この記事は、AWS LambdaとServerless Advent Calendar 2020 の5日目の記事です。
自己紹介
バックエンドのエンジニアとしてそろそろ8年になります。
今年度の初めからサーバーレスを用いた API 開発に従事しています。
元々 C#, Java, PHPなどでサーバーアプリケーションの構築に関わっていましたが、
サーバーレスなアプリケーションの構築は初めてで、学んだことをこの場で共有していけばと思っています。
サーバーレスだからこそ実現できること
よく、サーバーインフラにまつわる設定が必要ないからサーバーレスは楽だよ、という話を聞きます。
実際、マネージドサービスのAWS Lamdbaで業務ロジックを動作させることによって、
サーバー冗長化、プロセス監視、サーバー複数台で構成されている時の様々な面倒くささ(セッション管理・デプロイなど)はなくなります。
しかし、それだとサーバーレスアプリケーションで作るべき理由をあまり感じないです。
もちろん、小規模的な開発が世の中に増えてきた背景を考えると、現実的な1つの解ではあるとは理解していますが...。
サーバーレスアプリケーションである理由はなんだろう?...とある時期から考え始め、
結果たどり着いた結論は、サーバーレスアプリケーションの最大の利点は、「リソース最適化をしやすさ」ではないかと思いました。
理想なユースケース
サーバーレスでは、一つのロジックが Lambda として作られます。 Lambda では下記機能がデフォルトで利用できます。
- CloudWatchによるパフォーマンス計測
- 同時実行数設定による処理の並列化
と言うことは、一つのロジック単位でパフォーマンス・スケーリングが実現できることになります。
つまり、顧客が少なければ少ないコストで運用でき、顧客が増えれば必要になったところをスケーリングするだけで対応できるということになります。
また、EC2サーバーのスケールアップとは異なり、ダウンタイムなく実施でき、AWSの管理コンソールから実施可能と言うのも大きな利点だと思います。
理想的なケース1
顧客 「最近特定の機能だけが重いように感じるんだけど...」
開発者 「XXXの処理が重くなっていたので、そこだけスケーリングしておきました」
顧客 「あれ、もう終わったの?」
開発者 「はい、管理画面から設定変更しただけです!」
理想的なケース2
顧客 「この機能だけちょっと処理時間長くない?」
開発者 「この処理だけ、ロジックが冗長だったので直しました!」
顧客 「OK、改善したよ。他の処理への影響は大丈夫なの?」
開発者 「はい、該当部分だけデプロイしたので、影響はありません」
現実は...
しかし、実際にやってみたら全然そうならないケースが発生します。理由としては、
- ある同じ処理が複数のLambdaに点在しており、1Lambdaのスケーリングで対応できない
- 機能依存があるLambdaだったため、依存するLamdaに対して全て対処しないと効果が薄かったり、齟齬が発生する
よくないケース1
顧客 「最近特定の機能だけが重いように感じるんだけど...」
開発者 「XXXの処理が重くなっていたので、そこだけスケーリングしておきました」
顧客 「あれ、あまり変わらないよ?」
開発者 「ボトルネックとなる処理が複数箇所にあり、そこだけ直しても改善できなかったので、関係しそうな全てをスケールアップしました」
顧客 「!?」
よくないケース2
顧客 「この機能だけちょっと処理時間長くない?」
開発者 「この処理だけ、ロジックが冗長だったので直しました!」
顧客 「え、なんか別の処理が壊れたんだけど?」
開発者 「すいません、他のLambdaの処理が壊れました」
顧客 「・・・」
理想的なシステムを目指すために
私の担当している案件では、エンドユーザの操作するスマホアプリから実行されるAPIを APIGateway で実装しました。
この他に、管理画面が存在して、エンドユーザのデータを操作する要件もありました。これは SQS を経由して実行するようにしていました。
そうした要件の結果、APIGateway, SQS で実行される Lambda の数は70以上あり、さらに、10人くらいが並列で実装している状態でした。
このため、よくないケースが発生しないようにするため、チームで大きな方針を立てることが必要になりました。
そして、考えた結果下記のようにしました。
- 業務処理はSQSに紐付くLambdaに作る (APIGateway, SQSから実行される Lambdaであっても!)
- 業務データ観点で 1Lambda にまとめる
- 業務データの階層を意識した構造にする
業務処理はSQSに紐付くLambdaに作る
あるデータを作成する処理を管理サイト側・APIから実行されるケースがあるとします。
普通に作っちゃうと下記のようになると思います。
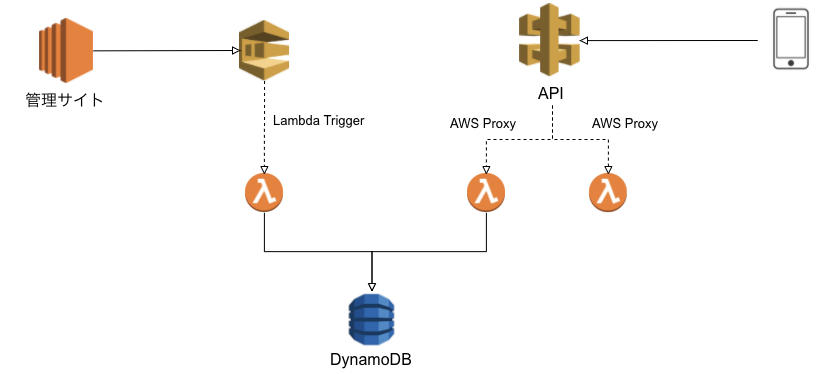
しかし、こうすると複数 Lambda(APIGateway, SQS)に処理が存在してしまいます。
仮に APIGateway 側を直した場合、管理画面から実行される Lambda も直さないと整合性が保てなくなります。
このため、APIからの処理をSQSにメッセージを送るように修正します。
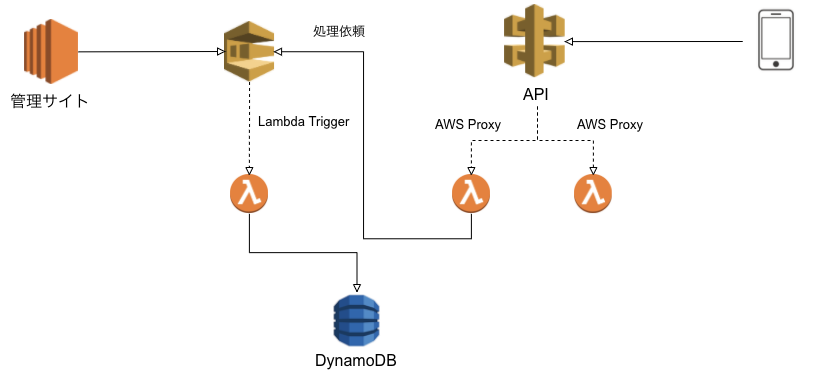
こうすることで、管理側から処理を実行しても、APIで処理を実行しても同じロジックを通るためメンテナンス性がよくなります。
業務データ観点で 1Lambda にまとめる
依頼するようにすれば、コードの重複問題は解決します。しかし、それだけでは解決しない問題があります。
ある業務データを作成する処理、更新する処理、削除する処理は、どれかが修正されたら影響を受ける可能性が高いはずです。
つまり、業務データ観点から Lambda を作るべきでしょう。
業務データの階層を意識した構造にする
また、1 Lambda で関連する処理を全て記載するのではなく、サブ的な業務データを操作する可能性があるのであれば
それも Lambda を分けるようにします。
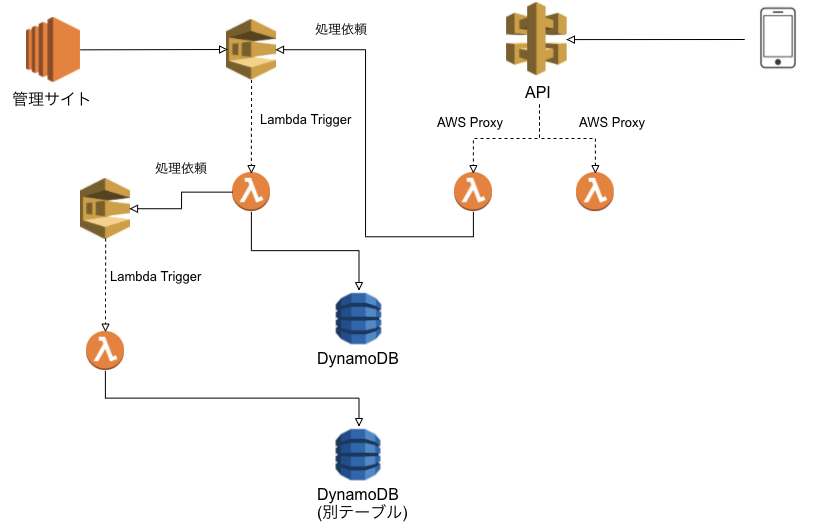
そうすれば、仮にこの後、管理画面から2つ目の機能を呼び出すことがあっても、そこに依頼するだけで済むわけです。
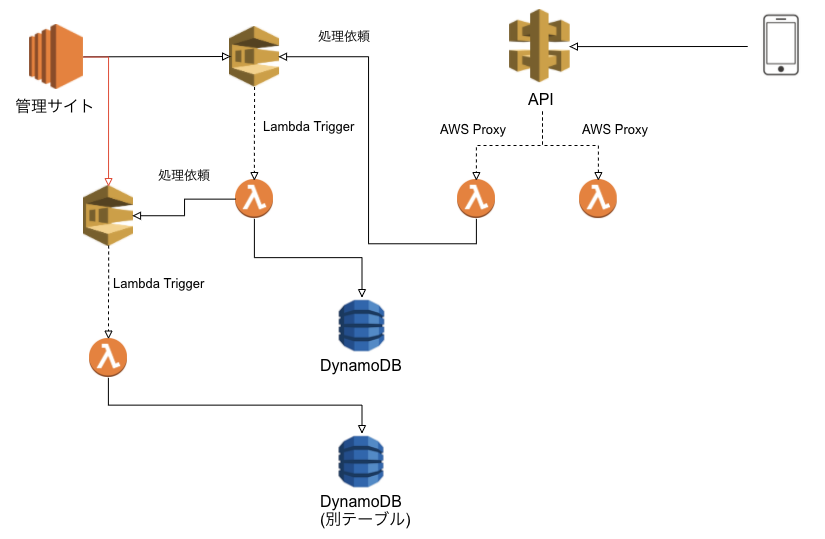
こんな風に機能をLambda でつなぐことで気をつけたいのは、処理の依存関係です。
過去の記事にも Lambda の再起呼び出しで高額請求に至ったケースがあります。
https://blog.mmmcorp.co.jp/blog/2019/12/25/lambda-cloud-bankruptcy/
これを防ぐには、業務データの依存関係を整理して、ループが作られないよう意識することが必須です。
そんなので本当にアプリケーション組めるの?
この方式にはいろんなケースを考慮すると議論すべきポイントがあります。
自分が考えた感じ大きく下記の3つが該当するかなぁと思います。
- APIでSQSのLambdaでの処理結果を返したいケースはどうするの?
- APIとSQSのLambdaの実行時間が異なる可能性があるのでは?
- SQSのLambdaでエラーが発生したら?
APIでSQSのLambdaでの処理結果を返したいケースはどうするの?
SQSのLambdaから APIに値を返すことはできません。
このため、レスポンスに必要なデータを用意するのはAPIが行い、SQS側で処理が実施された想定でレスポンスを返します。
また、SQSのLambdaの処理結果は、依頼内容が同じであれば常に同じ処理結果になるようにしておきます。(現在時刻保存したり、新規ID発番したりしない)
レスポンス返す時点では処理は実行されていないかもですが、処理されていれば意図した結果になるはずです。
ex). pythonで boto3 使ってSQSに依頼する API の例
import boto3
def create_record():
new_id = create_new_id() # ID発番処理
boto3.resource('sqs') \
.get_queue_by_name(QueueName='record_sqs') \
.send_message(Entries=[
{
'Id': str(uuid.uuid4()),
'MessageBody': '{"id":"' +new_id + '", "data1":"...."}'
}
])
return {
'statusCode': 201,
'body': '{"id":"' + new_id + '"}'
}
また、作成するレコードと同じものがすでにテーブルに存在する場合はエラーコードを返したい場合等は、
API側でテーブルに該当のレコードが存在するかどうかを調べて、存在したらSQSに依頼せずエラーコードを返すようにします。
APIとSQSのLambdaの実行時間が異なる可能性があるのでは?
仮に、SQSに処理依頼が混雑すると、当然ですが処理実行は遅れる可能性があります。
そうすると、APIとして正常ステータスを返したけど意図した処理が発生していないよ? ...ということが起こり得ます。
これに関しては、「仕方がない」というスタンスです。これが発生しないように下記をするべきかと思います。
- APIの正常なレスポンスコードのスタンスを「処理依頼を受け付けた」にする
- 実際にデータが作られているかどうかは一覧取って判断すべきということにする
- SQSに依頼した処理が時間かかるものであれば、ステータスを設けてクライアントに確認させる。
- 処理実行が毎回あまりに遅いのであれば、Lambda自体のスペックをあげる
SQSのLambdaでエラーが発生したら?
これもAPIにエラーが発生したことを伝えることは不可能です。(SQS依頼後、APIはすでにレスポンスを返して終了するから)
これに関しては、SQS側でリトライすることで、エラーが発生しても、あるべき姿になるだろう...という想定です。
SQSでは、トリガーとなるLambdaが失敗すると、その処理をリトライ実行します。
これを使って、偶発的なエラーはリトライによって回復できます。
では、偶発的ではないケースは...というと、これはどうしようもないです。
なので、何回かリトライしても失敗するケースは、SQSへの依頼内容をどこかに記録しておき、運用側が手作業で復帰させるという想定です。
※ 注意:SQSのLambdaが入力から一意な処理結果になるように作られている前提です。
まとめ
今回は、サーバーレスアプリケーションの理想的なユースケースについて整理して、そのために必要だと思う方針を提示しました。
そして、それにはトレードオフとなる課題点もあることを記載しました。
サーバーレスの経験があまりないため、この方式がどうなのか...というのは正直わかりませんが、今の所、大きな問題は出ていないように思います。
もし、似たような環境でもっとシンプルに解決する方法があるのであれば、コメント等で教えていただけたらと思います。