あらまし
今回はElmのURLハンドリングや、SPAの#付きURLの仕掛けを手っ取り早くわかりたい人に読んで頂けたらなーと思って書いております。
逆に、もう知ってるよという方には全く役に立たないと思います。
ちなみに#付きURLの仕掛けについては自分が見つけられてないだけかもしれませんが、SPAルータの文脈ではいい感じの解説を見たことがなくて、
身の回りのフロントエンドエンジニアと話したり、コミュニティーのお話を見ていると結構この話をしていて、Webフロントエンドあるあるとして、ちょこちょこ需要があるのかなーと思っております。
そもそも#の付いてるURLって
自分もURLルールについてすごく詳しいわけではないので言葉の使い方とかちょっと不安ですが。。
そもそも、なんでSPAルータは、良くURLに#を付る形になってるんでしょうか。
よく、HTML要素のid属性のところまでリンクするのに#を使ったりすると思いますが。
URLにおける#から後ろの部分に関しては**「ハッシュ」**と呼ばれるそうです。
で、ハッシュはURLの一部では無く、HTTPリクエストでサーバリソースを取得する際には、ハッシュを除去した形で送りつけるとのことで、
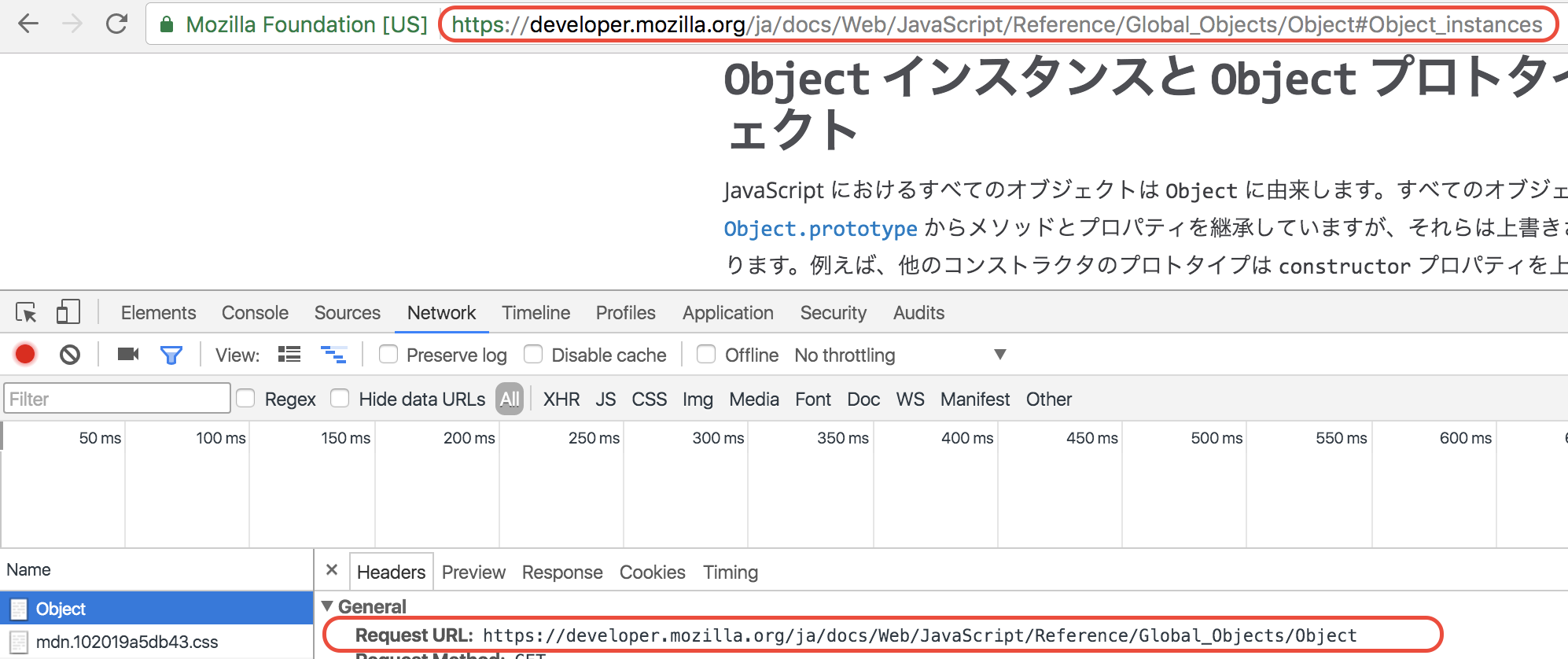
実際にブラウザの検証ツール等でRequest URLとかを見ると、見た目上は存在しないように見えます。
で実際にサーバーサイドでログ取ってURLをみるとハッシュ部分は入っていませんでした。
↓Requestにハッシュなしの図
SPAルータのハッシュについて
上述したハッシュルールをハッシュ付きのSPAのURLに当てはめてみると
例えばhttp://hoge.com/#/any/123というURLはhttp://hoge.com/の部分ががリソースのアドレスで、#/any/123の部分はハッシュであるという事になりますね。
なので、サーバとの対話上はhttp://hoge.com/index.htmlを取得して#/any/123はクライアント側で利用したりしなかったりする「なにか」となる、ということですね。
SPAルータはこの「なにか」をコンテンツの出力パターンとして、開発者が対応するコンテンツを定義できる機能を提供しているという感じで自分は捉えてます。
History API
また、SPAルータはこのHTML5のHistoryAPIを使ってURL遷移を実現するなどとよく言われます。全てがそうではないかもですが。。
例えばSPAルータの提供するリンクがクリックされると、
SPAルータはサーバにリクエストを送ること無く新しいURLを履歴に積み、
戻るボタンとかが押されたときはHistoryAPIがハンドリングして履歴を操作したりします。
#なしのURLを実現するには
で、#なしのURLを実現するということはhttp://hoge.com/#/any/123をhttp://hoge.com/any/123にするということですね。
そうするとhttp://hoge.com/any/123のアドレスが何かしらのリソースを持つ必要があるということになりますね。
これは、SPAルータがHistoryAPIを使い実際のHTTPリクエストを飛ばさない時は動作しますが、
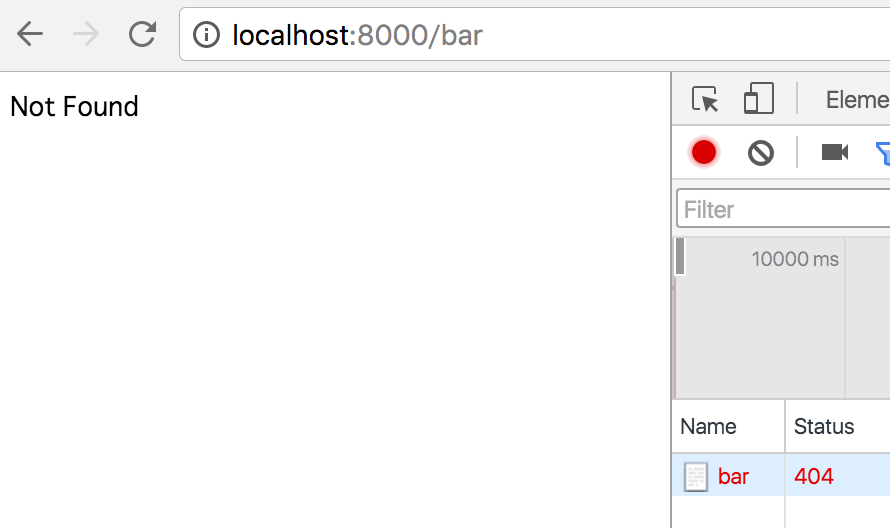
例えばページがリロードされたときには、先にサーバーにハッシュ無しURLがリクエストされることになり、ページリソースを用意していないと、レスポンスがNot Foundとなってしまいます。
↓ハッシュなし&サーバリソースなしで、ページリロードしたの図
Elmのルーティング
ライブラリ
今回はnavigationとurl-parserを使ってルーティングをやっていきます。
例えば、navigationはelm-langというコミュニティで作っているのと、
url-parserはElmの作者のEvanさんが作っているので、言語のバージョンアップ時にも同時に対応していたり、
この辺のオフィシャリーなガッツリサポート具合は嬉しいところです♪
elm-stuff/の下のNative/Navigation.jsあたりを見ると下記のようなコードが有り、HistoryAPIの使用していることがわかります
function pushState(url)
{
return _elm_lang$core$Native_Scheduler.nativeBinding(function(callback)
{
history.pushState({}, '', url);
callback(_elm_lang$core$Native_Scheduler.succeed(getLocation()));
});
}
サンプル
下記のような感じのモノを組んでいます。
ソースはこちらにおいてあります。
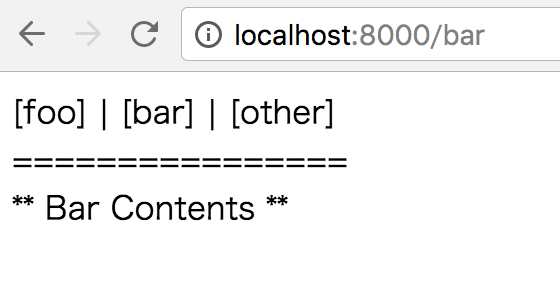
URLには#がありません。
上の段のfoo bar otherがURLとコンテンツを書き換えるようになっています。
ElmのモジュールがHitoryAPIを操作してくれるので戻る/進むボタンにも対応出来ます。
↓コレが画面です(メチャ地味ですが。。)
サンプルのElmコード
ソースは下記のものです。
parseLocationという関数でURL解析を行っているんですが、この中にparsePathという関数があります。
これがurl-parserモジュールの関数で、仲間にparseHashという関数がいます。
parsePathを使うとハッシュなしURLの解析、parseHashを使うとハッシュありURLの解析をおこなうという感じです。
ちなみに結構navigationやurl-parserは結構自由に使うことが出来て、
結構お作法ガチガチなSPAルータは覚えさせられてる感が強いので、この辺の自由度も地味に嬉しいところです。
module Main exposing (..)
import Navigation exposing (..)
import UrlParser exposing (Parser, parseHash, parsePath, map, top, s)
import Html exposing (Html, div, span, a, text)
import Html.Events exposing (onClick)
type Msg
= ChangeLocation Location
| ClickLink Route
type Route
= Foo
| Bar
| NotFound
type alias Model =
Route
init : Location -> ( Model, Cmd Msg )
init loc =
parseLocation loc ! []
update : Msg -> Model -> ( Model, Cmd Msg )
update msg model =
case msg of
ChangeLocation loc ->
parseLocation loc ! []
ClickLink route ->
route ! [ Navigation.newUrl <| routeToPathStr route ]
view : Model -> Html Msg
view model =
let
content =
case model of
Foo ->
text "** Foo Contents **"
Bar ->
text "** Bar Contents **"
NotFound ->
text "** Contents Not Found **"
in
div []
[ span [ onClick <| ClickLink Foo ] [ text "[foo]" ]
, span [] [ text " | " ]
, span [ onClick <| ClickLink Bar ] [ text "[bar]" ]
, span [] [ text " | " ]
, span [ onClick <| ClickLink NotFound ] [ text "[other]" ]
, div [] [ text "================" ]
, div [] [ content ]
]
matchers : Parser (Route -> a) a
matchers =
UrlParser.oneOf
[ map Foo top
, map Foo <| s (routeToPathStr Foo)
, map Bar <| s (routeToPathStr Bar)
]
routeToPathStr : Route -> String
routeToPathStr route =
case route of
Foo ->
"foo"
Bar ->
"bar"
NotFound ->
"other"
parseLocation : Location -> Route
parseLocation location =
case (parsePath matchers location) of
Just route ->
route
Nothing ->
NotFound
main : Program Never Model Msg
main =
Navigation.program ChangeLocation
{ init = init, subscriptions = always Sub.none, view = view, update = update }
サーバサイド
サーバサイドはページリロード時にNot Foundとならないように各URLに対してページコンテンツを返す必要があります。
更に言うと404もSPAのコンテンツで表現するのであれば、あらゆるURLに対して応答を返す必要があります。
なので、一つ一つのURLに応答を設計していくというよりはURLのリライトルールを定めて対応するのが良いかと思います。
FirebaseホスティングやAWSのS3ホスティングなんかでもいい感じのリライトルールを作れますが、チームで開発する際にはローカルで完結出来る方がいいですね。
Nodeとかで簡易サーバ書いても良いんですが、今回は頑張らない方向でライブラリを使ってみます。
local-web-serverというモジュールがちょうど今回の用途にちょうどよかったので使わせてもらいます。
このモジュールは--spaというオプションを持っており、下記のように記述すると、HTTPアクセス時にリソースがない場合index.htmlをよしなに返してくれます。
これでトップページ以外でリロードされても404にならないように出来ます。
$ ./node_modules/.bin/ws --spa index.html
今回は以上となりますー。