Pandas DataFrame の任意の場所に列を追加したい場合は pandas.DataFrame.insert を使うと実現できるが、いくつか不満がある。
- immutable でない (DataFrame が直接書き換えられてしまう / 破壊的メソッドである / inplace オプションがない)
- 追加場所をインデックスの数値で指定しなければいけない
- わかりにくい
- 「col1 の後に追加」のような指定が難しい
- Series を入力しても name が無視されるため、別途指定する必要がある
- DataFrame を入力できない
これらを解決するような便利関数を書いた。
実装
from typing import Union, Optional
import pandas as pd
def insert_columns(
df: pd.DataFrame,
data: Union[pd.Series, pd.DataFrame],
*,
before: Optional[str] = None,
after: Optional[str] = None,
allow_duplicates: bool = False,
inplace: bool = False,
) -> pd.DataFrame:
if not inplace:
df = df.copy()
if not (after is None) ^ (before is None):
raise ValueError('Specify only "before" or "after"')
if before:
loc = df.columns.get_loc(before)
else:
loc = df.columns.get_loc(after) + 1
if type(data) is pd.Series:
df.insert(loc, data.name, data, allow_duplicates)
elif type(data) is pd.DataFrame:
for column in data.columns[::-1]:
df.insert(loc, column, data[column], allow_duplicates)
return df
-
beforeまたはafterにはカラム名を指定する - デフォルトでは入力された DataFrame を直接書き換えない
-
inplace=Trueを指定すれば直接書き換える
-
使い方
サンプルデータとして sklearn の iris データセットを使う。
from sklearn import datasets
iris = datasets.load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
target = pd.Series(iris.target_names[iris.target], name='target')
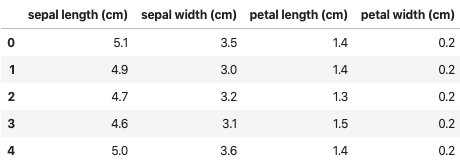
df.head()
target.head()

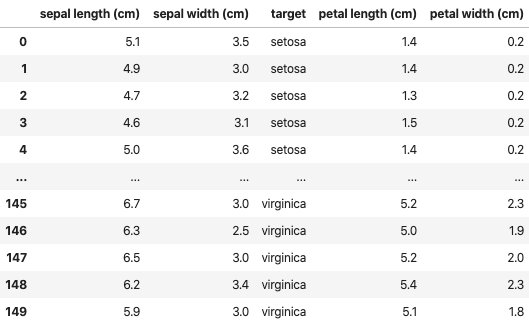
df の sepal width (cm) の後ろに target を追加してみる。
insert_columns(df, target, after='sepal width (cm)')
この例では Series を追加しているが、DataFrame も指定できる。