後、RAGシステムは候補ドキュメントのセットを得ます。次に、システムはランキングモデル(Reranker)を使用してこれらのドキュメントにスコアを付け、ソートし、どのドキュメントが正しい答えを含む可能性が最も高いかを決定します。この段階の目的は、検索結果を最適化し、最も関連するドキュメントが優先的に考慮されることを確認することです。
生成フェーズ:
最後に、RAGシステムは生成モデル(Generator)を使用して、最も高いランクのドキュメントに基づいて質問の答えを生成します。この生成モデルは通常、強力な言語モデルであり、質問のコンテキストを理解し、提供されたドキュメントに基づいて一貫性と正確性のある答えを生成することができます。
以上がRAG技術の基本的なプロセスです。実際の応用では、これらのステップは異なる可能性があります。具体的なモデルやデータセットなどによります。
実際のOpenAI APIインターフェースの呼び出し例
GPT-3.5を使用してクエリのプロンプトを作成します。
主な内容は次のとおりです:
ユーザーのクエリに関連するさまざまなクエリを生成するために、大規模言語モデル(LLMs)をどのように使用するか ==> JSON結果を使用したプロンプトビルダー
次に、これらのクエリを使用して、ニュースAPIからニュースを取得する方法。(ちなみに、APIキーが必要です)
さらに、再度LLMsを使用して仮定の答えを構築し、その答えと比較してニュース記事をランク付けする方法。最も関連する答えを得るために、エンベディングとコサイン類似度を使用します。比較は元のクエリと行われます。
最後に、LLMに元のユーザークエリを尋ねて何が起こるかを見ます:"最近ビットコインの価格に影響を与えたイベントは何ですか?"
1. 二つのインターフェースを呼び出します:OpenAI API 3.5とNewsAPI
NewsAPI.orgは、開発者が世界中のさまざまなニュースメディアからリアルタイムのニュース記事を検索し、取得できるようにするシンプルで使いやすいAPIを提供するオンラインサービスです。特定のキーワード、フレーズ、タグを検索したり、日付、言語、ニュースソースでフィルタリングしたりすることができます。このツールは、ニュース関連のアプリケーションやリアルタイムでニュースを更新する必要があるウェブサイトにとって非常に便利です。
必要なライブラリをインストールします。
2. GPT-3.5を使用してクエリのプロンプトを作成
def get_completion_gpt(input, gpt_model="gpt-3.5-turbo-1106"):
# Make the API request
completion = client.chat.completions.create(
model= gpt_model,
messages=[
{"role": "system", "content": "Output only vaild JSON"},
{"role": "user", "content": input},
],
response_format={"type":"json_object"}
)
text = completion.choices[0].message.content
parsed = json.loads(text)
return parsed
user_query = "What are the events that impacted the bitcoin price lately?."
input = f"""
You have access to a search NEWS API that returns recent news articles.
Make a list of search questions that match this topic.
Try using different keywords that are related to the topic to make your
questions more general.
Create many queries, some with specific terms and others without them.
Be imaginative and make as many queries as you can. More queries will help you
find better results.
Pick 10 of these queries.
For example, you can include queries like ['keyword_1 keyword_2', 'keyword_1',
'keyword_2'].
# User question: {user_query}
# Format: {{"queries": ["query_1", "query_2", "query_3"]}}
"""
gpt_model = "gpt-3.5-turbo"
parsed = get_completion_gpt(input, gpt_model)
parsed
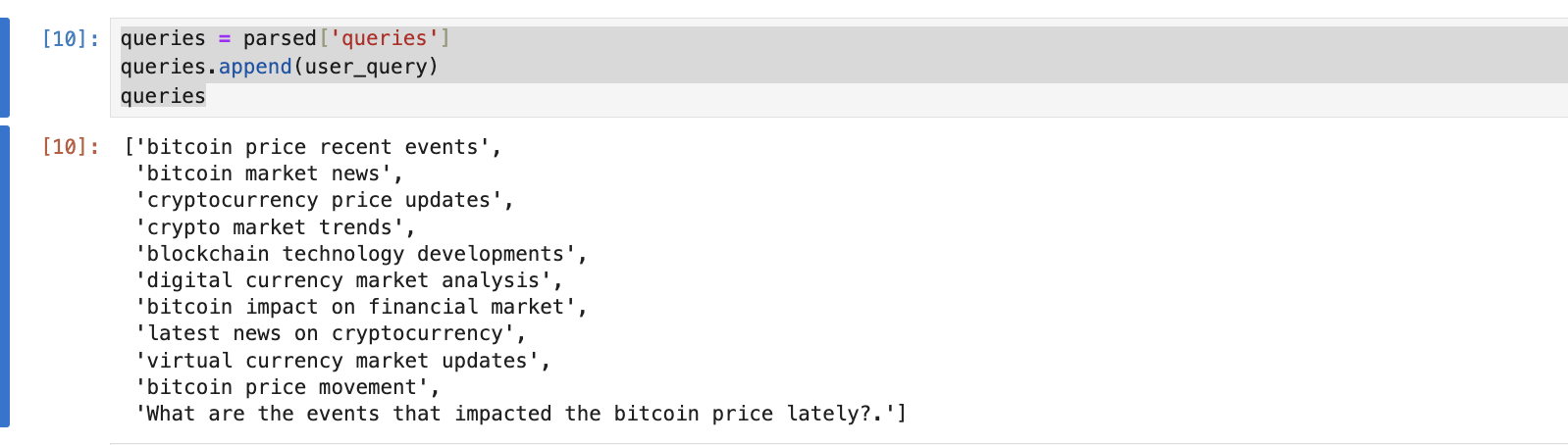
このコードの目的は、ユーザーのクエリに関連する一連の検索質問を生成することです。これらの質問は、最近のニュース記事を返すニュースAPIを検索するために使用されます。
具体的には、ユーザーの質問は「What are the events that impacted the bitcoin price lately?」です。
このコードの動作は、ユーザーの質問を含むテキストをGPT-3.5-turboモデルに入力し、そのモデルが主題に関連する一連の検索質問を生成することです。これらの質問は、ニュースAPIをより広範で具体的に検索し、ユーザーの質問に関連するニュース記事を取得するのに役立ちます。
例えば、ユーザーが最近ビットコインの価格に影響を与えたイベントについて知りたい場合、生成されるクエリは、"Bitcoin price drop news", "Bitcoin market influencers", "Recent Bitcoin market events" などになる可能性があります。最後に、コードは生成されたクエリから10個を選びます。
3.newsapi
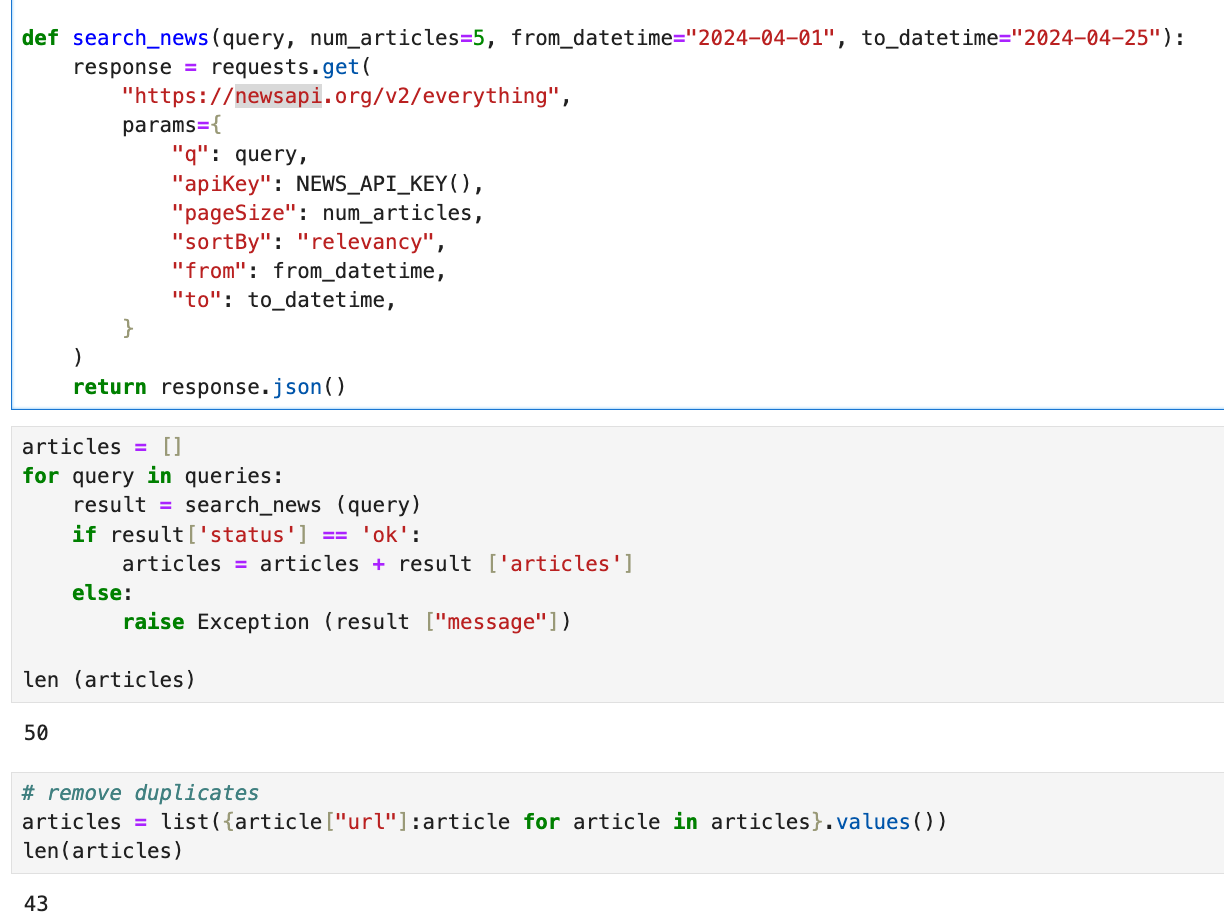
4.Re-rank
hypoth_answer =f"""
"Make up
an answer to the user's question. We'll use this made-up answer tou sort the search results.
Imagine you have all the details to answer, but don't use real facts.
Instead, use things like 'EVENT affected something' or 'NAME mentionedu
"something on DATE' as placeholders.
User question: {user_query}
Format: {{"hypotheticalAnswer": "hypothetical answer text"}}
"""
parsed_hypothet_answer = get_completion_gpt (hypoth_answer)
parsed_hypothet_answer
hypoth_answer_11m = parsed_hypothet_answer ['hypotheticalAnswer']
hypoth_answer_11m
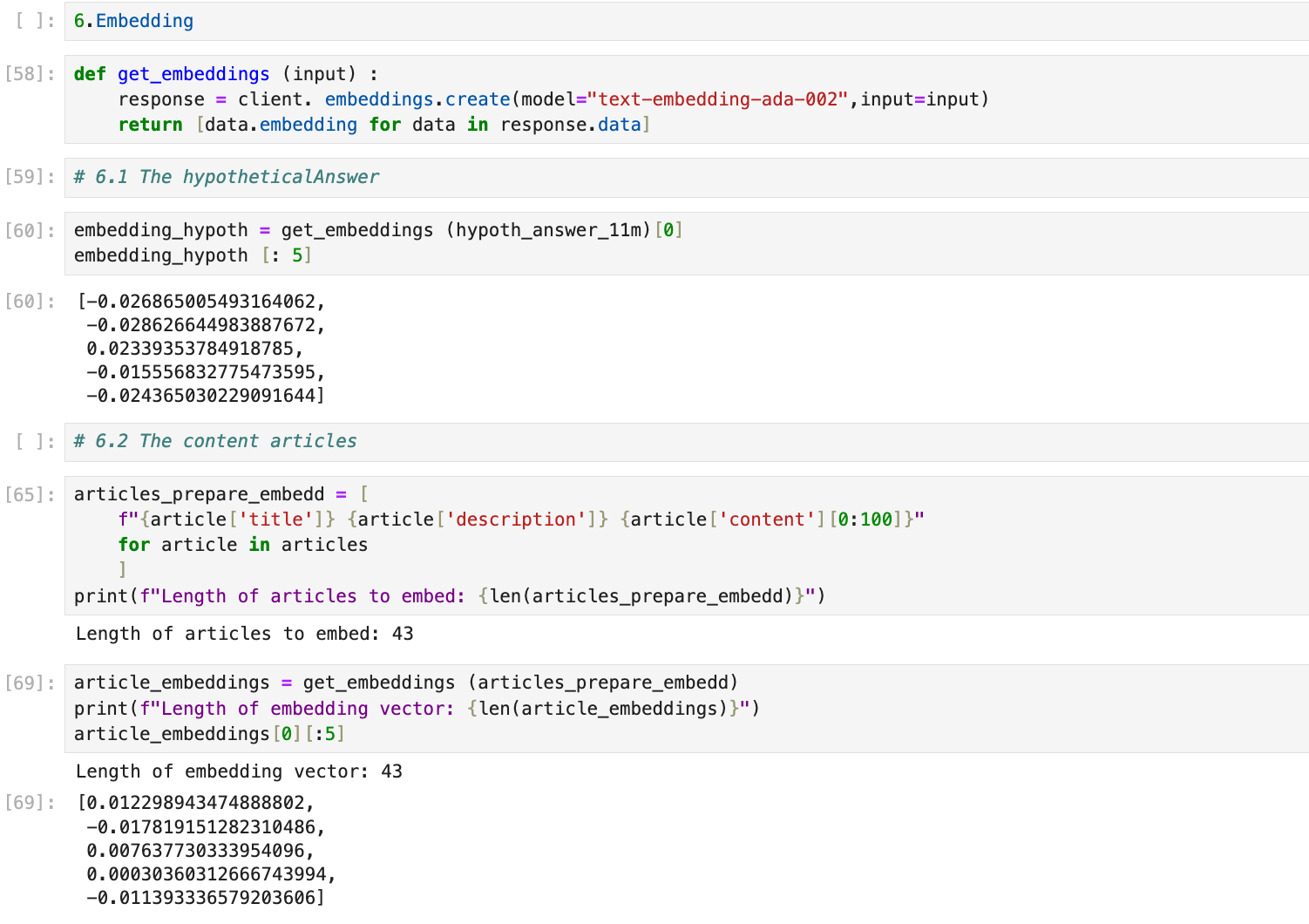
5.Embedding
def get_embeddings (input) :
response = client. embeddings.create(model="text-embedding-ada-002",input=input)
return [data.embedding for data in response.data]
6.類似度検索アルゴリズム や 最も関連するドキュメント
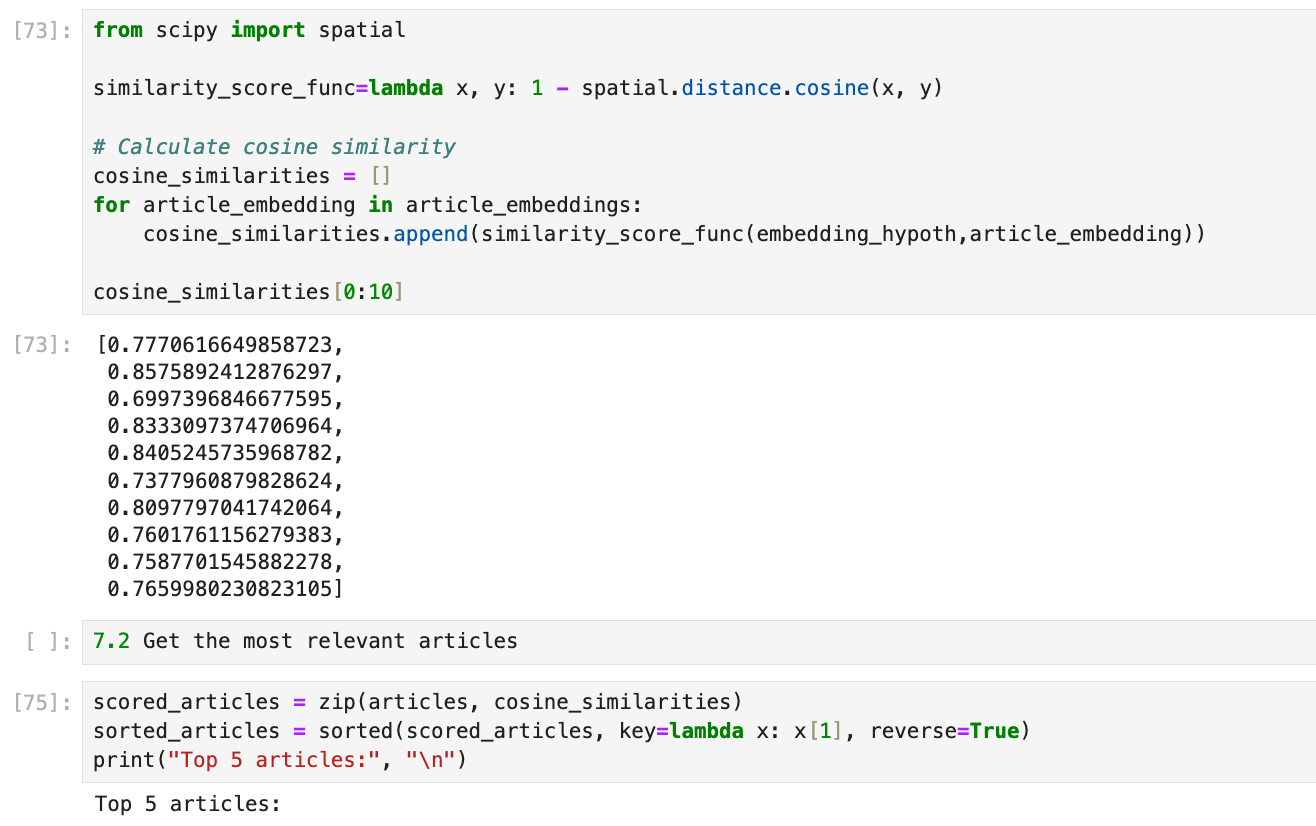
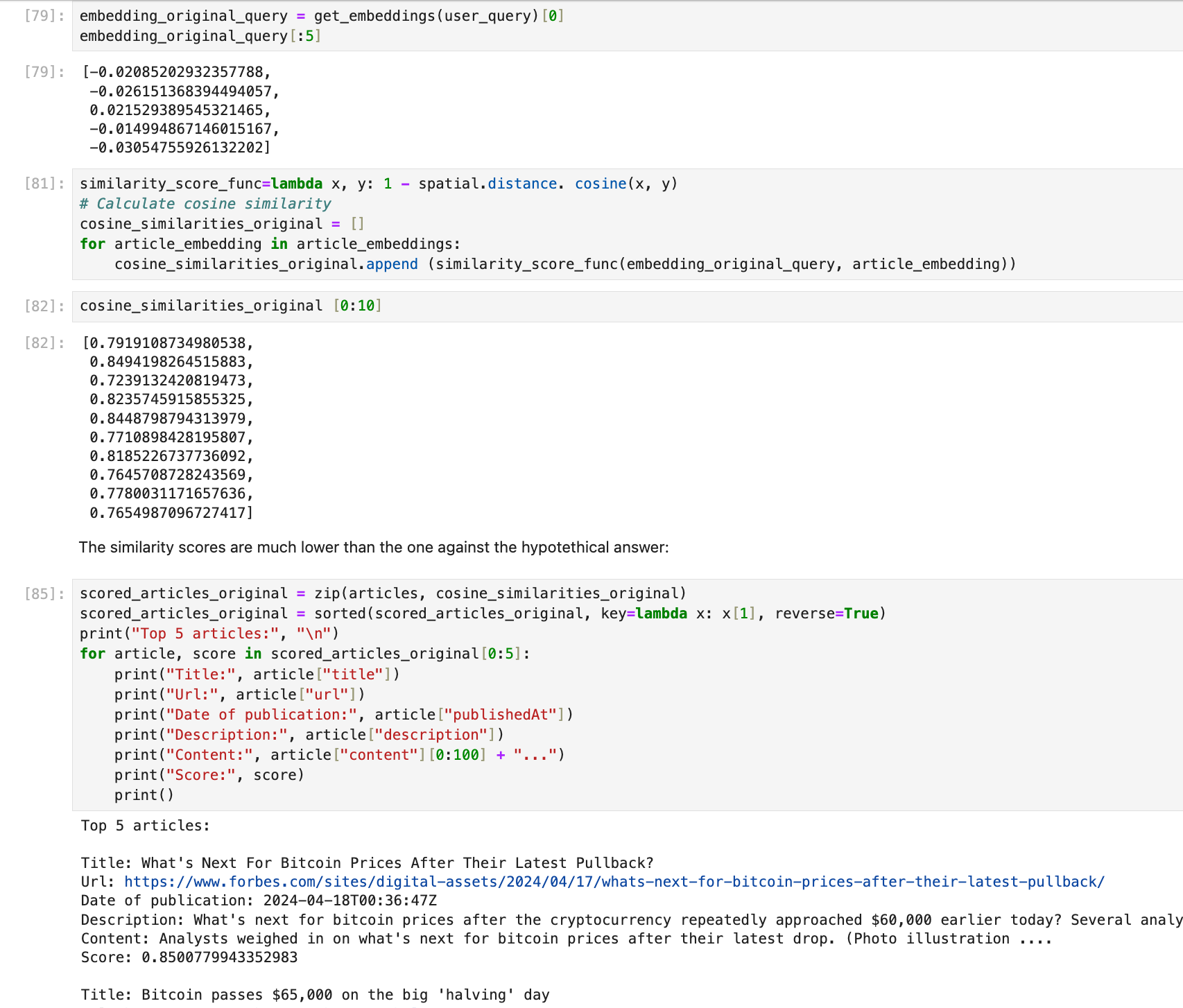
生成結果
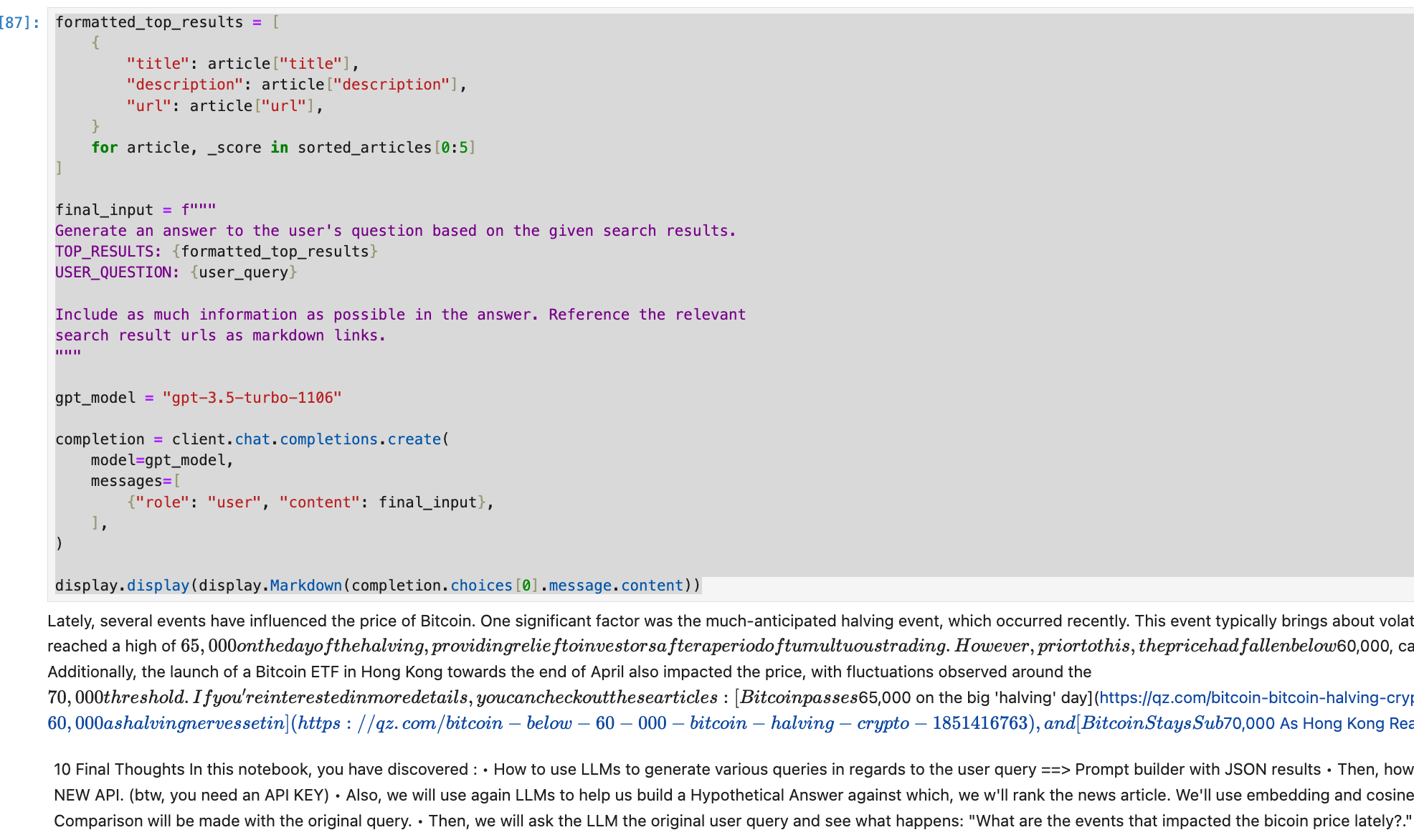
final_inputでは、これらの検索結果とユーザーの質問に基づいて答えを生成するように指示します。答えには可能な限り多くの情報を含め、関連する検索結果のURLをマークダウンリンクとして参照するように指示しています。