これは https://qiita.com/advent-calendar/2018/ios2 の22日目の記事です。
WWDC 2018のセッション What's New in Swift にて、Swift 4.2は「small string optimization」を行なっていることが紹介された。
概要としては、15文字までの文字列を、ヒープを消費せずにスタックに確保できるというものである。また、以前は24バイトを占めていたが16バイトに短縮されたとのこと。
どういう実装になっているか気になったので少しだけ調べてみた。また、Objective-Cでも短い文字列が特別扱いされることがあるので、そちらについても調べた。
Swift 4.2 (Xcode 10.1)
デバッガで観察する
print文にブレークを張って実行する。
import Foundation
class SmallStringTest {
init() {
let str = "0123456789abc"
print(str)
}
}
見たい変数(str)を右クリックして「View Memory of "str"」をクリック
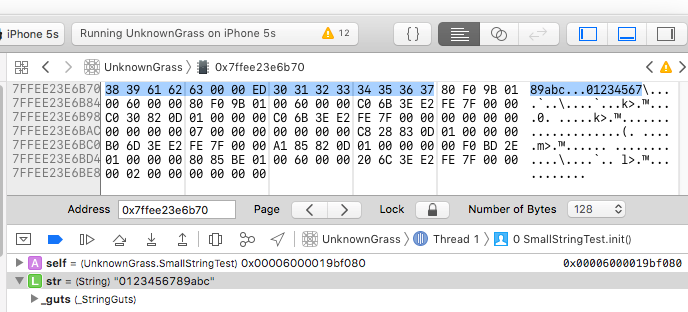
今回の文字列"0123456789abc"は、38 39 61 62 63 00 00 ED 30 31 32 33 34 35 36 37のように格納されているようだ。
なお0x7FFEE23E6B70は、register readしてみて、EBP(スタックフレームを指すレジスタ、シミュレータの場合)の値に近いので、ヒープではなくスタックであろう。
ちなみに、試した限りではmacOSでもiOSでも同じ値(0xED...)にエンコードされるようである。
※ macOSやiOSはlittle endianなので、1ワードの値は下位から格納される。0x123456789ABCDEF0という値は、バイト単位だとF0 DE BC 9A 78 56 34 12という順番で格納される。今回の場合、先頭の1ワード(64ビット、8バイト)は38 39 61 62 63 00 00 EDなので、内部のUInt64の値としては0xED00006362613938となる。
ソースコード
なんとなく探したところ、これが該当するクラスの実装のようである。
https://github.com/apple/swift/blob/master/stdlib/public/core/SmallString.swift
leadingRawBitsとtrailingRawBitsという二つの64ビットの値により一つの文字列を表現する。
先頭の8文字まではleadingRawBitsに、後半の7文字とdiscriminator(後述)がtrailingRawBitsに格納されている。0から15までのどの長さでも16バイトを占めるようである。
trailingRawBitsの最上位の4ビットの部分はdiscriminatorと呼ばれており、オブジェクトの種類を判別するのに使われている。
StringObject.swiftに種類の説明が載っている。(下図)
| Form | b63 | b62 | b61 | b60 |
|---|---|---|---|---|
| Immortal, Small | 1 | ASCII | 1 | 0 |
| Immortal, Large | 1 | 0 | 0 | 0 |
| Native | 0 | 0 | 0 | 0 |
| Shared | x | 0 | 0 | 0 |
| Shared, Bridged | 0 | 1 | 0 | 0 |
| Foreign | x | 0 | 0 | 1 |
| Foreign, Bridged | 0 | 1 | 0 | 1 |
これによるとASCIIのsmall string上位4ビットは1110なので、16進数だと0xE???????????????となる。
次の4ビットに長さが入るようである。上の例だと0xEDの0xEがimmortal, small, ASCIIを、0xDが長さが13を示している。
leadingRawBitsは_storage.0となっているので、メモリ上は先に来そうな気がするが、実際のメモリレイアウトとしてはtrailingRawBitsが先に格納されている。
おそらくオブジェクトを読み込むとき、まず先頭の8バイトを読み込み、discriminatorがsmall stringだったら、追加で8バイトを読み込むようになっているのではないかと思うが、逆にしている部分を見つけることができなかった。(TODO)
StringObjectにはこんな図があったが、これはSwift 4.2の現況とは少し違う気がする。
┌───────────────────────────────┬─────────────────────────────────────────────┐
│ _countAndFlags │ _object │
├───┬───┬───┬───┬───┬───┬───┬───┼───┬───┬────┬────┬────┬────┬────┬────────────┤
│ 0 │ 1 │ 2 │ 3 │ 4 │ 5 │ 6 │ 7 │ 8 │ 9 │ 10 │ 11 │ 12 │ 13 │ 14 │ 15 │
├───┼───┼───┼───┼───┼───┼───┼───┼───┼───┼────┼────┼────┼────┼────┼────────────┤
│ a │ b │ c │ d │ e │ f │ g │ h │ i │ j │ k │ l │ m │ n │ o │ 1x0x count │
└───┴───┴───┴───┴───┴───┴───┴───┴───┴───┴────┴────┴────┴────┴────┴────────────┘
Objective-C
tagged pointer
64bit環境のObjective-Cでは、tagged pointerが導入された。NSObjectのidは通常、ヒープやスタックのオブジェクトを取得するための(間接的な)情報であるが、そのかわり、idとして特定の型の値そのものを保持する仕組みである。macOSについては「mikeash.com: Friday Q&A 2015-07-31: Tagged Pointer Strings」に、iOSでは「64bit環境におけるObjective-Cのポインタ」などに解説がある。これにより、ヒープを消費せずにNSNumberやNSStringを保持したり渡したりできる。
NSTaggedPointerString
NSStringのtagged pointer版がNSTaggedPointerStringである。64ビットのうち、1ビットがtagged pointerかどうか(macOSの場合最下位ビット、iOSの場合最上位ビット)、3ビットがtag(macOSの場合bit1-3、iOSの場合bit60-62)、4ビットが長さ(macOSの場合bit4-7、iOSの場合bit0-3)で、残りの56ビットにデータが入る。
NSTaggedPointerStringの場合、flagの部分が1で、tagの部分に010が入る。すなわちmacOSなら下位4ビットが0101(16進数だと0x???????????????5)、iOSなら上位4ビットが1010(16進数だと0xA???????????????)となる。(下図参照)
"a"はmacOSなら0x0000000000006115、iOSだと0xA000000000000611である。
macOS
| payload | length | tag | tagged pointer flag |
|---|---|---|---|
| 56bit | 4bit | 3bit(010) | 1bit(1) |
iOS
| tagged pointer flag | tag | payload | length |
|---|---|---|---|
| 1bit(1) | 3bit(010) | 56bit | 4bit |
なお文字列定数はNSTaggedPointerStringにならない。以下のようにNSMutableStringから作ることができる。
NSString *a = [[@"a" mutableCopy] copy];
NSLog(@"a: %@, class: %@", a, a.class);
デバッガ(Xcode、lldb console)からも以下のようにすると、文字列がどんな値にエンコードされるか確認できる。
p [(NSObject *)[@"a" mutableCopy] copy]
iOS 12以外
NSTaggedPointerStringは割とカオスな実装になっており、以下のように長さで場合分けされている。
- 長さが0から7のとき: 1文字が8ビット
- 長さが8か9のとき: 1文字が6ビット
- 長さが10か11のとき: 1文字が5ビット
文字列の長さが7以下のときにはASCIIコードがそのまま入っている。一方、謎の変換テーブルが存在していて、長さが8以上の場合は文字列が謎テーブルに含まれる文字だけで構成されているときだけNSTaggedPointerStringにすることができる。
たとえばmacOSで10文字以上の場合のデコードをC++で書くとこんな感じになる。
static string decode_macos_tagged_pointer_string_10_11(uint64_t a) {
int length = (a >> 4) & 15;
string result;
for (int i = 0; i < length; ++i) {
result += "eilotrm.apdnsIc ufkMShjTRxgC4013"[(a >> (8 + (length - i - 1) * 5)) & 31];
}
return result;
}
謎テーブルは"eilotrm.apdnsIc ufkMShjTRxgC4013bDNvwyUL2O856P-B79AFKEWV_zGJ/HYX"という長さ64の配列(文字列)で、長さが8か9のときには全部を、長さが10か11のときには前半32個を使う。
たとえばhellohelloは格納できるがhelloworldは収まらない。
iOS 12
iOS 12のNSTaggedPointerStringは、iOS 11以前とは別の実装になっているようである。
iOS 10.3.3 (device)
(lldb) p [(NSObject *)[@"a" mutableCopy] copy]
(NSTaggedPointerString *) $0 = 0xa000000000000611 @"a"
iOS 11.0.1 (simulator)
(lldb) p [(NSObject *)[@"a" mutableCopy] copy]
(NSTaggedPointerString *) $0 = 0xa000000000000611 @"a"
iOS 11.2.1 (device)
(lldb) p [(NSObject *)[@"a" mutableCopy] copy]
(NSTaggedPointerString *) $0 = 0xa000000000000611 @"a"
iOS 12.1 (simulator)
(lldb) p [(NSObject *)[@"a" mutableCopy] copy]
(NSTaggedPointerString *) $0 = 0xfcfde2aaa91c0f75 @"a"
iOS 12.1 (device)
(lldb) p [(NSObject *)[@"a" mutableCopy] copy]
(NSTaggedPointerString *) $0 = 0x8fa505414de577e9 @"a"
ビットの割り当てはおおむねiOS 11以前に近いようだが、同じ文字列に対して複数の結果が返ってくる。
なぜこうなっているのか不明であるが、値のトラッキングをするときに不便だったりするのだろうか。
まだデコードに成功していないので、そのうちやってみたいと思う。
ちなみにNSTaggedPointerStringのソースコードは非公開のようである。
その他
ブリッジ
small stringやNSTaggedPointerStringは、その言語のランタイムで閉じているため、別のランタイムに渡すときには変換が行われる。
Swiftからsmall stringをObjective-Cに渡すと、NSTaggedPointerStringになることがある。逆に、NSTaggedPointerStringをSwiftに渡すと、small stringとなる。
参考
- https://github.com/apple/swift/tree/master/stdlib/public/core
- https://opensource.apple.com/
- WWDC 2018 - Videos - Apple Developer
- mikeash.com: Friday Q&A 2015-07-31: Tagged Pointer Strings
- 64bit環境におけるObjective-Cのポインタ
修正点
- 2018/12にSwiftのdiscriminatorが8ビットから4ビットに減った。その結果フィールド名がcountAndDiscriminatorという名前に変わった。small stringは後続の4ビットも使うので、エンコーディングしたときの値としては変わらない。(Thanks to @omochimetaru)