データ分析の仕事をしていると、最初にあのクエリを叩いてテーブル1を作り、次にこのクエリを叩いてテーブル2を作り、その次にこのクエリを叩いて・・・(以下、同文)という場面が多い。
これを手動で管理することは中々の手間であるし、ミスを誘発するので品質的にも問題になり得る。
こういった依存性のあるタスクをmakeで管理する方法をまとめておく。
makeとは
あるファイルを入力として別のファイルを作る、さらに、そのファイルを入力としてまた別のファイルを作る、さらに・・・(以下、同文)という状況をコンピュータに自動で管理させるためのツールである。
典型的には、C言語/C++言語のソースコードをコンパイルしてオブジェクトファイルを作る、それらを集めてライブラリファイルを作る、あるいはリンクして実行ファイルを作る、という作業を管理する為に使われる。
ソースコードのコンパイルというのは(プロジェクトの規模がちょっと大きくなると)時間のかかるプロセスである。あるファイルを変更するたびに全体を再度コンパイルするというのは時間がもったいない。
したがって、あるファイルを変更した際に、その変更によって影響を受ける部分だけをコンパイルし直して、その他は既にできているものを使えると便利である。
makeが行うのは、正にこういうことである。
例
例として、あるプログラムexeを作成するのに
- b.h, c.h, main.cppからmain.oを作る
- b.h, b.cppからb.oを作る
- c.h, c.cppからc.oを作る
- main.o, b.o, c.oから
exeを作る
という手順が必要だとする。この手順を図で表すと下のようになる。四角いノードがソースコードで、丸いノードが生成物である。
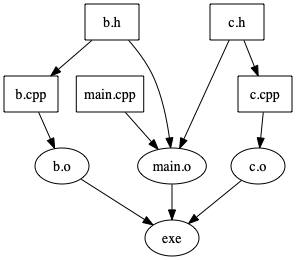
このプログラムの開発中にmain.cppだけを修正した場合、b.o, c.oには影響を与えないことが分かる。
したがって、main.cppだけを変更した場合には、b.o, c.oは既存の物を使い回し、main.o, exeだけを再作成すれば良い。
数個のファイルであれば、このような依存関係を手動で管理できないこともないが、ソースコードの数が数十・数百というオーダーになると手動での管理は現実的ではない。
こういう状況を計算機で適切に管理したい、というのがmakeというプログラムが生まれた背景である(多分)。
必要なプロセスを判定する基準
makeを使う時には、Makefileというファイルに作業の手順を記述する。Makefileの中で、各手順は
- ターゲット(生成物)
- ソースファイル(ターゲットを作る為に必要なファイル)
- コマンド (ターゲットを入力から作るためのコマンド)
の3つで記述される。例えば上の例の手順をMakefileに書くと、
exe: main.o b.o c.o
g++ main.o b.o c.o -o exe
main.o: main.cpp b.h c.h
g++ -c main.cpp
b.o: b.cpp
g++ -c b.cpp
c.o: c.cpp
g++ -c c.cpp
という感じになる。一般的に書くと、
<ターゲット>: <ソースファイル>
[コマンド]
という形で手順を記述する。必要であれば、ソースファイル・実行コマンドは複数並べることができる。また、Makefileの文法上、上記の[コマンド]のインデントは重要である。このインデントは、スペースではなくタブ文字でなければならない。
makeを実行すると、Makefileの中で一番上のターゲットを作成しようとする。もし、そのターゲットを作成する為に他のターゲットが必要であれば、それらは再帰的に自動的に作成される。
各ターゲットを作成する際、ターゲットとソースファイルのタイムスタンプを比較し、ターゲットの方が古い場合にのみ、実行コマンドが実行される。
各ターゲットを作成する際、ターゲットとソースファイルのタイムスタンプを比較し、ターゲットの方が古い場合にのみ、実行コマンドが実行される。
大事なことなので2回言いました。
makeの例
簡単な例として、次のようなMakefileで動作を確認してみる。
コマンドの頭に@を付けると、実行時にコマンドの出力だけを表示しコマンド自体は表示しなくなる。
product: intermediate1 intermediate2
@echo "building product"
cat intermediate1 intermediate2 > product
intermediate1: source1
@echo "building intermediate1"
echo "this line is added" | cat source1 - > intermediate1
intermediate2: source2
@echo "building intermediate2"
echo "this line is added" | cat source2 - > intermediate2
コマンド自体には実質的な意味が全く無いが、
- source1からintermediate1が作られる
- source2からintermediate2が作られる
- intermediate1, intermediate2からproductが作られる
というプロセスの例になっている。
まず、適当な空のディレクトリを用意して、テキストエディタでMakefileを作成し、上の内容を書いて保存する。ターミナルで当のディレクトリに移動し、
$ make
を実行すると、
make: *** No rule to make target `source1', needed by `intermediate1'. Stop.
というエラーメッセージが出る。intermediate1を作るのに必要なsource1がないので停止する、と言っている。
そこで、source1を用意した上で、もう一度makeを実行する。
$ echo "original line" > source1
$ make
すると、
building intermediate1
echo "this line is added" | cat source1 - > intermediate1
make: *** No rule to make target `source2', needed by `intermediate2'. Stop.
上のようなメッセージが表示される。 ここで次の2点に注意する。
-
building intermediateという表示に続いて、 intermediate1 を作成するコマンドが実行されている。 -
intermediate2を作るのに必要なsource2がないので停止する、と言っている。
実際、ディレクトリの中を確認すると
$ ls
Makefile
intermediate1
source1
$ cat intermediate1
original line
this line is added
と、 intermediate1が作成されていることが分かる。 source2を作成し、さらにmakeを実行してみる。
$ echo "original line" > source2
$ make
building intermediate2
echo "this line is added" | cat source2 - > intermediate2
building product
cat intermediate1 intermediate2 > product
メッセージを見ると、
- intermediate1の作成コマンドは実行されていない
- intermediate2の作成コマンドが実行されている
- productの作成コマンドが実行されている
ことが分かる。先に書いた通り、makeは再作成が必要なターゲット( = ソースのタイムスタンプよりも古いターゲット)のみを再作成する、という動作をする。 intermediate1は既に作成済みのため、そのコマンドは実行されていない。
productの中身を確認すると、
$ cat product
original line
this line is added
original line
this line is added
ちゃんとMakefileに記述した通りの動作が行われていることが分かる。
この状態でもう一度makeを実行すると
$ make
make: `product' is up to date.
producutは既に存在し、それを作る為に必要な全てのソースファイルよりも新しいというメッセージが出て、再作成は行われない。
source1だけを更新し、再度makeを実行すると
$ echo "this line is updated" > source1
$ make
building intermediate1
echo "this line is added" | cat source1 - > intermediate1
building product
cat intermediate1 intermediate2 > product
- source1が更新されたので、intermediate1は再作成される
- intermediate2の元となるsource2は変更されていないので再作成されない
- productを作るのに必要なintermadiate1が更新されたので、productは再作成される
ということが起こる。productの中身を確認すると、
this line is updated
this line is added
original line
this line is added
キチンと新しい内容になっている。
まとめ
- makeは、依存性のあるタスクを自動で管理するツール
- ターゲットを作成する為に必要なソースと、作成するためのコマンドをMakefileに記述する
- タイムスタンプを比較し、更新が必要なターゲットのみが作成される
- ターゲット間の依存関係に基づいて、最終成果物を作成する為に必要なターゲットのみを自動的に把握し作成する
一連のクエリをmakeで管理する
何らかの分析アウトプットを出す為に、1.sql, 2.sql, ..., 5.sqlという5個のクエリを順番にBigQueryで実行する必要があるとする。
そんな時は、
table.5: 5.sql table.4
cat 5.sql | bq query
touch table.5
table.4: 4.sql table.3
cat 4.sql | bq query
touch table.4
table.3: 3.sql table.2
cat 3.sql | bq query
touch table.3
table.2: 2.sql table.1
cat 2.sql | bq query
touch table.2
table.1: 1.sql
cat 1.sql | bq query
touch table.1
こういうMakefileを作っておくと、
$ make
と1つのコマンドを叩くだけで、1.sqlから5.sqlまで順番に実行してくれる。さらに、「あかん、3番目のクエリ間違っとるやんけ」という状況になっても、3.sqlを編集して再度
$ make
と1つのコマンドを叩くだけで、再実行が必要な3.sql, 4.sql, 5.sqlだけを実行してくれる。
ルールを追加するのが面倒臭い
上のように、各sqlの実行ルールをベタ書きしていると、sqlを追加する都度、Makefileの編集が必要になる。自動変数やマクロといったmakeの機能を使えば、そういったことも自動化できるんだが、長くなったので別のエントリで書く。