JXA で遊んでいたら iTunes で登録している曲一覧データがとれたので、集計してみた。
参考: 知らないうちにMacがシステム標準でJavaScriptで操作できるようになってた (JXA) - Qiita
iTunes の曲リストを取得する
JXA で曲リストを取得するにはこの6行だけでいける。
function run() {
const itunes = Application('iTunes');
const music = itunes.playlists[1];
const tracks = music.tracks.properties();
return JSON.stringify(tracks);
}
Application('iTunes') で iTunes.app にアクセスするためのオブジェクトを取得して、2番目のプレイリスト (index でいうと 1 番目) からトラック一覧を取得する。
なぜ2番目かというというのは以下のコマンドを実行してみればわかるが、
$ osascript -l JavaScript -e "Application('iTunes').playlists.name()"
ライブラリ, ミュージック, ミュージックビデオ, ムービー, テレビ番組, Podcast, オーディオブック, ...
iTunes のプレイリストは ライブラリ, ミュージック, ミュージックビデオ, ムービー, ... と続いていて、後半にユーザ定義のプレイリストが並んでいる。
そのためすべての音楽データのプレイリスト (ミュージック) を取得したい場合は2番目のプレイリストにアクセスすればよい。
この全曲のリストを JSON として吐き出す。
$ osascript -l JavaScript getAllTracks.js > tracks.json
データを JSON として吐き出すことができたので、あとは煮るなり焼くなり好きなようにできる。
曲リストを Python で読み込む
おもむろに Jupyter Notebook を開いて、吐き出した JSON を Pandas DataFrame として読み込む。
import pandas as pd
with open('tracks.json', 'r') as f:
df = pd.read_json(f).set_index('id')
df.sample(5)
たくさん (60種類以上) のカラムがあるが、それぞれのカラムの意味は スクリプトエディタ.app を起動して ウィンドウ > ライブラリ > iTunes から Track クラスのドキュメントを探せば書いてある。(英語)
曲名やアルバム名などの情報だけではなく、iTunes に追加した日時や再生回数などの利用情報も取得できる。
集計する
色々な数をカウント
print('曲数:', len(df))
print('アルバム数:', len(df.album.unique()))
print('アーティスト数:', len(df.albumArtist.unique()))
print('総再生回数:', df.playedCount.sum())
print('総再生時間:', (df.time * df.playedCount).sum())
曲数: 7848
アルバム数: 818
アーティスト数: 239
総再生回数: 39770
総再生時間: 119 days 02:15:05
今までに iTunes で聞いた音楽の総合計時間は約3ヶ月らしい。自分が iTunes に移行したのが8年前なので、この8年間のうち約 3% の時間を音楽を聴きながら過ごしていることがわかる。
曲ごとの再生回数のヒストグラム
ax = df.playedCount[df.playedCount <= 40].hist(bins=40)
ax.set_xlabel('再生回数')
ax.set_ylabel('曲数')
plt.show()
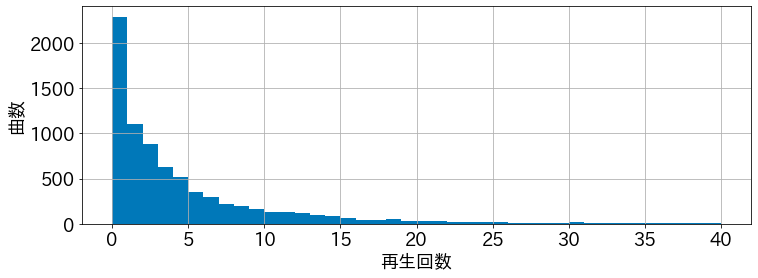
一度も再生したことない曲が2000曲以上ある。
ごめんて。
曲ごと再生回数 TOP 10
df.groupby('name') \
.apply(lambda df: pd.Series([df.albumArtist.iloc[0], sum(df.playedCount)], index=['artist', 'playedCount'])) \
.sort_values('playedCount', ascending=False) \
.head(5) \
.reset_index()
| name | artist | playedCount | |
|---|---|---|---|
| 0 | ホワイトノイズ | ラグジュアリー オルゴール | 369 |
| 1 | future nova -album edit- | School Food Punishment | 137 |
| 2 | 君の知らない物語 | supercell | 131 |
| 3 | 恋の煙 | チャットモンチー | 126 |
| 4 | ソラニン | ASIAN KUNG-FU GENERATION | 126 |
| 5 | サヨナラ絶望人生 | 空想委員会 | 101 |
| 6 | 真夜中遊園地 | チャットモンチー | 97 |
| 7 | ハロウシンパシー | シナリオアート | 96 |
| 8 | 少年少女 | amazarashi | 95 |
| 9 | Cherish | 大塚愛 | 94 |
「赤ちゃんはホワイトノイズを流しておくとよく寝る」説を信じて一時期ずっと夜中にホワイトノイズを流していたら再生回数トップになってしまった。ちなみにあまり寝てくれなかった。
アーティストごと再生回数 TOP 10
df.groupby('albumArtist')['playedCount'].sum() \
.sort_values(ascending=False).head(10).to_frame().reset_index()
| albumArtist | playedCount |
|---|---|
| 0 | amazarashi |
| 1 | ASIAN KUNG-FU GENERATION |
| 2 | 米津玄師 |
| 3 | VOCALOID |
| 4 | 空想委員会 |
| 5 | RADWIMPS |
| 6 | サカナクション |
| 7 | ヒトリエ |
| 8 | GOOD ON THE REEL |
| 9 | 凛として時雨 |
趣味がよく出ている感じがする。
「アジカンはいいぞ」と言おうとしたが amazarashi の方が上になってしまった。
お気に入り曲の割合
sum(df['loved']) / len(df)
0.18450560652395515
iTunes には「ラブ」という機能があり、気に入った曲にはこのフラグをつけるようにしているのだけど、集計してみると5曲に1曲くらいはお気に入りフラグが立っている。自分ちょろい。
年ごとの開拓した曲数
ax = df.dateAdded.dt.year.value_counts().sort_index().plot.bar()
ax.set_xlabel('年')
ax.set_ylabel('曲数')
ax.set_ylim(0, 1500)
ax.set_title('年ごとの開拓した曲数')
plt.show()
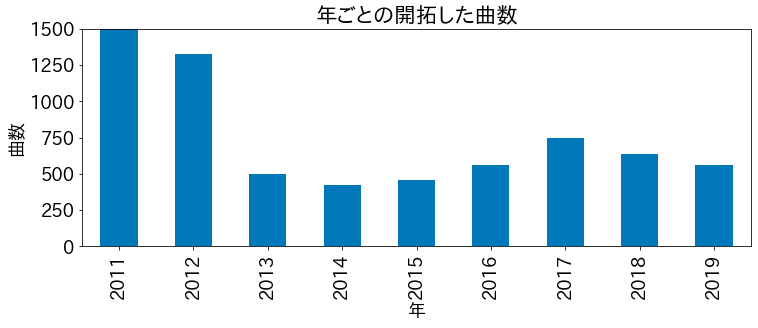
(2011年は iTunes に移行した年なのでノーカン)
毎年安定して 500 曲くらい新しい曲を開拓していることがわかる。
今年ハマっているアーティスト
df[df.dateAdded > '2019'].groupby('albumArtist')['playedCount'].sum() \
.sort_values(ascending=False).head(10).to_frame().reset_index()
| albumArtist | playedCount | |
|---|---|---|
| 0 | ヨルシカ | 133 |
| 1 | RADWIMPS | 87 |
| 2 | ヒトリエ | 63 |
| 3 | ねごと | 60 |
| 4 | サカナクション | 47 |
| 5 | BUMP OF CHICKEN | 39 |
| 6 | Base Ball Bear | 38 |
| 7 | 相対性理論 | 34 |
| 8 | ASIAN KUNG-FU GENERATION | 33 |
| 9 | 岡崎体育 | 31 |
今年は圧倒的にヨルシカにハマっている。
ヨルシカはいいぞ。
歌詞でワードクラウド
残念なことに iTunes の曲データにはデフォルトでは歌詞が含まれておらず、iTunes 上で歌詞を表示して歌詞をダウンロードしたことがある曲の歌詞データしか利用できない。
自分の曲データの中で歌詞が含まれていたものは 235 曲と少なかったものの、一応これでワードクラウドを作ってみた。
コードは長いので省略。(ググればいくらでもやり方はでてくる)
雑に MeCab で形態素解析して、ストップワードは NLTK (英語) + SlothLib (日本語) + 手作業でいくつか追加したものを使って、あとは wordcloud に投げた。

歌詞を投げただけあってだいぶエモっぽいワードが並んでいる。
思ったより普通な感じだったのでちょっと残念 (?)
まとめ
JXA を使うと iTunes からデータを引っこ抜けるので便利。
集計してみると「意外とこのアーティストよく聴いてるんだな」みたいなのに気付けたりして面白いので各位やってみるといいです。