機械学習の初心者がkaggleに挑戦していく様子を記録に残していきたいと思います.
しばらくは終了済のコンペティションに参加していきます.
この記事の概要
最初に色々紹介させていただきます.
自己紹介
情報系大学院を修了した,社会人一年目のIT屋です.(2021年6月現在)
プログラミング経験はpythonを五年ほどやってきましたが,主に量子プログラミングなどを主にしていました.統計や機械学習の勉強も軽く行なっており,勉強してきた書籍としては
などが挙げられます.
この記事を書く背景
新卒として入社し,すぐに量子コンピュータを武器にできるわけではないと感じました.そこで,すぐに使える武器を探したところ,過去に少しだけ触った機械学習を思い出しました.しかし,今まで触ってきたデータは綺麗に整えられたりしているもので実践的なデータではないと感じました.そこで本格的に機械学習をはじめるに当たってkaggleをやってみることにしました.
この記事の目的
kaggleを勉強していくに当たって,一番大変になりそうなのがモチベーションの維持でした.毎日,終業後にコーディングを行うのはサボりがちになってしまいそうだと思いました.そこで,qiitaで記事を更新することでモチベーションの維持に役立てようと思いました.
また,アウトプットを行うことで知識の整理をする目的もあります.
本編
今回参加したコンペティションはTitanicです.有名なタイタニック号の事故で死亡した方(Survived=0),生存した方(Survived=1)の傾向を掴んで予想してみようという内容です.
とりあえずデータを読み込んで,中身を確認していきます.
import numpy as np
import pandas as pd
train = pd.read_csv('/kaggle/input/titanic/train.csv')
test = pd.read_csv('/kaggle/input/titanic/test.csv')
データ内容の確認
print(train.shape)
# (891, 12)
train.head()
print(test.shape)
# (418, 11)
test.head()
欠損値の確認
trainingデータ
train.isnull().sum()
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
testデータ
test.isnull().sum()
PassengerId 0
Pclass 0
Name 0
Sex 0
Age 86
SibSp 0
Parch 0
Ticket 0
Fare 1
Cabin 327
Embarked 0
各項目の確認
pandas_profilingのProfileReportを実行するとHTMLの綺麗な形式で各データの詳細な情報を出力してくれます.詳しくは一番後ろのリンクをご覧ください.
import pandas_profiling as pdp
pdp.ProfileReport(train)
各項目とSurvivedとの関係
各項目がSurvivedとどのように関係しているのかを確認していきます.
-> 学習に使用する項目の選定の参考にします.
カテゴリカルな項目
関数を定義します.
def relation(df, colum_name):
print(pd.crosstab(df[colum_name], df['Survived']))
print('各クラス毎の生存確率')
print(pd.crosstab(df[colum_name], df['Survived'], normalize='index'))
print('生存確率に対する各クラスの割合')
print(pd.crosstab(df[colum_name], df['Survived'], normalize='columns'))
sns.countplot(df[colum_name], hue=df['Survived'])
plt.show()
プロットしたものはここでは省かせてもらいます.(一番上の表をグラフにしてます)
各項目とSurvivedとの関係を見ていきましょう.
relation(train, 'Pclass')
Survived 0 1
Pclass
1 80 136
2 97 87
3 372 119
各クラス毎の生存確率
Survived 0 1
Pclass
1 0.370370 0.629630
2 0.527174 0.472826
3 0.757637 0.242363
生存確率に対する各クラスの割合
Survived 0 1
Pclass
1 0.145719 0.397661
2 0.176685 0.254386
3 0.677596 0.347953
relation(train, 'Sex')
Survived 0 1
Sex
female 81 233
male 468 109
各クラス毎の生存確率
Survived 0 1
Sex
female 0.257962 0.742038
male 0.811092 0.188908
生存確率に対する各クラスの割合
Survived 0 1
Sex
female 0.147541 0.681287
male 0.852459 0.318713
女性の方が圧倒的に生き残っているんですね...
relation(train, 'Embarked')
Survived 0 1
Embarked
C 75 93
Q 47 30
S 427 217
各クラス毎の生存確率
Survived 0 1
Embarked
C 0.446429 0.553571
Q 0.610390 0.389610
S 0.663043 0.336957
生存確率に対する各クラスの割合
Survived 0 1
Embarked
C 0.136612 0.273529
Q 0.085610 0.088235
S 0.777778 0.638235
これも偏りありそうかな
連続値な項目
こちらも最初に関数を定義します.
def plot_data(df, colum_name, bins=20):
sns.distplot(df[colum_name], kde=True, rug=False, bins=bins)
plt.show()
sns.distplot(df[df['Survived']==1][colum_name], kde=True, rug=False, bins=bins, label=1)
sns.distplot(df[df['Survived']==0][colum_name], kde=True, rug=False, bins=bins, label=0)
plt.legend()
plt.show()
連続値なので表ではなくグラフで表していきます.
plot_data(train, 'Age')
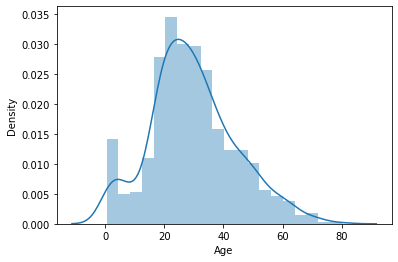
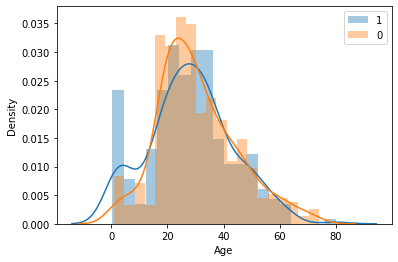
plot_data(train, 'Fare')
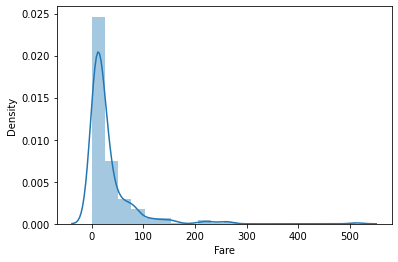
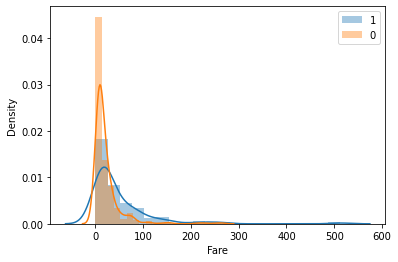
学習データの前処理
データの特性を把握したので,前処理を行なって学習しやすいようにしていきます.
欠損値の補填
Ageの欠損値は中央値で補填します.
def missing_age(df):
df['Age_na'] = df['Age'].isnull().astype(np.int64)
df['Age'].fillna(df['Age'].median(), inplace=True)
missing_age(train)
missing_age(test)
Embarkedは多数派のSで補填します.
train['Embarked'].fillna('S', inplace=True)
Fareも中央値で補填します.
test['Fare'].fillna(test['Fare'].median(), inplace=True)
数値データの前処理
AgeとFareは標準化を行います.
def normalization(df, name):
df[name] = (df[name] - df[name].mean()) / df[name].std()
normalization(train, 'Age')
normalization(train, 'Fare')
normalization(test, 'Age')
normalization(test, 'Fare')
カテゴリカルなデータのダミー化
カテゴリカルなデータはダミー化することで数値に変換します.
def dummy(df):
df = pd.get_dummies(df, columns=[
'Pclass',
'Sex',
# 'SibSp',
# 'Parch',
'Embarked'
])
return df
train = dummy(train)
test = dummy(test)
学習
実際に分類を行なっていきます.今回はXGBoostを使用します.
まずは説明変数の選択
select_columns = [
'PassengerId',
'Survived',
# 'Name',
'Age',
# 'Ticket',
'Fare',
# 'Cabin',
'Age_na',
'Pclass_1',
'Pclass_2',
# 'Pclass_3',
# 'Sex_female',
'Sex_male',
'SibSp',
'Parch',
'Embarked_C',
'Embarked_Q',
# 'Embarked_S'
]
最後の処理を行なって,
train = train[select_columns]
x_train = train.drop(['Survived'], axis=1)
y_train = train['Survived']
実際に学習していきます.
from xgboost import XGBClassifier
from sklearn.model_selection import cross_val_score
model = XGBClassifier(max_depth=7, n_estimators=5, learning_rate=0.1)
model.fit(x_train, y_train)
学習したモデルからtestデータを予測します.
y_pred = model.predict(test)
提出用のcsvファイルを作成して終了.
output = pd.DataFrame({'PassengerId': test['PassengerId'], 'Survived':y_pred})
output.to_csv('result.csv', header=True, index=False
精度は0.78229でした.
最後に
今まで,参考書を見ながらコードを書いていましたが,今回自力でコードを書いて提出することができました.(いくつか参考にしたけど)
次は精度を上げる調整をしてみたいと思います.また,別の手法でも試してみたいです.
ランキング上位を見ると精度が1ですごいなと思いました.ランキングで出ると楽しいですね.ハマりそうです.
今回のkaggleのコードです-> titanic2