この記事はUMITRON Advent Calendar 2021 17日目の記事です
#目次
まえがき
今回読む論文
Anomaly Detection for In Situ Marine Plankton Images
Improving Rare-Class Recognition of Marine Plankton With Hard Negative Mining
Super-Resolution for In Situ Plankton Images
The Marine Debris Dataset for Forward-Looking Sonar Semantic Segmentation
おわりに
まえがき
はじめまして、UMITRONの細野です。
2021年6月に入社し、ソフトウェアエンジニアとして働いています。
前職ではコンピュータビジョンの研究をしており、ウミトロンでもコンピュータビジョン関係の技術を中心に担当しています。
ふと入社してからの半年間を振り返ると、常にコンピュータビジョンを適用すべき課題が山盛りで、落ち着いて最新の技術をサーベイする時間を取れなかったなと思いました。しかし、こうして毎日何かしらの課題に取り組めているのはこれまで培ってきた専門知識があるからであり、今後もそれを続けていくために勉強は欠かせません。そこで、このアドベントカレンダーを機会に論文を読んでみよう!となりました。
今回読む論文
安直に、いつかウミトロンの業務で活かせそうなので海関係のコンピュータビジョン論文を読もうと思いました。
探してみるといくつかのワークショップが見つかりました(教えてもらいました)。
- Underwater Vision Workshop (ICCV2013ワークショップ)
- Workshop on Computer Vision for Analysis of Underwater Imagery (ICPR2014,2016,2018,2021ワークショップ)
- Computer Vision in the Ocean (ICCV2021ワークショップ)
今回はこれらの中から一番直近に開催されたComputer Vision in the Oceanの中から4本の論文を紹介しようと思います。
全体的にコンピュータビジョンの知識が必要な内容になってしまっていますが、どんな目的で研究をしているかについても触れているので、コンピュータビジョンの専門家以外の方にとっても何かの参考になれば幸いです。
それでは以降、個々の論文について解説してきます。
Anomaly Detection for In Situ Marine Plankton Images
概要
- 目的:プランクトン画像の分類
- 入力画像:海からプランクトンを採集し撮影する装置で撮影された画像
- なぜプランクトンの分類?(参考:[1],[2])
- プランクトンは海の状況のモニタリングに役立つ
- プランクトンの大量発生やそれらを餌とする魚の生態系をモニタリングする
- 技術的に難しいところ
- 気泡や海中浮遊物が大量に撮影される(撮影画像の97%を占める)
- それらプランクトン以外の物体の種類は多岐に渡るため、事前にそれらを既知の物体として認識するのは困難
- プランクトン以外の物体を正確に棄却しつつ、プランクトンについてはその種類を正確に認識する必要がある
- 提案手法:異常検知の手法を用いることでプランクトン以外の画像を棄却とプランクトンの認識を両立させる
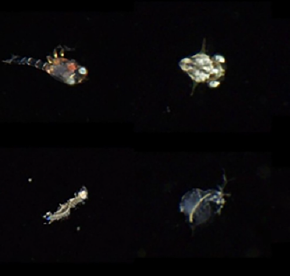
プランクトンの画像例(論文より引用)
手法と実験
- 最近異常検知でよく用いられているOutlier Exposureをベースにしている
- 手法の大枠(下図参照)
- 学習時の入力はプランクトンの画像(normal input)とその他の画像(auxiliary input)
- Pre-trainingのCNNは以下のように学習される
- プランクトンの画像:プランクトンの種類を正しく推定できるように学習
- その他の画像:各プランクトンらしさが一様になるよう学習
- Post-trainingはpre-trainingのCNNの出力を入力とし、それがプランクトンの画像かその他の画像かを識別する
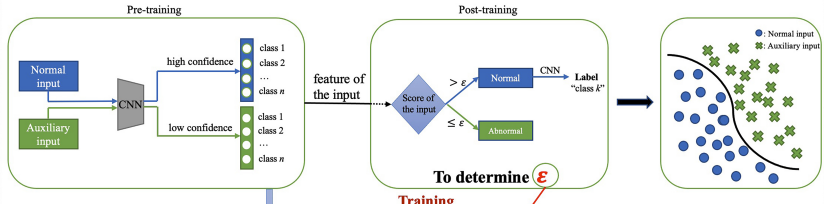
学習の流れ(論文より引用)
この論文ではpre-training学習時の損失関数について新たな関数を提案しています。なので、その部分をもう少し詳しく解説します。一般的なOutlier Exposureでは、normal input $\bf{X_1}$とその正解ラベル$\bf{Y_1}$、auxiliary input $\bf{X_2}$とその正解ラベル$\bf{Y_2}$を用いて以下のような損失関数でCNNが学習されます。
L(\bf{\theta}) =l_1(\bf{\theta};\bf{X_1},\bf{Y_1})+l_2(\bf{\theta};\bf{X_2},\bf{Y_2})
l_1(\bf{\theta};\bf{X_1},\bf{Y_1}) = -\frac{1}{N_1}\sum^{N_1}_{i=1}\sum^{K}_{k=1}y_{ik}\log P_{ik}(\bf{\theta})
l_2(\bf{\theta};\bf{X_2},\bf{Y_2}) = -\frac{1}{N_2}\biggl[\sum^{N_1+N_2}_{i=N_1+1}\sum^{K}_{k=1}\frac{1}{K}\log\frac{K^{-1}}{P_{ik}(\bf{\theta})}\biggl]
ここで、$\theta$はCNNのパラメータです。$l_1$と$l_2$はそれぞれクロスエントロピーと一様分布とのKLダイバージェンスであることがわかればよいので細かい変数の説明は省略します。これら2つの関数により、normal inputの場合は正解クラスの尤度が高くなり、auxiliary inputの場合は全クラスの尤度が一様になるよう学習しています。
この論文では、$l_1$と$l_2$が互いの学習を阻害していることを指摘しています。そして、normal inputとauxiliary inputの区別をより容易にするために、normal inputをクラスタリングする損失関数$l_3$を追加しています。
l_3(\bf{\theta};\bf{X_1},\bf{Y_1}) = \sum^{K}_{k=1}\sum^{n_k}_{i=1}(z_{ik}-\mu)^2
提案手法ではこれらの関数を用いて、最終的な損失関数を以下のように定義しています
L(\bf{\theta}) =l_1(\bf{\theta};\bf{X_1},\bf{Y_1})+l_2(\bf{\theta};\bf{X_2},\bf{Y_2})+l_3(\bf{\theta};\bf{X_1},\bf{Y_1})
実験ではDYB-PlanktonNet datasetを用いて他の手法との精度比較をしています。学習方法が他の手法と比べてシンプルながらもstate-of-the-artと同程度以上の精度となっています。
このアイデアは汎用的なものだと思うので、プランクトン画像の分類以外にも適用できそうです。
Improving Rare-Class Recognition of Marine Plankton With Hard Negative Mining
概要
- 目的:プランクトン画像の分類
- 入力画像:海からプランクトンを採集し撮影する装置で撮影された画像
- 技術的に難しいところ
- 認識対象でないプランクトンは「その他」クラスとしてラベル付けされるが、一般に「その他」クラスに属するデータ数が認識対象のプランクトンのデータ数に比べて多くなり、認識精度を低下させる原因になる
- 上記を解決するため、「その他」クラスの学習データをランダムにサンプリングし、認識対象のデータ数と揃える手法があるが、この手法は「その他」クラスの特徴空間中での分布が一様であるという現実的でない仮定を暗に置いている
- さらに、一般に認識対象のプランクトンは運用中に追加されていくが、サンプリングされるべき「その他」クラスのデータはそれに応じて変化させるべきである
- 以上のことから、適応的に「その他」クラスをサンプリングする必要がある
- 提案手法
- 「その他」クラスの中から、認識対象と区別しづらいものを重点的にサンプリング
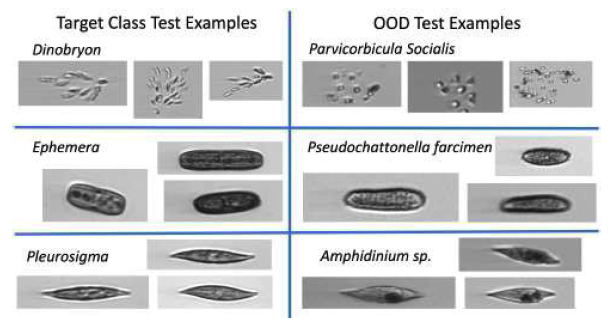
入力画像例(論文より引用)
左半分が認識対象のプランクトンデータ例、右半分が「その他」クラスのデータ例です
手法と実験
- ベースとなる手法は前の論文で登場したOutlier Exposureを改良したBackground Resampling(BR)
- 学習は以下3ステップで行なわれる(下図参照)
- 認識対象のプランクトン画像とすべての「その他」クラスの画像で学習
- 「その他」クラスの画像から認識対象のプランクトン画像と区別しづらいものをサンプリング
- 認識対象のプランクトン画像とサンプリングされた「その他」クラスの画像で学習(1回目の学習結果の重みは使わない)
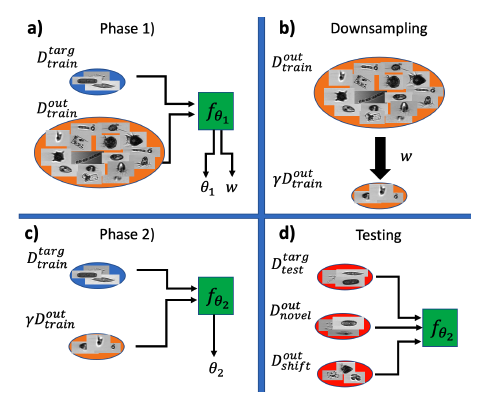
学習とテストの流れ(論文より引用)
$D_{train}^{targ}$は認識対象のプランクトン画像、$D_{train}^{out}$は「その他」クラスの画像、$\gamma D_{train}^{out}$はサンプリングされた「その他」クラスの画像、$f_{\theta_n}$はCNNです。
$f_{\theta_1}$を学習する際、CNNの重み$\theta_1$のほかに$w$が出力されています。$w$は「その他」クラスの画像の認識難度を表すパラメータで、BRで算出されます。具体的には、下記2つの式を交互に最適化することで、認識難度が高い「その他」クラスの画像をより重点的に学習するようにしています。
\newcommand{\argmax}{\mathop{\rm arg~max}\limits}
\newcommand{\argmin}{\mathop{\rm arg~min}\limits}
\theta_1^{(t)}= \argmin_{\theta_1} \big[L_{targ}(\theta_1)+\alpha L_{out}(\theta_1;w^{(t-1)}) \big]
w^{(t)}= \argmax_{\theta_1} \big[L_{targ}(\theta_1)+\alpha L_{out}(\theta_1;w^{(t)}) \big]
ここで、$\theta_1^{(t)}$と$w^{(t)}$は$t$回目のイテレーションの$\theta$と$w$です。また、$L_{targ}$と$L_{out}$はOutlier Exposureで登場した$l_1$と$l_2$同様、認識対象画像に対するクロスエントロピーと、「その他」クラスに対する一様分布とのKLダイバージェンスです。しかし、BRでは$w$が追加されています。
「その他」クラスの画像のサンプリングは学習された$w$に基づいて行われ、識別難度高い(即ち$w$が大きい)ものがサンプリングされやすいようになっています。

認識対象とサンプリングされた画像(Hard Negatives)の比較(論文より引用)
「その他」クラスの画像の中から認識対象に酷似した画像がサンプリングされていることが分かります。
- 実験
- データセット:WHOI Plankton
- 比較手法
- Random:提案手法と同じ数の「その他」クラスの画像をランダムにサンプリング
- Manual:認識対象の画像と同程度の枚数になるように「その他」クラスの画像をサンプリング
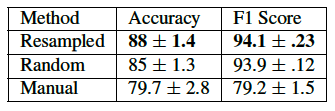
実験結果(論文より引用)
BRを用いた手法が比較手法に比べAccuracy(適合率)、F値ともに高くなっています。
Super-Resolution for In Situ Plankton Images
概要
- プランクトン画像の超解像(高解像度化)
- 入力画像:海からプランクトンを採集し撮影する装置で撮影された画像
- なぜ超解像?
- 海中のプランクトン密度はばらつきがあるので、プランクトンを撮影するためには広い範囲を撮影する必要がある
- 広い範囲を撮影すると個々のプランクトンの解像度が下がり、プランクトン認識等の処理精度に悪影響を与える
- 解像度を上げる超解像により、上記問題を解決する
- 技術的に難しいところ
- 超解像を学習するためには、高解像度画像がどのように劣化して低解像度画像になっているか(そしてそれをどう復元するか)を学習することが重要
- 一般的な手法では、学習時に高解像度画像をダウンサンプリングした低解像度画像を用いているが、この方法では上記劣化方法を正確に再現できない
- 水中画像の場合、劣化方法が地上に比べより複雑になるため、ダウンサンプリングでのシミュレーションには限界がある
- また、プランクトンは水中を動くため、全く同じ条件で高解像度カメラと低解像度カメラで撮影することが難しい
- 提案手法
- 低解像度カメラと高解像度カメラで同じ範囲を同時に撮影可能な装置を作成
- 上記装置で撮影した高解像度画像と低解像度画像のペアを使って超解像CNNを学習
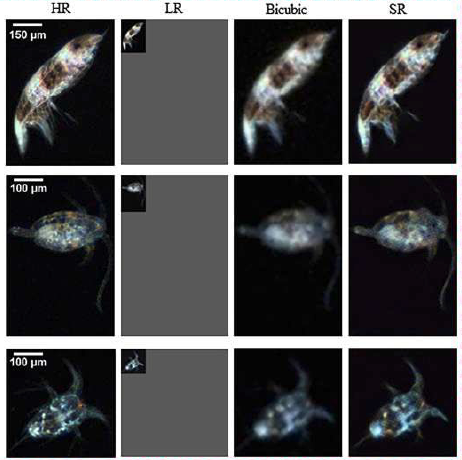
超解像結果例(論文より引用)
左の列から、高解像度画像(HR)、低解像度画像(LR)、バイキュービック法(単純な方法)で拡大した画像(Bicubic)、超解像結果(SR)
手法と実験
- 撮影装置
- 低解像度カメラと高解像度カメラで同時に撮影した画像を位置合わせすることで、高解像度画像と低解像度画像のペアを取得
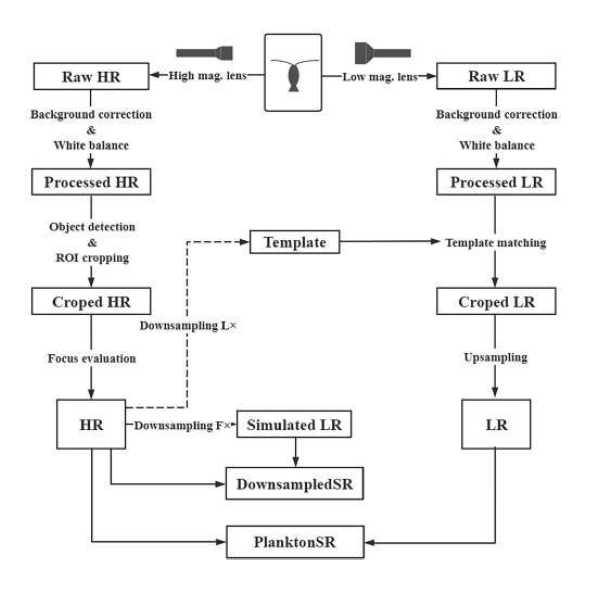
撮影処理フロー(論文より引用)
- 超解像手法
- EDSRという手法を利用
- 損失関数は以下の3つを比較
- L2 Loss:正解高解像度画像と超解像画像の画素値の誤差を最小化
- Perceptual loss:正解高解像度画像と超解像画像からCNN特徴を抽出し、その特徴の誤差を最小化
- Context Loss(CX Loss):正解高解像度画像と超解像画像からCNN特徴を抽出し、その特徴のコサイン類似度を最大化
- 実験結果
- 評価指標はPSNR, SSIM, NIQE
- PSNR(Peak Signal to Noise Ratio):画素値の誤差に基づき計算される指標(高い程よい)
- SSIM(Structural Similarity Metric):画像の構造的な類似度に基づき計算される指標(高い程よい)
- NIQE(Natural Image Quality Evaluator):画像の高品質さを計測する指標(低いほどよい)
- 損失関数はContext lossが全体的に高精度
- ダウンサンプリングにより高解像度画像と低解像度画像のペアを作成し学習した場合に比べ精度が大きく向上
- 評価指標はPSNR, SSIM, NIQE
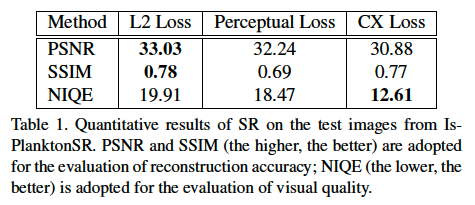
各損失関数と精度の関係(論文より引用)
CX Lossが全体的に高精度です。PSNRが比較的悪い結果になっていますが、これはCX Lossが厳密に格画素の誤差を最小化しないためなので、妥当な結果と言えます。
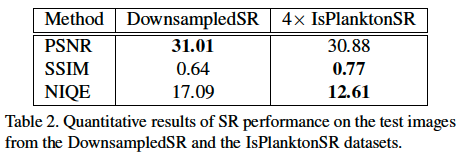
ダウンサンプリングで学習データを作成した場合との精度比較(論文より引用)
PSNRでは若干精度が劣るものの、その他の指標で大きく精度が向上しています。

バイキュービック法で拡大された画像と提案手法(CX Loss)で超解像された画像の比較(論文より引用)
どの画像についても細かいところまで高精細に高解像度化できていることが分かります。
The Marine Debris Dataset for Forward-Looking Sonar Semantic Segmentation
##概要
- Forward Looking Sonar(FLS)で海中のゴミを撮影したデータセットの作成
- なぜFLS?:照明環境が劣悪な事が多い海中では、一般的なRGB画像よりもソナーの方が物体認識が容易が事が多い
- なぜ海中のゴミ?:海中ロボットが自動でゴミを避けたり、回収したりするために、これらを自動で認識する必要がある
- このようなデータセットが存在しなかったので、1868枚のFLS画像から成るデータセットを作成した
- ベースラインの手法によるセグメンテーション精度の評価も実施している

FLSをつけた水中ロボット(論文より引用)
このロボットを使ってデータセットを撮影したそうです

ゴミが水中に配置されている様子(論文より引用)
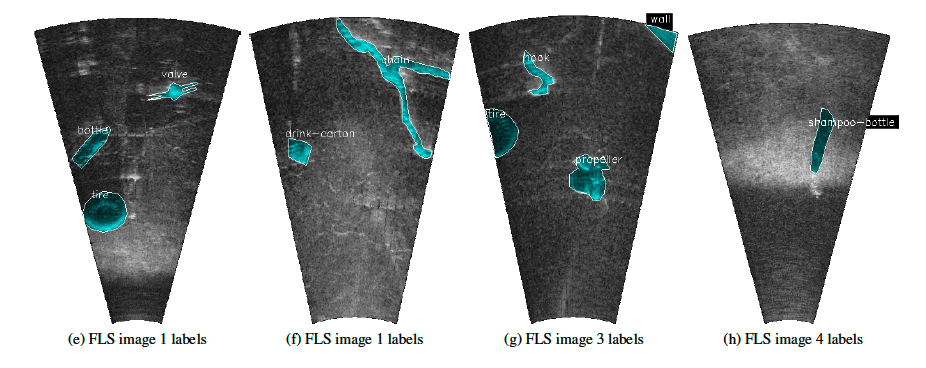
データセット画像例(論文より引用)
撮影されたソナー画像に対して、ゴミの領域が画素単位でアノテーションされています
ベースライン手法と実験
- 様々なセマンティックセグメンテーション手法、バックボーンネットワークを適用し精度を調査
- セマンティックセグメンテーション手法
- UNet, LinkNet, PSPNet, DeepLabV3
- バックボーンネットワーク
- ResNet, VGG, EfficentNet, InceptionNetV3, InceptionResNetV2
- 結果は下図(評価指標はIoU)
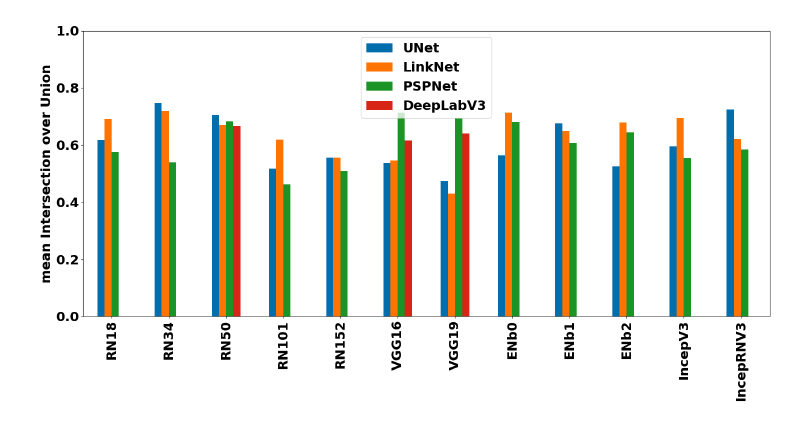
各セマンティックセグメンテーション手法、バックボーンネットワークにおける精度(論文より引用)
この結果を見ると、どのセマンティックセグメンテーション手法が一番良いかはバックボーンネットワークにより異なるので、自分が取り組むタスクにどんな手法を適用するが一番いいのかを決めるためには、たくさん実験をする必要があるなと感じました…
おわりに
意図的に選んだわけではないのですが、プランクトン画像に関する論文多くなってしまいました。しかし、技術的な難しさは画像やデータセットが認識にとって理想的な状況ではないことに起因したものでした。これらは実データを扱う上では避けられないものなので、いつか役に立つ知識が得られたのではと感じました。
また、ベースとしている手法はありつつも、損失関数やアーキテクチャを変えて網羅的に実験してることが多いのもこのワークショップの論文の特徴なのではないかと感じました。これは、データセットそのものが新しかったり、既存のデータセットを用いる場合もノウハウが蓄積されていないためではないかと思いました。我々も公開データセットとは撮影対象や条件が大きく異る画像に対してアルゴリズムを適用することがほとんどです。各手法の精度の優劣が公開データセットとは異なることもあるため、試してなければわからない部分がある程度あります。そのような中で迅速に適切な方法にたどり着けるよう、アルゴリズムやその実装に関するノウハウ蓄えていかなければなと改めて感じました。
本記事で触れた論文は4本でしたが、残りの論文のうちいくつかについても高橋(@q_tarou)が12月24日に本アドベントカレンダーで紹介予定ですので、そちらも併せてチェックいただけると嬉しいです。
ウミトロンでは一緒に働く仲間を募集しております。持続可能な水産養殖を地球に実装するというミッションの元で、私たちと一緒に水産養殖xテクノロジーに取り組みませんか?