最近の Web サービスでよくある「下までスクロールしたら次のコンテンツを読み込む(オートページャライズ)」を実装するためには、当然ですが「下までスクロールしたかどうか」を検出する必要があります。
これが簡単そうに見えて意外と面倒臭く、自分も毎回思い出すのに時間がかかってしまいます。
御託はいいから結論を先に言え
これでよさそう
function getScrollBottom() {
var body = window.document.body;
var html = window.document.documentElement;
var scrollTop = body.scrollTop || html.scrollTop;
return html.scrollHeight - html.clientHeight - scrollTop;
}
以下、解説です
どんな値が取得できるか
まず、使いそうな要素
-
document.bodybody 要素 -
document.documentElement文書全体を表す要素 (html要素)
ややこしいので、これ以降では body と書いてあったら document.body, html と書いてあったら document.documentElement のことだと思ってください。
次に、使いそうなプロパティ
-
scrollTop要素内のスクロール量 -
clientHeight要素の高さ -
scrollHeight要素内のスクロールできる高さ
clientHeight と scrollHeight は何が違うんじゃ、って話ですが、要素の高さを超えるくらい要素の内容が多い場合、要素そのものの高さが clientHeight で要素の内容の高さが scrollHeight になります。
しかし僕はあまり頭がよくなく、「そんなこと言われてもよくわからん、直感的にわかるようにして!!!」という感じだったので、こういうツールを作りました。
スクロールしたり body の高さを変えてみたりすることで、それぞれの値がどう変化するのかがわかると思います。
スクロール量を取得する
scrollTop には罠があって、ページ全体のスクロール量を取得したい場合は ブラウザによって取得方法が違います。
- WebKit 系 ( Safari, Chrome 等) や Edge では
body.scrollTop - IE, Firefox, Opera などでは
html.scrollTop
ブラウザの対応していない方法で取得しようとする(例えば Firefox の document.body.scrollTop)と、必ず 0 が返ってきます。
そのため、正しくスクロール量を取得するためには
var body = document.body;
var html = document.documentElement;
var scrollTop = body.scrollTop || html.scrollTop;
こうする必要があります。
ちなみに、scrollTop だけでなく body.scrollHeight もブラウザによって値が変わるのであまり使わないほうがよさそうです。
計算する
必要な値が取得できたので、あとは計算するだけです。
ここで気をつけないといけないのは、コンテンツ量によって body の高さが変わるので body の高さが画面のよりも長い場合と短い場合の両方に対応できるようにしたほうがいいということです。
body が長い場合
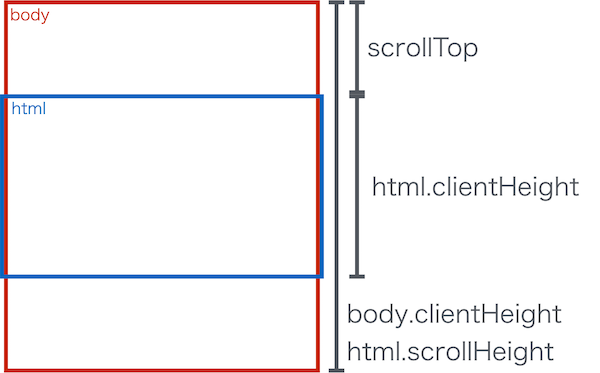
body が長いとき、「ドキュメント全体の高さ」は body.clientHeight または html.scrollHeight で取得することができます。
つまり「下からのスクロール位置」は
scrollBottom = (ドキュメント全体の高さ) - scrollTop - html.clientHeight
このように求めることができます。
body が短い場合

body が短いときは、そもそもスクロールしないので「下からのスクロール位置」は常に 0 であってほしいと思います。
scrollBottom = (ドキュメント全体の高さ) - scrollTop - html.clientHeight
この式に当てはめると、期待する scrollBottom は 0 で scrollTop はこの場合は常に 0 なので、(ドキュメント全体の高さ) == html.clientHeight のときに期待する値が得られそうです。
(ドキュメント全体の高さ) は body.clientHeight と html.scrollHeight のいずれかだったので、このうち (ドキュメント全体の高さ) == html.clientHeight を満たすのは html.scrollHeight のみとなります。
ということで、ドキュメント全体の高さを取得するには html.scrollHeight を使うと良さそうです。
つまり、
scrollBottom = html.scrollHeight - scrollTop - html.clientHeight
これで「下からのスクロール位置」を求めることができそうです。
これをちゃんとした JavaScript に直すと、冒頭に書いたコードになります。
オマケ
var scrollBottomEvent = window.document.createEvent('UIEvents');
scrollBottomEvent.initUIEvent('scrollBottom', true, false, window, 1);
window.document.addEventListener('scroll', function() {
var body = window.document.body;
var html = window.document.documentElement;
var scrollTop = body.scrollTop || html.scrollTop;
var scrollBottom = html.scrollHeight - html.clientHeight - scrollTop;
if ( scrollBottom <= 0 ) {
window.document.dispatchEvent( scrollBottomEvent );
}
});
こういうカスタムイベントを作っておくと
document.addEventListener('scrollBottom', function() {
// 下までスクロールしたときの処理
});
下までスクロールしたときのイベント処理がシンプルに書けて便利です。