はじめに
2019年11月から12月5日までに発表されたAWS Lambdaに関する新機能の中で、以下の二つを取りあげて構成方法とテストした結果についてまとめたいと思います。
-
AWS Lambda Supports Destinations for Asynchronous Invocations
(非同期呼び出し時の結果出力先を指定できるようになった件) - [AWS Lambda Now Supports Maximum Event Age and Maximum Retry Attempts for Asynchronous Invocations]
(https://aws.amazon.com/about-aws/whats-new/2019/11/aws-lambda-supports-max-retry-attempts-event-age-asynchronous-invocations/)
(非同期呼び出し時でLambda関数内でエラーが発生した場合の最大再試行回数やイベント維持期間を指定できるようになった件)
なお、 Maximum Event Ageは後日追記するか別途作成します(時間切れ)。
サマリ
- 非同期呼び出しをする際の処理結果について「成功時」「失敗時」ともに現時点では4つDestinationがサポートされており、各関数ごとに、そのうちの1つに送信ができる。(成功で1つ、失敗で1つ)
- 今まで固定だった非同期呼び出しでエラにーが発生した場合のリトライ回数について0回から2回まで選択ができる。3回以上が指定できるわけではない。
- リトライ回数を超えて失敗した場合Destinationの「On failure」で指定した先にデータが送信することができる。
- Lambda関数のデッドレターキューも従来通り指定できるが、Destinationの「On failure」のほうが情報が細かい。
背景
(AWS Lambdaの従来の挙動いついてご存知の方はスキップしてください)
今回の機能がリリースされた背景について振り返ってみたいと思います。それには以下の2点について再確認する必要があります。
- Lambda関数の呼び出し方法と応答内容
- Lambda関数実行時にエラーが発生した場合の挙動
それでは、順番に確認してみましょう。
1.Lambda関数の呼び出し方法
AWS Lambda関数の呼び出し方法としては
- 同期呼び出し
-
非同期呼び出し
の二種類があります。同期呼び出しではLambda関数の処理結果を呼び出し元に応答します。AWS CLIでLambda関数を呼び出した場合、引数に指定したファイルに出力結果を格納し、コンソールには応答ヘッダーの内容が応答されます。一方、非同期呼び出しでは処理結果は格納されません。また、エラーメッセージがコンソールに出力されます
AWS CLIで呼び出した場合を例に挙げて呼び出し方式と処理結果の応答方法を以下の通り整理します。
| 呼び出し方式 | 正常 | 失敗 |
|---|---|---|
| 同 期 | 指定されたファイルに関数の処理結果を出力 | コンソールにエラー内容を出力 |
| 非同期 | なし | コンソールにエラー内容を出力 |
ここでは、「正常」「失敗」の意味を間違えないようにする必要があります。
非同期呼び出し方式における「正常」はリクエストが受け付けられたことを意味します。つまり、AWS Lambda内のキューに受付られた場合のことを「正常」といい、受付が何等か失敗した場合を失敗としており、Lambda関数が実行され実行中にエラーが発生しても、あるいは、エラーが発生せず正常終了しても、その結果はどこにも返されません。なぜなら、非同期方式は受付と実行は別のプロセスが行うため、受付側は関数がいつ動いてどのような結果になったかは分からないからです(だから”非同期”)
非同期呼び出し方式では「Lambda関数が実行された際の処理結果」を今までアプリケーション側で取り扱うことができませんでしたが、それが今回の機能リリースで取得できるようになったというわけです。これが1つ目の記事の背景となります。
では二つ目の記事の背景について続けて確認したいと思います。
2. Lambda関数実行時にエラーが発生した場合の挙動
冒頭で述べた通り、Lambda関数実行時にエラーが発生した場合、呼び出し方式によってAWS Lambdaのハンドリング内容が異なります。
|呼び出し方式 |Lambda関数実行中にエラーが発生した場合の動作 |リクエスターの対応方法 |
|--- |--- |--- |--- |
|同 期 |エラー情報がリクエスターに戻される |受け取ったエラー情報をハンドリングしリトライ等を組み込む |
|非同期|AWS Lambdaがリトライ処理を自動的に最大2回実施する|デッドレターキューを作成し、リトライの2回目(初回とあわせると3回目)が失敗した場合のデータ受け取り先を構成する|
今回の機能がリリースされるまでは、AWS Lambdaは非同期呼び出し時のリトライとして最大2回まで実施する仕様でした。リトライ処理を1回で終えたいというような制御は今までできなかったのです。
これが二つ目の記事の背景となります。
サンプル関数のご紹介
新機能を検証するために、まず、サンプル関数と、新機能を構成する前の状態の実行結果を確認していきます。
サンプルのLambda関数は新規にLambda関数を作成する際に利用可能な「設計図の使用」(いわゆるBlueprint)で提示される「hello-world-python」をベースとして作成されたLambda関数を利用します。以下の画面では「python3.7」で検索してフィルタしています。
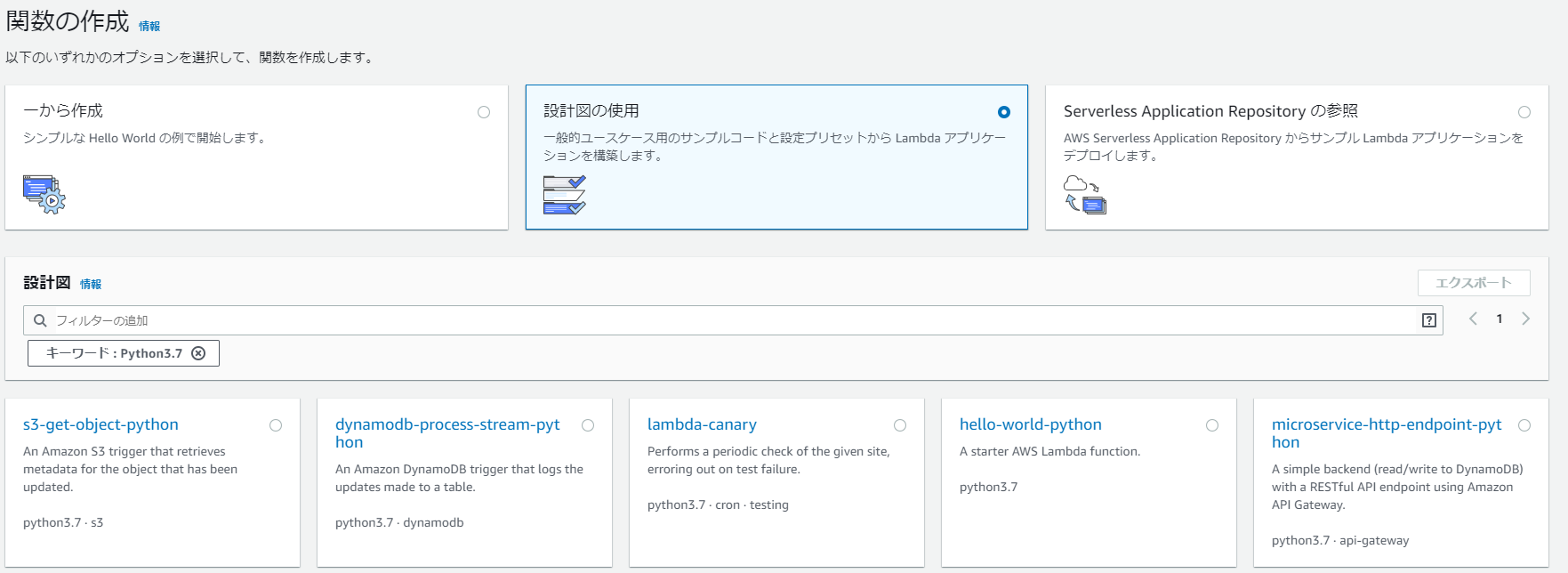
上記の設計図から作成された関数を一部修正し以下のサンプル関数で今回は挙動を確認します。
なお関数名はQiitaSampleです。
import json
print('Loading function')
def lambda_handler(event, context):
print("Received event: " +json.dumps(event))
return event['key1']
サンプル関数の処理内容はシンプルです。処理が呼び出された場合、受信内容をログに出力し、その後、受信内容のkey1の内容を応答するというものです。このサンプルでは、key1がない場合、エラーとなります。
では、AWS CLIで実行して結果を確認してみましょう。
同期呼び出し
$ aws lambda invoke --function-name QiitaSample --payload '{"key1":"test"}' result.txt
{
"ExecutedVersion": "$LATEST",
"StatusCode": 200
}
$ cat result.txt
"test"
result.txtファイル内にPayloadで指定した内容が出力されています。
では次に、Lambda関数実行中にエラーになるデータをPayloadに指定し結果を確認しましょう。
aws lambda invoke --function-name QiitaSample --payload '{"data":"test"}' result.txt
{
"FunctionError": "Unhandled",
"ExecutedVersion": "$LATEST",
"StatusCode": 200
}
$ cat result.txt
{"errorMessage": "'key1'", "errorType": "KeyError", "stackTrace": [" File \"/var/task/lambda_function.py\", line 8, in lambda_handler\n
非同期呼び出し
$ cat input.json
{"key1":"test"}
$ aws lambda invoke-async --function-name QiitaSample --invoke-args input.json
{
"Status": 202
}
非同期呼び出しでは上記のとおりinput.jsonファイルを用意して引数として指定しています。応答結果としては、HTTP 202ということでACCEPTEDが応答されてました
では次に、Lambda関数実行中にエラーになるデータをinput.json内にセットして結果を確認しましょう。
$ cat input.json
{"data":"test"}
$ aws lambda invoke-async --function-name QiitaSample --invoke-args input.json
{
"Status": 202
}
結果は変わりません。Status 202 つまり、ACCEPTEDが応答されています。これは今回指定したデータがLambda関数処理実行中に使われ、そこでエラーになるためであり、非同期呼び出しの受付は正常に終了したためです。
以上でサンプル関数のご紹介と各方法による実行結果についてご説明しました。ここまでをベースの知識として頭に入れたうえで、検証に進みます。
新機能の検証
さて、ここからが当記事のメインとなります。
AWS Lambda Supports Destinations for Asynchronous Invocationsの検証
まずは、以下の記事に対する検証をしてみたいと思います。
AWS Lambda Supports Destinations for Asynchronous Invocations
端的に言えば、非同期呼び出し時のLambda関数の処理結果の出力先を指定できるようになったということになります。今までは、実装するLambda関数内で何等か結果を通知・格納する仕組みを実装する必要がありました。
では、Lambda関数が正常に終了した場合の応答データを返す先はどのように指定するのでしょうか?
こちらには2019/12/06現在、以下のDestinationが定義されております。正常あるいは、失敗時のデータ送信先をDestinationとして設定するだけです。ちなみにDestinationに指定した各サービスのリソース(例:SQSであればQueue)にデータを送信するために、対象サービスのActionに対する許可がLambda関数の実行ロールに対して必要ですのでご注意ください。
1.Amazon SQS – sqs:SendMessage
2.Amazon SNS – sns:Publish
3.Lambda – lambda:InvokeFunction
4.EventBridge – events:PutEvents
ここでは、Amazon SQSのキューに結果を格納することにします。
1.まず以下の画面の右下の「Add Destination」をクリックします。
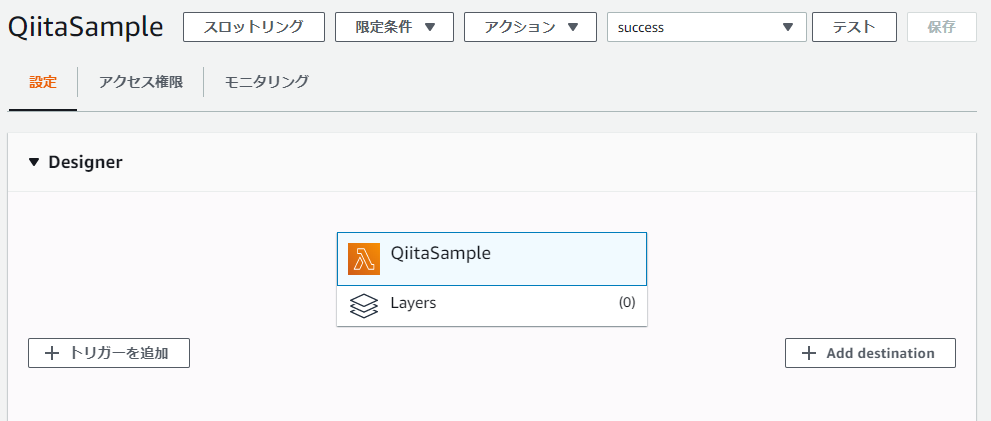
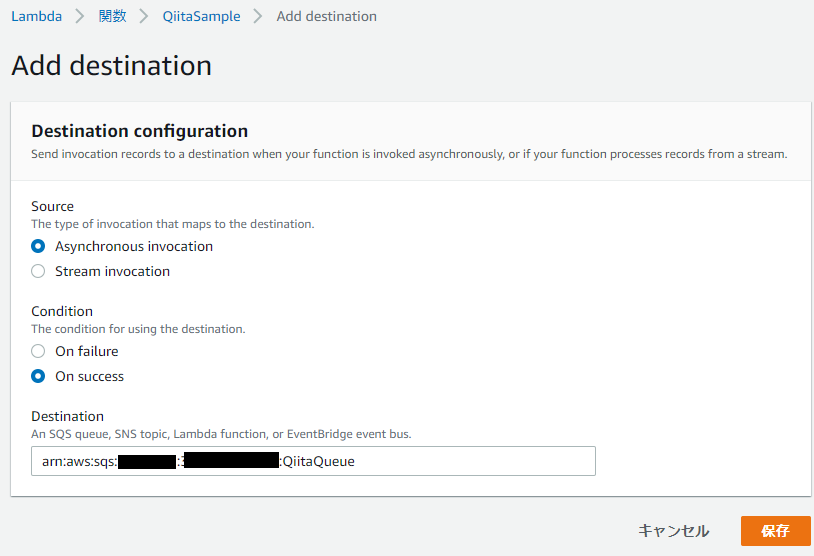
今回は、非同期呼び出し&処理成功時に結果を送る先としてAmazon SQSを選択するためQueueのARNを取得し設定します。
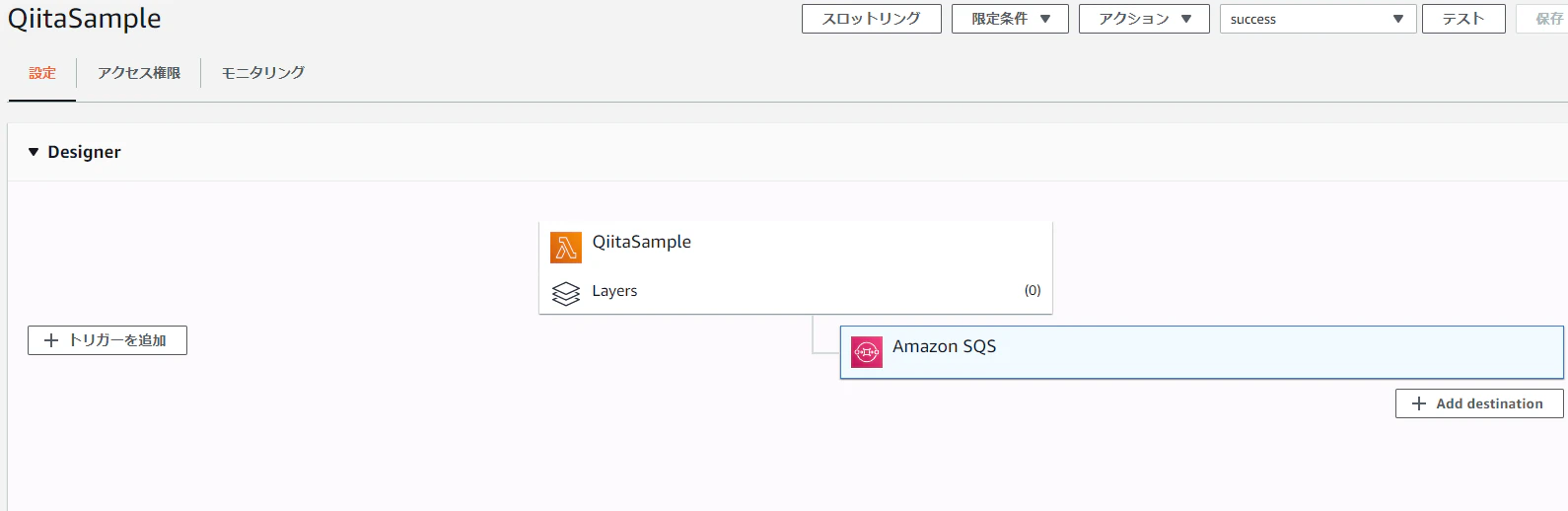
設定が完了すると以下の図のようにAmazon SQSが追加されます。今回はQiitaQueueというQueueにOn success時にデータを送るように設定しました。
それでは、実行結果を確認してみましょう。実行するコマンドは先ほどご紹介したコマンド、データで試します。試した結果、以下のデータが格納されていることを確認しました。requestPayLoad部分に入力データ(Payload)、responsePayload部分にLambda関数の応答データが格納されていることを確認できました。
{
"version": "1.0",
"timestamp": "2019-12-06T17:54:12.711Z",
"requestContext": {
"requestId": "b980f302-eb3a-412d-9a43-bae6e8eba3ed",
"functionArn": "arn:aws:lambda:your-region:123456789012:function:QiitaSample:$LATEST",
"condition": "Success",
"approximateInvokeCount": 1
},
"requestPayload": {
"key1": "test"
},
"responseContext": {
"statusCode": 200,
"executedVersion": "$LATEST"
},
"responsePayload": "test"
}
では、エラーの場合はどうなるのでしょうか?現状、エラーの場合は前述したLambdaの仕様に基づいて、最大2回自動的にリトライがされ、それでも成功しなかった場合、デッドレターキューが構成されていれば、デッドレターキューに格納されます。余談ですが、Amazon SQSのデッドレターキューとは異なりますのでご注意ください。
ここでは、On failureのDestinationが未構成な場合と構成した場合のリトライの挙動を確認してみます。実際の確認方法はCloudWatch Logsのログで確認してみたいと思います。
以下をご覧いただくとわかるように、未構成の場合にエラーが発生した場合、2回リトライ処理が実行され処理が終了しています。(これ以降のログはなかったため2回で終了していると確認)。
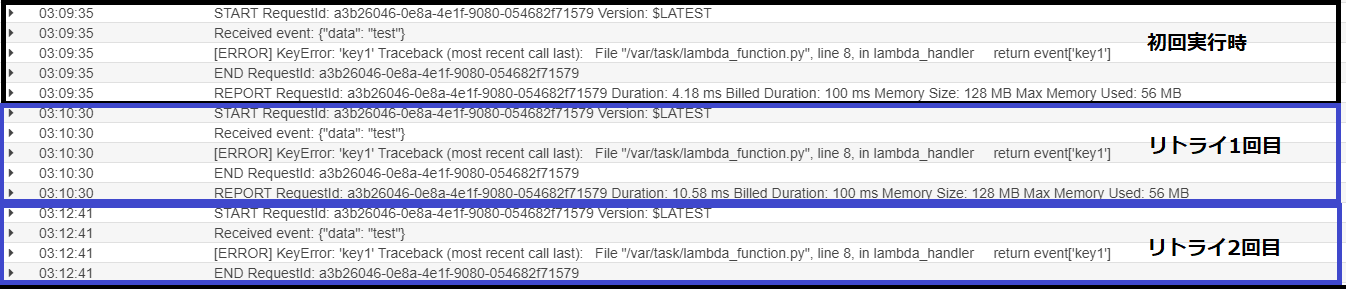 。現状、デッドレターキューをLambda関数にセットしていないためログ内に情報が格納されなません。今までであればログを解析して検出や後続処理の起動をする必要があり、手間がかかりました。
。現状、デッドレターキューをLambda関数にセットしていないためログ内に情報が格納されなません。今までであればログを解析して検出や後続処理の起動をする必要があり、手間がかかりました。
では動作を確認するためにOn failure時に先ほどOn Successで利用したキューとは別のQueue(QiitaFailureQueue)に情報を送るように設定してみたいと思います。先ほどと同様にDestinationとしてSQSを選択し、送信先のARNを以下の通り指定します。
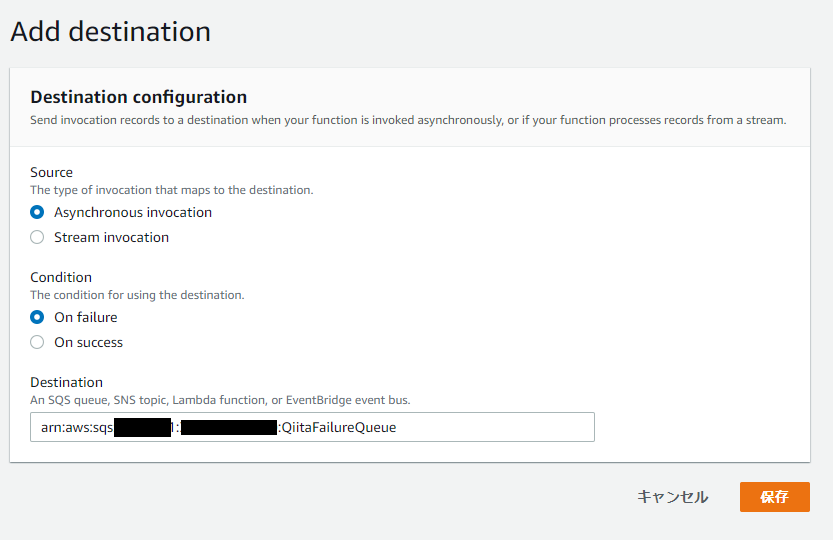
ここまで設定するとOn success, On failureそれぞれにSQSのQueueを紐づけているため以下の画面のAmazon SQS (2)の枠をクリックすると画面下部のAmazon SQSの欄で設定内容を見ることができます。
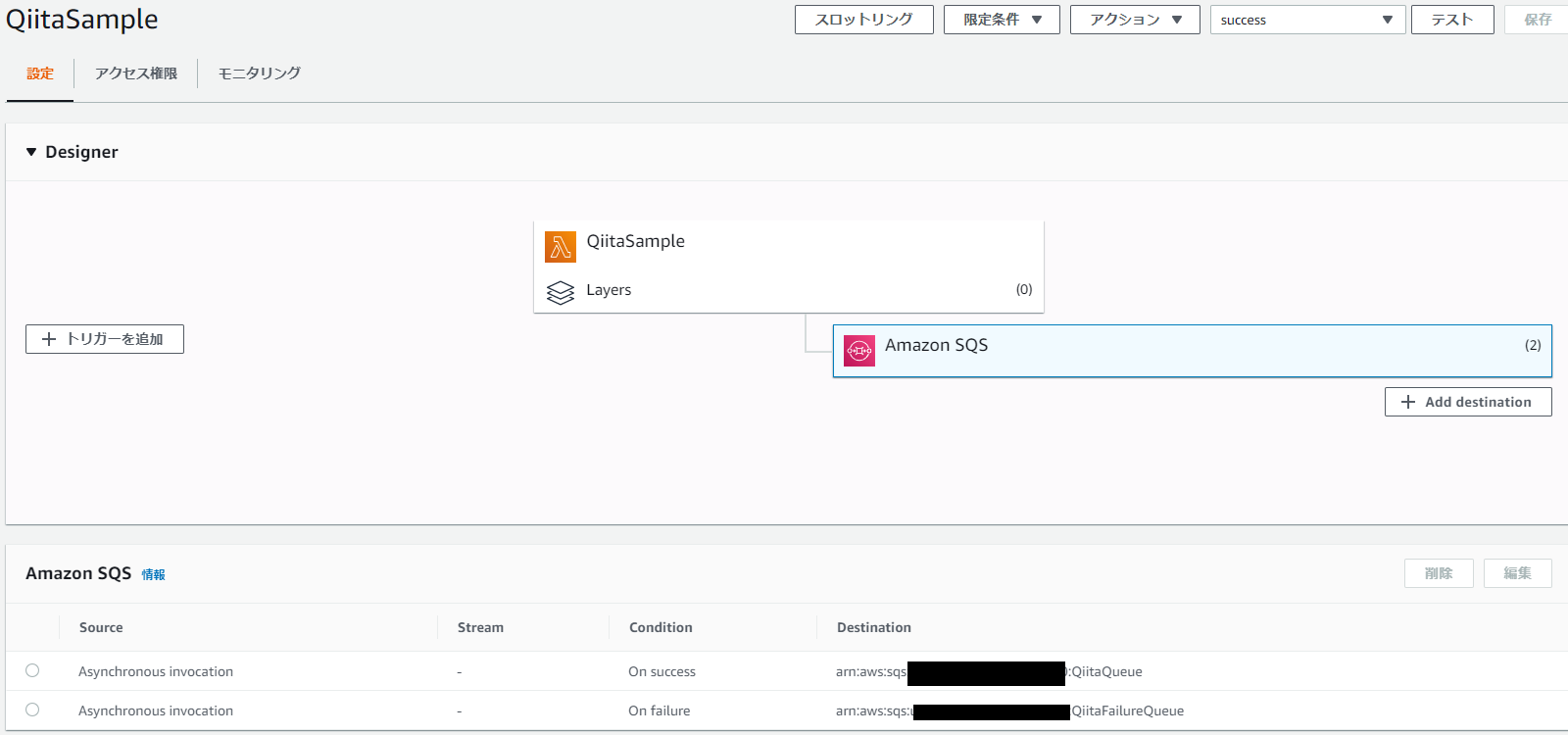
では、早速動かして結果を見てみましょう。実行方法、入力用データは前述の通りですので、結果をここでは紹介します。
まず、requestContext内のconditionには、RetriesExhaustedが設定されており、リトライ回数の上限を超えたことが分かります。また、その次の行ではapproximateInvokeCountも3となっており実行された回数が初回+リトライ2回の合計3回ということがここで分かります。「responsePayload」にはLambda関数が返したエラー内容が記されています。
{
"version": "1.0",
"timestamp": "2019-12-07T05:19:10.878Z",
"requestContext": {
"requestId": "ef39f86e-cd53-460b-b8f9-9668d81db50c",
"functionArn": "arn:aws:lambda:you-region:123456789012:function:QiitaSample:$LATEST",
"condition": "RetriesExhausted",
"approximateInvokeCount": 3
},
"requestPayload": {
"data": "test"
},
"responseContext": {
"statusCode": 200,
"executedVersion": "$LATEST",
"functionError": "Unhandled"
},
"responsePayload": {
"errorMessage": "'key1'",
"errorType": "KeyError",
"stackTrace": [
" File \"/var/task/lambda_function.py\", line 8, in lambda_handler\n return event['key1']\n"
]
}
}
ということで、非同期呼び出し時において、成功時も失敗時も指定したDestinationに送信できることが確認できました。ん??デッドレターキューはどういう扱いになるんだ?とここで疑問を持たれた方、私も同じ疑問を持ちました。じゃあ、ここでデッドレターキューを構成するパターンを整理して検証したいと思います。
| 構成方法 | パターン1 | パターン2 | パターン3 | パターン4 |
|---|---|---|---|---|
| Destination | 指定する | 指定する | 指定しない | 指定しない |
| デッドレターキュー | 指定しない | 指定する | 指定しない | 指定する |
先ほど試したパターンは上記のパターン1です。またパターン3,4は従来と同じですのでパターン2を構成したいと思います。構成は以下の通りデッドレターキューとしてQiitaDeadLetterQueueを指定しています。
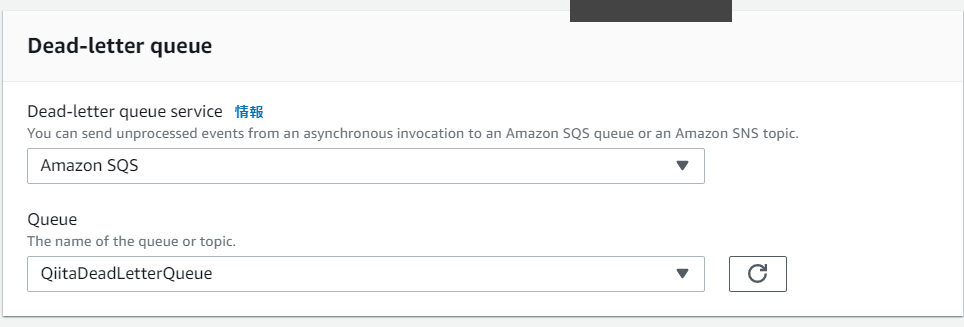
では、早速、挙動確認をしたいと思います。前述と同様のコマンド・データでエラーを起こしQueueの確認をしました。
まず、デッドレターキューを見てみると1件メッセージが入っていました。内容は次の通り、入力Payloadのみが格納されています。ただ、メッセージ属性には情報が格納されています。詳細はこちらをご確認ください
{"data":"test"}
では、次にOn Failureで指定したQueue(QiitaFailureQueue)の中を見たいと思います.
。こちらはデッドレターキューをしていない場合と同じです。
{
"version": "1.0",
"timestamp": "2019-12-07T05:59:52.617Z",
"requestContext": {
"requestId": "11cc11cf-2d46-421c-aa46-7802dd9ea598",
"functionArn": "arn:aws:lambda:your-region:123456789012:function:QiitaSample:$LATEST",
"condition": "RetriesExhausted",
"approximateInvokeCount": 3
},
"requestPayload": {
"data": "test"
},
"responseContext": {
"statusCode": 200,
"executedVersion": "$LATEST",
"functionError": "Unhandled"
},
"responsePayload": {
"errorMessage": "'key1'",
"errorType": "KeyError",
"stackTrace": [
" File \"/var/task/lambda_function.py\", line 8, in lambda_handler\n return event['key1']\n"
]
}
}
デッドレターキューもDestinationも併用可能ですが、個人的には、Destinationのほうが取り扱いしやすいのでは?と思っています。
ここまでをまとめると
- DestinationはLambda関数実行が正常終了した場合あるいは、異常終了した場合に事前にLamda関数に指定したDestinationに対して、Payload(入力情報)やコンテキスト、エラー情報等を送信することができる
- 2019/12/07時点では、4つのDestination(SQS/SNS/Lambda/EventBridge)がサポートされており、1つのLambda関数につき、On successで1つ、On failureで1つ設定ができる
- Lambda関数はDestinationにデータを書き込む権限を持っている必要がある
- Lambda関数のDeadLetterQueueに格納される内容よりDestinationのOn failureのほうが詳細な情報が格納されている
長くなりましたがDestinationに関する確認はここまでとします。
AWS Lambda Now Supports Maximum Event Age and Maximum Retry Attempts for Asynchronous Invocations の検証
では、ここからは、以下の記事に対する検証をしてみたいと思います。
AWS Lambda Now Supports Maximum Event Age and Maximum Retry Attempts for Asynchronous Invocations
実はここまでの検証で当記事で説明することはほぼ9割7分ほど終わっています。残りはMaxRetryAttenptsとMaxEventAgeですがMaxEventAgeは冒頭で記載した通り後日、別途、書きたいと思います(単に時間切れというだけ)
MaxRetryAttemptsですが、今まで非同期呼び出し時にLambda関数内でエラーが発生した場合、最大二回、自動的にリトライ処理が行われました。例えば、タイミングの問題等でエラーになってリトライする場合は有効ですが、何回実施してもエラーになるような処理の場合、繰り返しエラーが発生するだけですので、リトライをしたくないというワークロードもあるかと思います。当機能は現時点で0,1,2のいずれかの値を指定することができるため、自動リトライが不要であれば、0を指定することでリトライを回避できます。
では設定を見ていきましょう。以下の図にあるとおり、今回は0を指定しました。
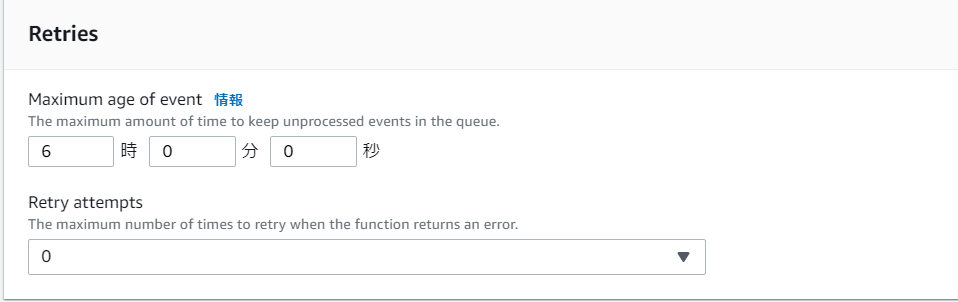
結果は次の通りです。MaxRetryを設定したことでrequestContext内のapproximateInvokeCountが1となっており実行された回数が初回のみということがここで分かります。
{
"version": "1.0",
"timestamp": "2019-12-07T04:54:56.479Z",
"requestContext": {
"requestId": "ab9038ce-13fc-47d9-8077-7f0b8f0cb663",
"functionArn": "arn:aws:lambda:your-region:123456789012:function:QiitaSample:$LATEST",
"condition": "RetriesExhausted",
"approximateInvokeCount": 1
},
"requestPayload": {
"data": "test"
},
"responseContext": {
"statusCode": 200,
"executedVersion": "$LATEST",
"functionError": "Unhandled"
},
"responsePayload": {
"errorMessage": "'key1'",
"errorType": "KeyError",
"stackTrace": [
" File \"/var/task/lambda_function.py\", line 8, in lambda_handler\n return event['key1']\n"
]
}
}
ということで今までは固定で2回実施されてリトライ処理が、0、あるいは、1回の指定に変更できるようになりました。
最後に
今回初めての投稿であり、読みづらい、分かりにくいという部分があるかもしれませんが、フィードバック等いただけると幸いです。